Could We Have Had Better Multilingual LLMs If English Was Not the Central Language?

0
Sign in to get full access
Overview
- The paper investigates the importance of linguistic features and languages in large language model (LLM) translation.
- It explores the impact of various linguistic factors, such as language similarity, on the performance of LLM-based translation systems.
- The research aims to provide insights into the key linguistic features and languages that are critical for effective LLM-powered translation.
Plain English Explanation
The paper examines how the linguistic characteristics and the specific languages involved can affect the performance of translation systems that use large language models (LLMs). LLMs are powerful AI models that can understand and generate human language. The researchers wanted to understand which linguistic factors, such as how similar two languages are, are most important for these LLM-based translation systems to work well.
By understanding the linguistic features and languages that are critical for effective LLM translation, the research could help guide the development of better translation systems and enable the expansion of LLMs to handle more languages. This could lead to improved cross-lingual communication and understanding, with applications in areas like teaching LLMs new languages and transforming LLMs into cross-modal, cross-lingual systems.
Technical Explanation
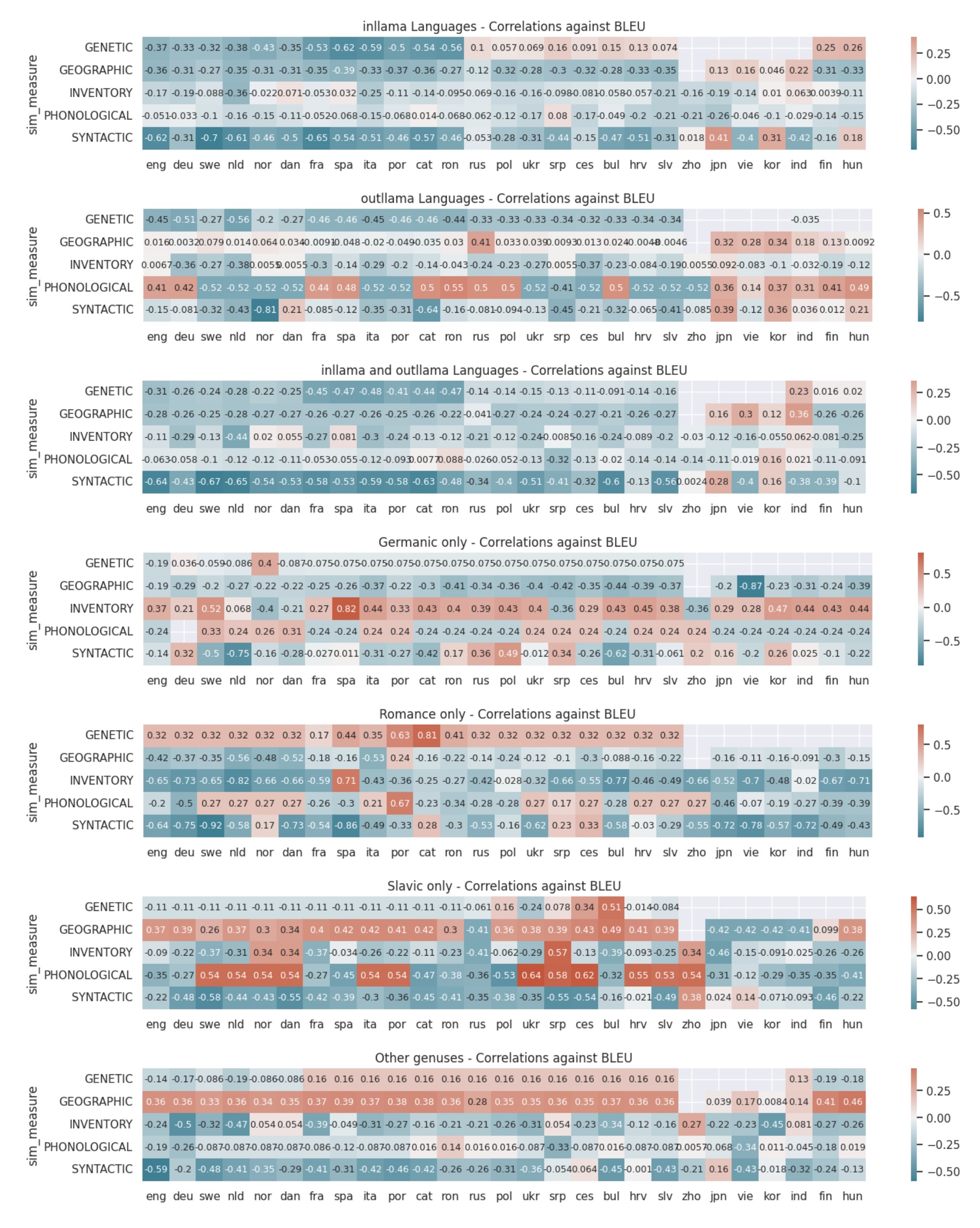
The paper first evaluates different metrics for measuring language similarity, as this is a key factor in LLM translation performance. The researchers compare various approaches, including lexical, syntactic, and semantic similarity measures, to determine which ones best correlate with actual translation quality.
The main experiment then investigates how different linguistic features, such as word order, case systems, and morphological complexity, impact the performance of an LLM-based translation model. The team tests this across a diverse set of language pairs, including those with varying degrees of similarity.
The results provide insights into the linguistic characteristics that are most important for effective LLM translation. For example, the paper finds that languages with similar word order and case systems tend to be easier for LLMs to translate between, while morphologically complex languages present greater challenges.
Critical Analysis
The paper acknowledges that the study is limited to a specific set of language pairs and LLM architectures, and that further research is needed to generalize the findings. Additionally, the metrics used to evaluate language similarity may not capture all the nuances that influence translation quality.
While the research provides valuable insights, it would be helpful to see the impact of other factors, such as the availability of training data and the specific techniques used to fine-tune the LLMs for translation. Exploring the performance of LLM-based translation on low-resource languages could also yield important insights.
Overall, the paper makes a significant contribution to understanding the linguistic considerations in LLM-powered translation. By highlighting the importance of language-specific factors, it can inform the development of more robust and versatile translation systems.
Conclusion
This research investigates the critical role of linguistic features and languages in the performance of large language model (LLM) translation systems. The findings provide valuable insights into the key factors that influence translation quality, such as language similarity and morphological complexity.
By understanding these linguistic considerations, the research can guide the development of more effective LLM-based translation systems. This, in turn, can lead to improved cross-lingual communication and the expansion of LLMs to handle a wider range of languages, with applications in areas like cross-lingual knowledge sharing and multilingual user interfaces.
The paper lays the groundwork for further exploration of the linguistic challenges and opportunities in LLM translation, paving the way for more robust and versatile language models that can bridge communication gaps across the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Could We Have Had Better Multilingual LLMs If English Was Not the Central Language?
Ryandito Diandaru, Lucky Susanto, Zilu Tang, Ayu Purwarianti, Derry Wijaya
Large Language Models (LLMs) demonstrate strong machine translation capabilities on languages they are trained on. However, the impact of factors beyond training data size on translation performance remains a topic of debate, especially concerning languages not directly encountered during training. Our study delves into Llama2's translation capabilities. By modeling a linear relationship between linguistic feature distances and machine translation scores, we ask ourselves if there are potentially better central languages for LLMs other than English. Our experiments show that the 7B Llama2 model yields above 10 BLEU when translating into all languages it has seen, which rarely happens for languages it has not seen. Most translation improvements into unseen languages come from scaling up the model size rather than instruction tuning or increasing shot count. Furthermore, our correlation analysis reveals that syntactic similarity is not the only linguistic factor that strongly correlates with machine translation scores. Interestingly, we discovered that under specific circumstances, some languages (e.g. Swedish, Catalan), despite having significantly less training data, exhibit comparable correlation levels to English. These insights challenge the prevailing landscape of LLMs, suggesting that models centered around languages other than English could provide a more efficient foundation for multilingual applications.
Read more4/8/2024
0
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, Lidong Bing
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
Read more6/21/2024
💬
0
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
Read more6/17/2024
💬
0
Large Language Models are Good Spontaneous Multilingual Learners: Is the Multilingual Annotated Data Necessary?
Shimao Zhang, Changjiang Gao, Wenhao Zhu, Jiajun Chen, Xin Huang, Xue Han, Junlan Feng, Chao Deng, Shujian Huang
Recently, Large Language Models (LLMs) have shown impressive language capabilities. While most of the existing LLMs have very unbalanced performance across different languages, multilingual alignment based on translation parallel data is an effective method to enhance the LLMs' multilingual capabilities. In this work, we discover and comprehensively investigate the spontaneous multilingual alignment improvement of LLMs. We find that LLMs instruction-tuned on the question translation data (i.e. without annotated answers) are able to encourage the alignment between English and a wide range of languages, even including those unseen during instruction-tuning. Additionally, we utilize different settings and mechanistic interpretability methods to analyze the LLM's performance in the multilingual scenario comprehensively. Our work suggests that LLMs have enormous potential for improving multilingual alignment efficiently with great language and task generalization.
Read more6/19/2024