Large Language Models are Good Spontaneous Multilingual Learners: Is the Multilingual Annotated Data Necessary?
2405.13816
0
0
💬
Abstract
Recently, Large Language Models (LLMs) have shown impressive language capabilities. While most of the existing LLMs have very unbalanced performance across different languages, multilingual alignment based on translation parallel data is an effective method to enhance the LLMs' multilingual capabilities. In this work, we discover and comprehensively investigate the spontaneous multilingual alignment improvement of LLMs. We find that LLMs instruction-tuned on the question translation data (i.e. without annotated answers) are able to encourage the alignment between English and a wide range of languages, even including those unseen during instruction-tuning. Additionally, we utilize different settings and mechanistic interpretability methods to analyze the LLM's performance in the multilingual scenario comprehensively. Our work suggests that LLMs have enormous potential for improving multilingual alignment efficiently with great language and task generalization.
Create account to get full access
Overview
- Large Language Models (LLMs) have shown impressive language capabilities, but most are English-centric and have unbalanced performance across different languages.
- Multilingual alignment is an effective method to enhance LLMs' multilingual capabilities.
- This work explores the multilingual alignment paradigm and investigates the spontaneous multilingual improvement of LLMs.
Plain English Explanation
Large Language Models (LLMs) are AI systems that can understand and generate human-like text. While these models have become highly skilled at tasks like answering questions and generating text, most of them are primarily focused on the English language. This means their performance can be quite uneven when it comes to other languages.
Multilingual alignment is a technique that can help improve an LLM's ability to work with multiple languages. The idea is to use translation data to "align" the model's understanding so that it performs well across a wider range of languages, not just English.
This research explores this multilingual alignment approach in depth. The researchers found that LLMs that were trained just on translating questions, without being shown the actual answers, were still able to significantly improve their performance across a wide variety of languages, even ones they hadn't seen during training. The researchers also used different analysis methods to better understand how these multilingual LLMs work.
Technical Explanation
This paper investigates the spontaneous multilingual improvement of LLMs through the multilingual alignment paradigm. The key findings are:
- LLMs trained only on question translation data, without annotated answers, can achieve significant multilingual performance enhancement across a wide range of languages, including those unseen during training.
- Different settings and mechanistic interpretability methods are utilized to comprehensively analyze the LLM's multilingual capabilities.
The researchers explore how this multilingual alignment technique can boost an LLM's ability to work with multiple languages, without requiring extensive training on each individual language. This could help make these powerful language models more accessible and useful in a wider range of real-world applications.
Critical Analysis
The paper presents a promising approach for improving the multilingual capabilities of LLMs. However, it's important to note that the researchers only evaluated the models on a limited set of benchmark tasks. More research is needed to understand how these multilingual LLMs would perform on a wider range of real-world language tasks, especially in spoken language understanding.
Additionally, the paper does not delve into potential biases or limitations that may arise from the translation data used for training. Further investigation is needed to ensure these multilingual LLMs do not perpetuate or amplify existing language biases.
Overall, this work represents an important step forward in developing more capable and inclusive language models, but there is still room for improvement and further research.
Conclusion
This research demonstrates a promising approach for enhancing the multilingual capabilities of Large Language Models. By leveraging translation data through the multilingual alignment paradigm, the researchers were able to achieve significant performance improvements across a wide range of languages, including those unseen during training.
These findings suggest that LLMs can be made more accessible and useful in diverse global contexts, beyond just the English-speaking world. As these models continue to advance, it will be crucial to prioritize multilingual development to ensure equitable access to these powerful language technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, Lidong Bing
0
0
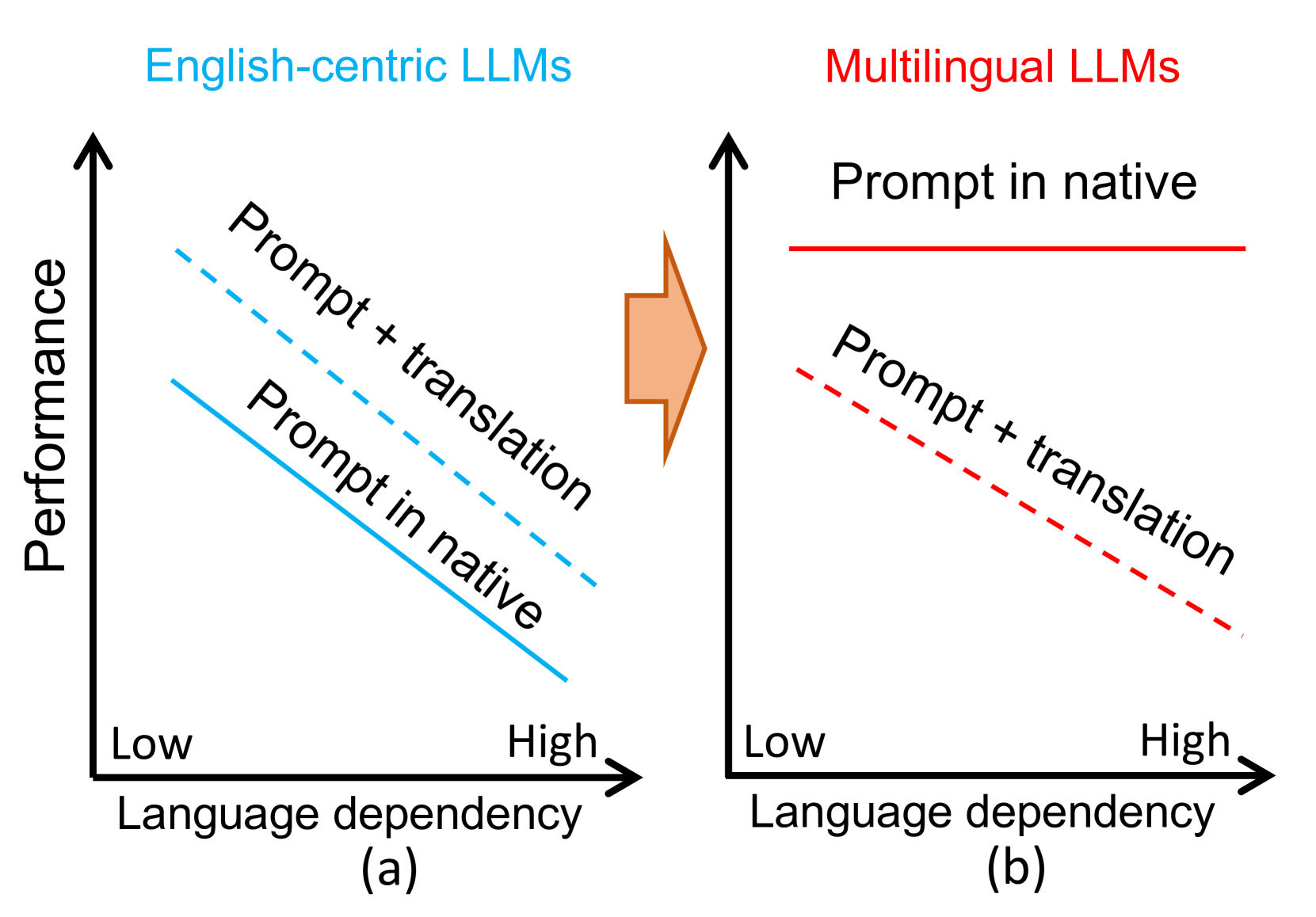
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
6/21/2024
A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias
Yuemei Xu, Ling Hu, Jiayi Zhao, Zihan Qiu, Yuqi Ye, Hanwen Gu
0
0
Based on the foundation of Large Language Models (LLMs), Multilingual Large Language Models (MLLMs) have been developed to address the challenges of multilingual natural language processing tasks, hoping to achieve knowledge transfer from high-resource to low-resource languages. However, significant limitations and challenges still exist, such as language imbalance, multilingual alignment, and inherent bias. In this paper, we aim to provide a comprehensive analysis of MLLMs, delving deeply into discussions surrounding these critical issues. First of all, we start by presenting an overview of MLLMs, covering their evolution, key techniques, and multilingual capacities. Secondly, we explore widely utilized multilingual corpora for MLLMs' training and multilingual datasets oriented for downstream tasks that are crucial for enhancing the cross-lingual capability of MLLMs. Thirdly, we survey the existing studies on multilingual representations and investigate whether the current MLLMs can learn a universal language representation. Fourthly, we discuss bias on MLLMs including its category and evaluation metrics, and summarize the existing debiasing techniques. Finally, we discuss existing challenges and point out promising research directions. By demonstrating these aspects, this paper aims to facilitate a deeper understanding of MLLMs and their potentiality in various domains.
6/7/2024
Could We Have Had Better Multilingual LLMs If English Was Not the Central Language?
Ryandito Diandaru, Lucky Susanto, Zilu Tang, Ayu Purwarianti, Derry Wijaya
0
0
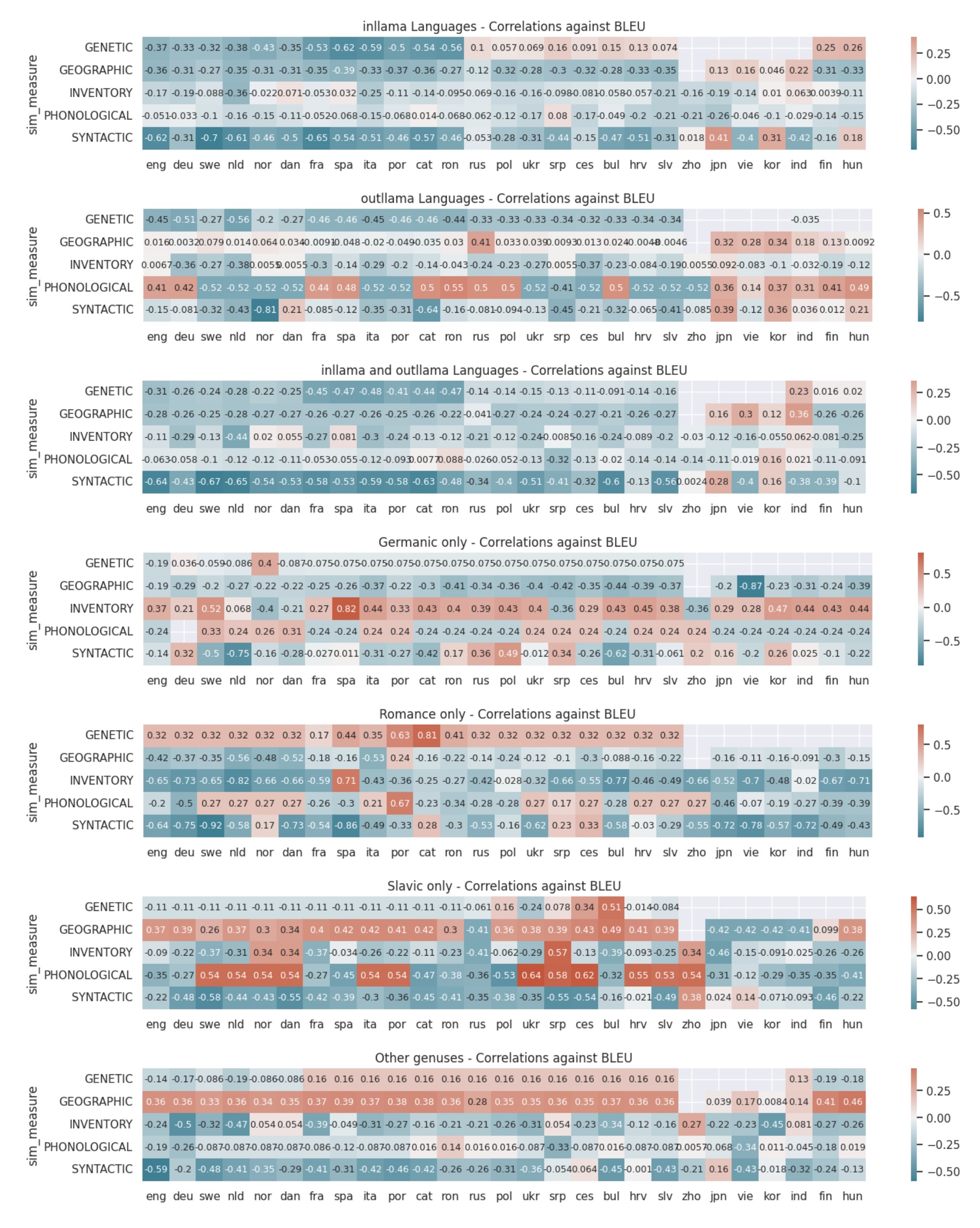
Large Language Models (LLMs) demonstrate strong machine translation capabilities on languages they are trained on. However, the impact of factors beyond training data size on translation performance remains a topic of debate, especially concerning languages not directly encountered during training. Our study delves into Llama2's translation capabilities. By modeling a linear relationship between linguistic feature distances and machine translation scores, we ask ourselves if there are potentially better central languages for LLMs other than English. Our experiments show that the 7B Llama2 model yields above 10 BLEU when translating into all languages it has seen, which rarely happens for languages it has not seen. Most translation improvements into unseen languages come from scaling up the model size rather than instruction tuning or increasing shot count. Furthermore, our correlation analysis reveals that syntactic similarity is not the only linguistic factor that strongly correlates with machine translation scores. Interestingly, we discovered that under specific circumstances, some languages (e.g. Swedish, Catalan), despite having significantly less training data, exhibit comparable correlation levels to English. These insights challenge the prevailing landscape of LLMs, suggesting that models centered around languages other than English could provide a more efficient foundation for multilingual applications.
4/8/2024
💬
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
0
0
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
6/17/2024