Safe Deep Policy Adaptation

0
Sign in to get full access
Overview
- This paper proposes a method for safely adapting deep reinforcement learning policies to new environments or tasks.
- The key idea is to leverage a "safety critic" that can assess the safety of a policy and guide the adaptation process to ensure the learned policy remains safe.
- The method is demonstrated on several robotic control tasks, showing it can effectively adapt policies while maintaining safety guarantees.
Plain English Explanation
The paper discusses a technique for safe deep policy adaptation - how to modify or "adapt" a deep reinforcement learning policy to work in a new environment or scenario, while ensuring the adapted policy remains safe.
The core innovation is the use of a "safety critic" - an additional neural network that can evaluate how safe a policy is, based on factors like avoiding collisions or staying within specified limits. This safety critic guides the adaptation process, ensuring the new policy maintains the desired level of safety, even as it is optimized to perform well in the new setting.
The researchers test this approach on several robotic control tasks, showing that it can successfully adapt policies while reliably maintaining safety. This is an important capability, as it allows AI systems to be safely deployed in new and changing real-world environments.
Technical Explanation
The paper proposes a safe deep policy adaptation framework that can modify a deep reinforcement learning policy to perform well in a new environment or task, while ensuring the adapted policy remains within specified safety constraints.
The key component is a "safety critic" network that is trained to assess the safety of a given policy. This safety critic is used to guide the adaptation process, ensuring that modifications to the policy maintain the desired level of safety. Specifically, the adaptation objective optimizes both the policy's performance and the safety critic's assessment of the policy's safety.
The authors evaluate their approach on several simulated robotic control tasks, including manipulator arms and legged robots. They show that the safe adaptation framework can effectively transfer policies to new scenarios while ensuring safety constraints are upheld. This represents an important advance in the field of safe reinforcement learning, enabling AI systems to be deployed in the real world with strong safety guarantees.
Critical Analysis
The paper presents a compelling approach for safely adapting deep reinforcement learning policies. The use of a dedicated safety critic is a clever way to incorporate safety considerations directly into the adaptation process.
However, the paper does acknowledge some limitations. The technique relies on having access to a simulator that can accurately model the safety constraints of the new environment. Transferring the approach to the real world may require additional steps to handle modeling errors and unforeseen events.
Additionally, the paper focuses on safety constraints defined by simple geometric boundaries or collision avoidance. More complex safety requirements, such as maintaining stable locomotion or avoiding dangerous states, may require further extensions to the safety critic design.
Overall, this work represents an important step forward in safe reinforcement learning and adaptive control. Continued research in this direction could lead to AI systems that can be reliably deployed in a wide range of real-world applications.
Conclusion
The proposed safe deep policy adaptation framework offers a principled approach to modifying deep reinforcement learning policies for new environments or tasks, while maintaining strong safety guarantees. By incorporating a dedicated safety critic into the adaptation process, the method can reliably ensure that the learned policies adhere to specified safety constraints.
This work represents an important advancement in the field of safe reinforcement learning and has the potential to enable AI systems to be deployed in a wide range of real-world applications that require high levels of safety and reliability. As the authors note, further research is needed to expand the scope of safety considerations and improve the robustness of the approach, but this paper lays the groundwork for a promising direction in adaptive and safe control systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Safe Deep Policy Adaptation
Wenli Xiao, Tairan He, John Dolan, Guanya Shi
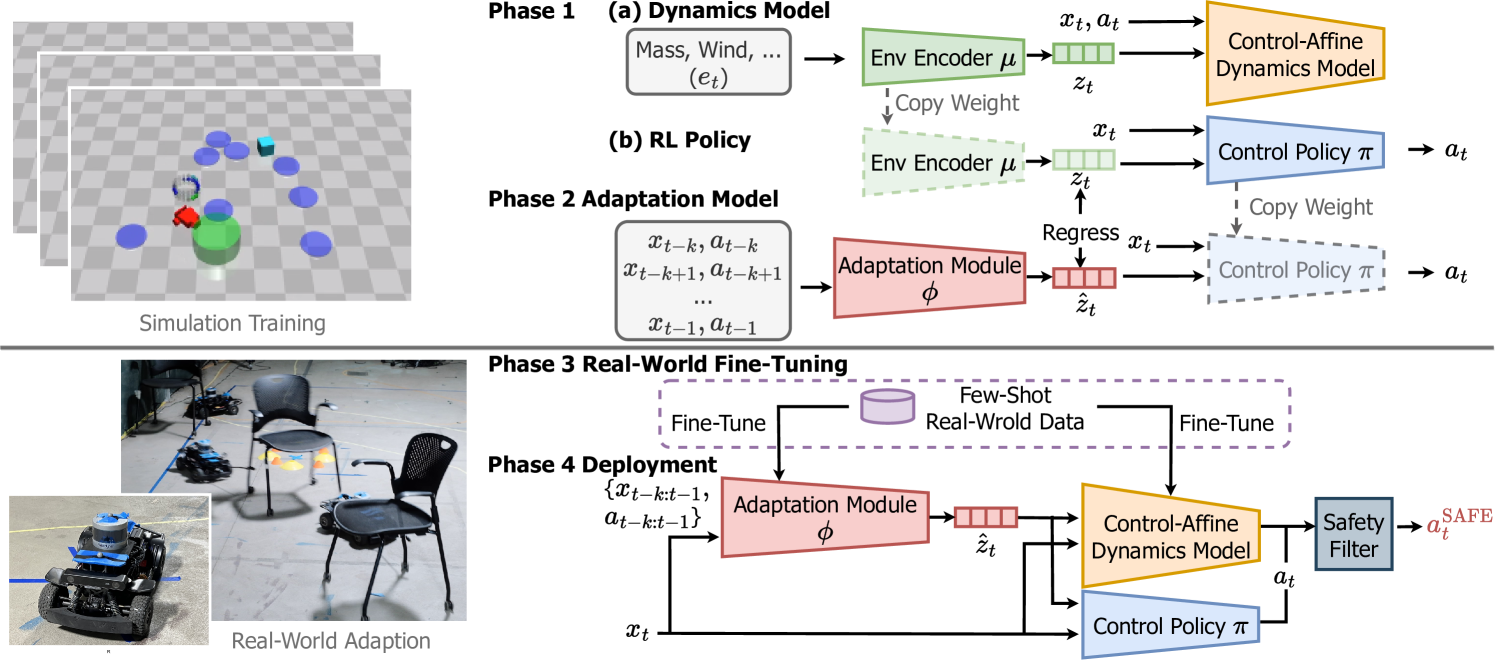
A critical goal of autonomy and artificial intelligence is enabling autonomous robots to rapidly adapt in dynamic and uncertain environments. Classic adaptive control and safe control provide stability and safety guarantees but are limited to specific system classes. In contrast, policy adaptation based on reinforcement learning (RL) offers versatility and generalizability but presents safety and robustness challenges. We propose SafeDPA, a novel RL and control framework that simultaneously tackles the problems of policy adaptation and safe reinforcement learning. SafeDPA jointly learns adaptive policy and dynamics models in simulation, predicts environment configurations, and fine-tunes dynamics models with few-shot real-world data. A safety filter based on the Control Barrier Function (CBF) on top of the RL policy is introduced to ensure safety during real-world deployment. We provide theoretical safety guarantees of SafeDPA and show the robustness of SafeDPA against learning errors and extra perturbations. Comprehensive experiments on (1) classic control problems (Inverted Pendulum), (2) simulation benchmarks (Safety Gym), and (3) a real-world agile robotics platform (RC Car) demonstrate great superiority of SafeDPA in both safety and task performance, over state-of-the-art baselines. Particularly, SafeDPA demonstrates notable generalizability, achieving a 300% increase in safety rate compared to the baselines, under unseen disturbances in real-world experiments.
Read more4/30/2024
🚀
0
ISAACS: Iterative Soft Adversarial Actor-Critic for Safety
Kai-Chieh Hsu, Duy Phuong Nguyen, Jaime Fern'andez Fisac
The deployment of robots in uncontrolled environments requires them to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions. Unfortunately, while rigorous safety frameworks from robust optimal control theory scale poorly to high-dimensional nonlinear dynamics, control policies computed by more tractable deep methods lack guarantees and tend to exhibit little robustness to uncertain operating conditions. This work introduces a novel approach enabling scalable synthesis of robust safety-preserving controllers for robotic systems with general nonlinear dynamics subject to bounded modeling error by combining game-theoretic safety analysis with adversarial reinforcement learning in simulation. Following a soft actor-critic scheme, a safety-seeking fallback policy is co-trained with an adversarial disturbance agent that aims to invoke the worst-case realization of model error and training-to-deployment discrepancy allowed by the designer's uncertainty. While the learned control policy does not intrinsically guarantee safety, it is used to construct a real-time safety filter (or shield) with robust safety guarantees based on forward reachability rollouts. This shield can be used in conjunction with a safety-agnostic control policy, precluding any task-driven actions that could result in loss of safety. We evaluate our learning-based safety approach in a 5D race car simulator, compare the learned safety policy to the numerically obtained optimal solution, and empirically validate the robust safety guarantee of our proposed safety shield against worst-case model discrepancy.
Read more6/11/2024
🏅
0
Safe Reinforcement Learning in Black-Box Environments via Adaptive Shielding
Daniel Bethell, Simos Gerasimou, Radu Calinescu, Calum Imrie
Empowering safe exploration of reinforcement learning (RL) agents during training is a critical impediment towards deploying RL agents in many real-world scenarios. Training RL agents in unknown, black-box environments poses an even greater safety risk when prior knowledge of the domain/task is unavailable. We introduce ADVICE (Adaptive Shielding with a Contrastive Autoencoder), a novel post-shielding technique that distinguishes safe and unsafe features of state-action pairs during training, thus protecting the RL agent from executing actions that yield potentially hazardous outcomes. Our comprehensive experimental evaluation against state-of-the-art safe RL exploration techniques demonstrates how ADVICE can significantly reduce safety violations during training while maintaining a competitive outcome reward.
Read more5/29/2024
🏅
0
Reducing Risk for Assistive Reinforcement Learning Policies with Diffusion Models
Andrii Tytarenko
Care-giving and assistive robotics, driven by advancements in AI, offer promising solutions to meet the growing demand for care, particularly in the context of increasing numbers of individuals requiring assistance. This creates a pressing need for efficient and safe assistive devices, particularly in light of heightened demand due to war-related injuries. While cost has been a barrier to accessibility, technological progress is able to democratize these solutions. Safety remains a paramount concern, especially given the intricate interactions between assistive robots and humans. This study explores the application of reinforcement learning (RL) and imitation learning, in improving policy design for assistive robots. The proposed approach makes the risky policies safer without additional environmental interactions. Through experimentation using simulated environments, the enhancement of the conventional RL approaches in tasks related to assistive robotics is demonstrated.
Read more5/14/2024