Synthetic Data Generation for Bridging Sim2Real Gap in a Production Environment
2311.11039
0
0
📊
Abstract
Synthetic data is being used lately for training deep neural networks in computer vision applications such as object detection, object segmentation and 6D object pose estimation. Domain randomization hereby plays an important role in reducing the simulation to reality gap. However, this generalization might not be effective in specialized domains like a production environment involving complex assemblies. Either the individual parts, trained with synthetic images, are integrated in much larger assemblies making them indistinguishable from their counterparts and result in false positives or are partially occluded just enough to give rise to false negatives. Domain knowledge is vital in these cases and if conceived effectively while generating synthetic data, can show a considerable improvement in bridging the simulation to reality gap. This paper focuses on synthetic data generation procedures for parts and assemblies used in a production environment. The basic procedures for synthetic data generation and their various combinations are evaluated and compared on images captured in a production environment, where results show up to 15% improvement using combinations of basic procedures. Reducing the simulation to reality gap in this way can aid to utilize the true potential of robot assisted production using artificial intelligence.
Create account to get full access
Overview
- Synthetic data is being used to train deep neural networks for computer vision tasks like object detection, segmentation, and 6D pose estimation
- Domain randomization helps bridge the gap between simulated and real-world data, but this generalization may not be effective in specialized production environments with complex assemblies
- The paper focuses on synthetic data generation procedures for parts and assemblies used in production environments, evaluating their impact on bridging the simulation-to-reality gap
Plain English Explanation
Synthetic, or computer-generated, data has become an important tool for training deep neural networks in computer vision applications such as detecting objects, segmenting objects, and estimating the 6D pose of objects. A key technique called domain randomization helps make the simulated data more representative of real-world conditions, reducing the gap between the synthetic and real data.
However, this generalization may not work as well in specialized production environments, where complex assemblies of parts are involved. When these individual parts, trained on synthetic data, are integrated into larger assemblies, they can become indistinguishable from their real-world counterparts, leading to false positives. Alternatively, the parts may become partially obscured, causing false negatives. In these cases, having domain knowledge - understanding the specific production environment - is crucial when generating the synthetic data to better bridge the simulation-to-reality gap.
This paper explores different procedures for creating synthetic data for parts and assemblies used in production environments. The researchers evaluate various combinations of these basic data generation techniques and find up to a 15% improvement in performance on real-world production images. Reducing the simulation-to-reality gap in this way can help unlock the full potential of using artificial intelligence to assist in robotic production.
Technical Explanation
The paper investigates synthetic data generation techniques for training deep neural networks in specialized production environments. Unlike general computer vision tasks, these environments involve complex assemblies of parts that can present challenges when using simulated data.
The researchers evaluate several basic procedures for synthetic data generation, as well as various combinations of these techniques. These procedures include things like generating diverse object poses, applying realistic occlusions, and introducing variations in lighting and background.
The experiments are conducted on images captured in a real production environment, and the researchers find that using combinations of the basic data generation procedures can lead to up to a 15% improvement in performance compared to individual techniques. This suggests that carefully crafting the synthetic data to match the specific characteristics of the production environment is crucial for bridging the simulation-to-reality gap in these specialized domains.
Critical Analysis
The paper provides a valuable contribution by exploring synthetic data generation techniques tailored to the unique challenges of production environments. The researchers acknowledge the limitations of general domain randomization approaches and highlight the importance of incorporating domain knowledge when creating synthetic training data.
One potential area for further research could be investigating more advanced techniques for modeling the complex occlusions and part-level interactions that occur in real-world assemblies. The paper focuses on basic occlusion patterns, but more sophisticated occlusion modeling may be needed to fully capture the complexity of production environments.
Additionally, the paper could have provided more detail on the specific production environment and the types of parts and assemblies involved. This contextual information would help readers better understand the significance of the research and its potential applicability to other production settings.
Overall, the paper demonstrates the value of carefully designing synthetic data generation procedures to address the unique challenges of specialized domains, and serves as a useful reference for researchers and practitioners working in the field of computer vision for industrial applications.
Conclusion
This research highlights the importance of incorporating domain knowledge when generating synthetic data for training deep neural networks in specialized production environments. While general domain randomization techniques can be effective for bridging the simulation-to-reality gap in many computer vision tasks, the authors show that more tailored data generation procedures are needed to account for the complex assemblies and occlusions found in real-world production settings.
By evaluating various combinations of basic synthetic data generation techniques, the researchers were able to achieve up to a 15% improvement in performance on real-world production images. This suggests that the careful design of synthetic data can significantly aid in unlocking the full potential of using artificial intelligence to assist in robotic production processes.
As the use of deep learning continues to expand in industrial applications, this work underscores the importance of understanding the unique challenges posed by specialized domains and developing synthetic data generation approaches that can effectively address them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
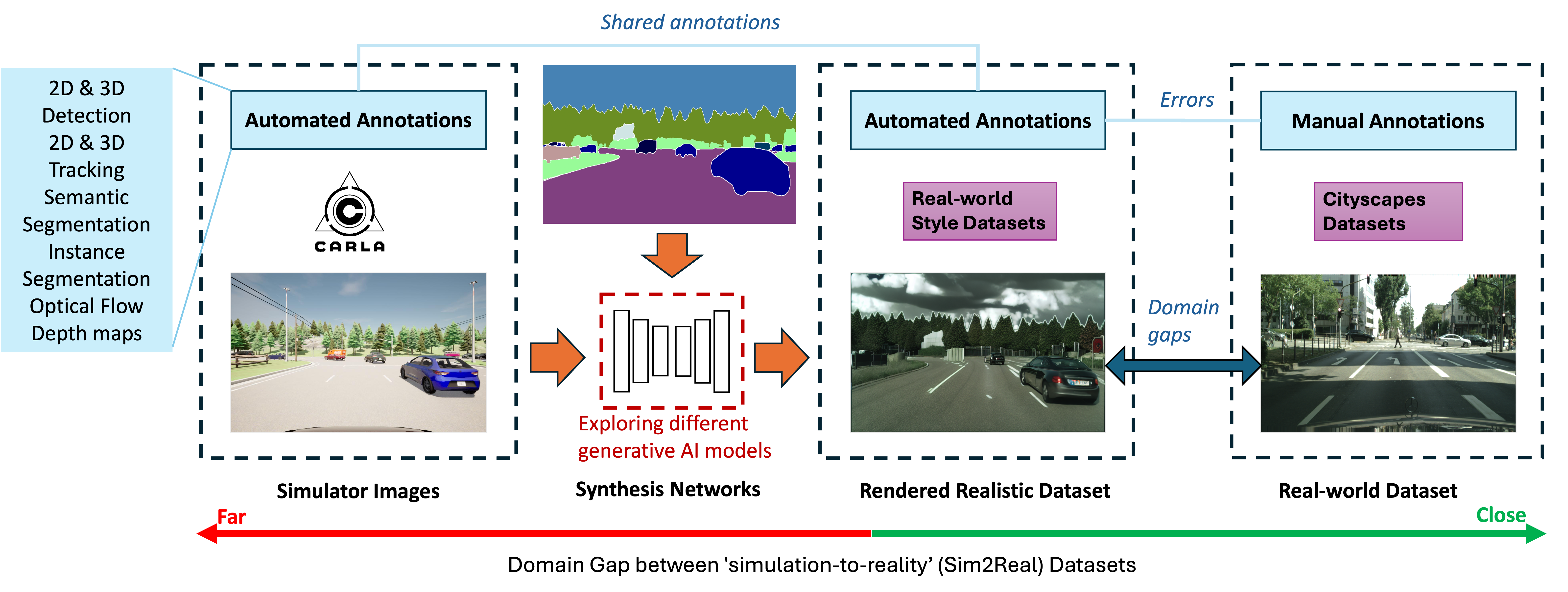
Exploring Generative AI for Sim2Real in Driving Data Synthesis
Haonan Zhao, Yiting Wang, Thomas Bashford-Rogers, Valentina Donzella, Kurt Debattista
0
0
Datasets are essential for training and testing vehicle perception algorithms. However, the collection and annotation of real-world images is time-consuming and expensive. Driving simulators offer a solution by automatically generating various driving scenarios with corresponding annotations, but the simulation-to-reality (Sim2Real) domain gap remains a challenge. While most of the Generative Artificial Intelligence (AI) follows the de facto Generative Adversarial Nets (GANs)-based methods, the recent emerging diffusion probabilistic models have not been fully explored in mitigating Sim2Real challenges for driving data synthesis. To explore the performance, this paper applied three different generative AI methods to leverage semantic label maps from a driving simulator as a bridge for the creation of realistic datasets. A comparative analysis of these methods is presented from the perspective of image quality and perception. New synthetic datasets, which include driving images and auto-generated high-quality annotations, are produced with low costs and high scene variability. The experimental results show that although GAN-based methods are adept at generating high-quality images when provided with manually annotated labels, ControlNet produces synthetic datasets with fewer artefacts and more structural fidelity when using simulator-generated labels. This suggests that the diffusion-based approach may provide improved stability and an alternative method for addressing Sim2Real challenges.
4/16/2024

Towards Sim-to-Real Industrial Parts Classification with Synthetic Dataset
Xiaomeng Zhu, Talha Bilal, Par M{aa}rtensson, Lars Hanson, M{aa}rten Bjorkman, Atsuto Maki
0
0
This paper is about effectively utilizing synthetic data for training deep neural networks for industrial parts classification, in particular, by taking into account the domain gap against real-world images. To this end, we introduce a synthetic dataset that may serve as a preliminary testbed for the Sim-to-Real challenge; it contains 17 objects of six industrial use cases, including isolated and assembled parts. A few subsets of objects exhibit large similarities in shape and albedo for reflecting challenging cases of industrial parts. All the sample images come with and without random backgrounds and post-processing for evaluating the importance of domain randomization. We call it Synthetic Industrial Parts dataset (SIP-17). We study the usefulness of SIP-17 through benchmarking the performance of five state-of-the-art deep network models, supervised and self-supervised, trained only on the synthetic data while testing them on real data. By analyzing the results, we deduce some insights on the feasibility and challenges of using synthetic data for industrial parts classification and for further developing larger-scale synthetic datasets. Our dataset and code are publicly available.
4/16/2024
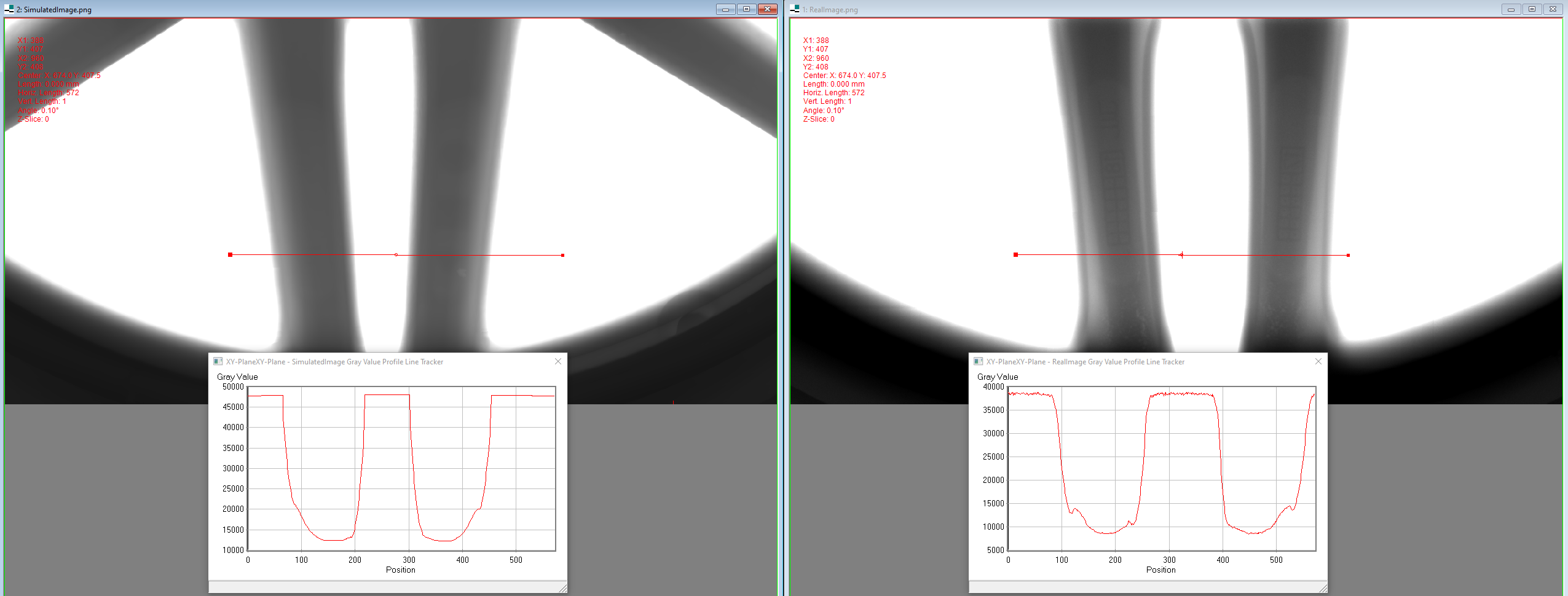
Towards Reducing Data Acquisition and Labeling for Defect Detection using Simulated Data
Lukas Malte Kemeter, Rasmus Hvingelby, Paulina Sierak, Tobias Schon, Bishwajit Gosswam
0
0
In many manufacturing settings, annotating data for machine learning and computer vision is costly, but synthetic data can be generated at significantly lower cost. Substituting the real-world data with synthetic data is therefore appealing for many machine learning applications that require large amounts of training data. However, relying solely on synthetic data is frequently inadequate for effectively training models that perform well on real-world data, primarily due to domain shifts between the synthetic and real-world data. We discuss approaches for dealing with such a domain shift when detecting defects in X-ray scans of aluminium wheels. Using both simulated and real-world X-ray images, we train an object detection model with different strategies to identify the training approach that generates the best detection results while minimising the demand for annotated real-world training samples. Our preliminary findings suggest that the sim-2-real domain adaptation approach is more cost-efficient than a fully supervised oracle - if the total number of available annotated samples is fixed. Given a certain number of labeled real-world samples, training on a mix of synthetic and unlabeled real-world data achieved comparable or even better detection results at significantly lower cost. We argue that future research into the cost-efficiency of different training strategies is important for a better understanding of how to allocate budget in applied machine learning projects.
6/28/2024

Exploring the Impact of Synthetic Data for Aerial-view Human Detection
Hyungtae Lee, Yan Zhang, Yi-Ting Shen, Heesung Kwon, Shuvra S. Bhattacharyya
0
0
Aerial-view human detection has a large demand for large-scale data to capture more diverse human appearances compared to ground-view human detection. Therefore, synthetic data can be a good resource to expand data, but the domain gap with real-world data is the biggest obstacle to its use in training. As a common solution to deal with the domain gap, the sim2real transformation is used, and its quality is affected by three factors: i) the real data serving as a reference when calculating the domain gap, ii) the synthetic data chosen to avoid the transformation quality degradation, and iii) the synthetic data pool from which the synthetic data is selected. In this paper, we investigate the impact of these factors on maximizing the effectiveness of synthetic data in training in terms of improving learning performance and acquiring domain generalization ability--two main benefits expected of using synthetic data. As an evaluation metric for the second benefit, we introduce a method for measuring the distribution gap between two datasets, which is derived as the normalized sum of the Mahalanobis distances of all test data. As a result, we have discovered several important findings that have never been investigated or have been used previously without accurate understanding. We expect that these findings can break the current trend of either naively using or being hesitant to use synthetic data in machine learning due to the lack of understanding, leading to more appropriate use in future research.
5/28/2024