iSEARLE: Improving Textual Inversion for Zero-Shot Composed Image Retrieval
2405.02951
0
0
Abstract
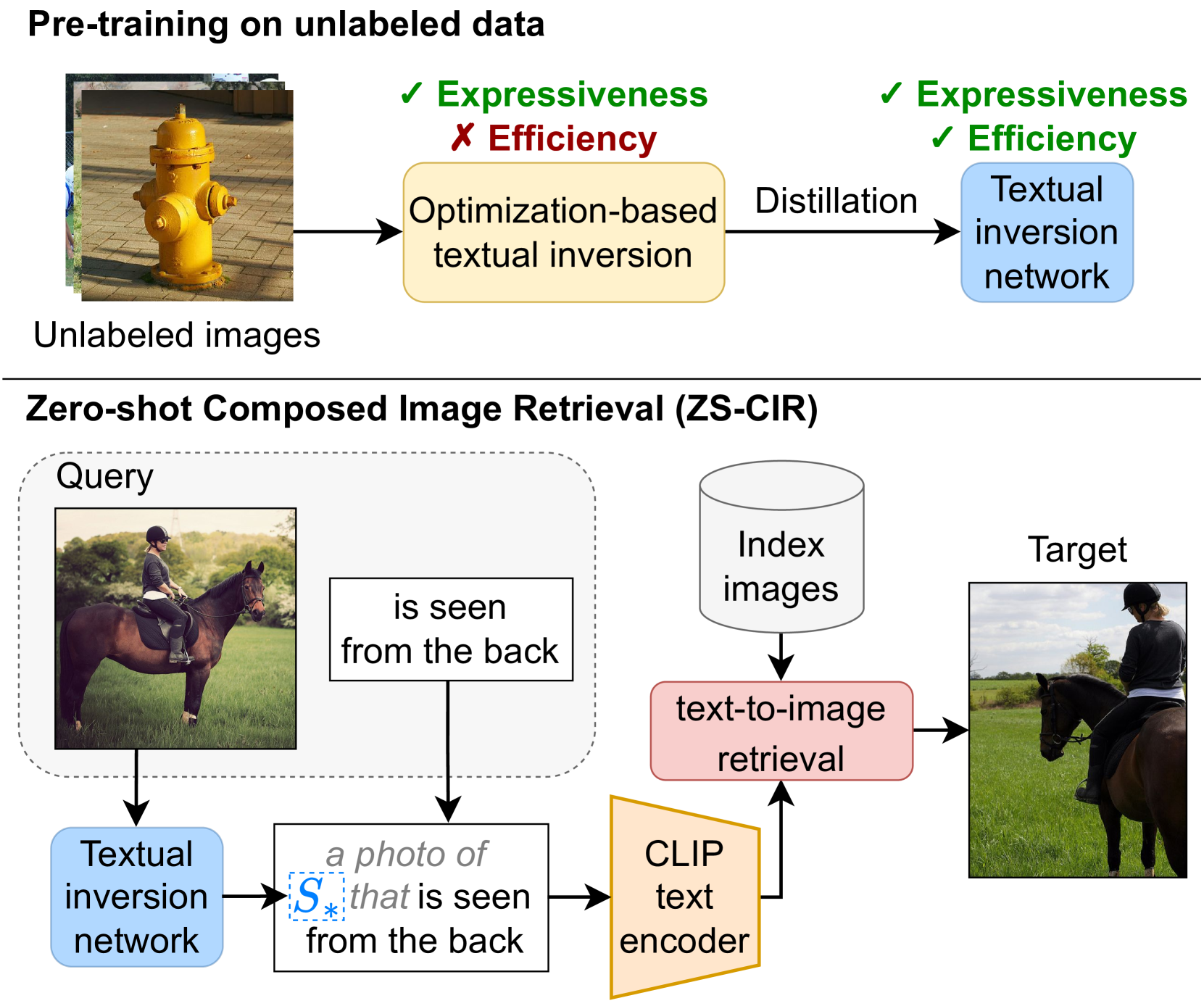
Given a query consisting of a reference image and a relative caption, Composed Image Retrieval (CIR) aims to retrieve target images visually similar to the reference one while incorporating the changes specified in the relative caption. The reliance of supervised methods on labor-intensive manually labeled datasets hinders their broad applicability. In this work, we introduce a new task, Zero-Shot CIR (ZS-CIR), that addresses CIR without the need for a labeled training dataset. We propose an approach named iSEARLE (improved zero-Shot composEd imAge Retrieval with textuaL invErsion) that involves mapping the visual information of the reference image into a pseudo-word token in CLIP token embedding space and combining it with the relative caption. To foster research on ZS-CIR, we present an open-domain benchmarking dataset named CIRCO (Composed Image Retrieval on Common Objects in context), the first CIR dataset where each query is labeled with multiple ground truths and a semantic categorization. The experimental results illustrate that iSEARLE obtains state-of-the-art performance on three different CIR datasets -- FashionIQ, CIRR, and the proposed CIRCO -- and two additional evaluation settings, namely domain conversion and object composition. The dataset, the code, and the model are publicly available at https://github.com/miccunifi/SEARLE.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces iSEARLE, an approach that improves Textual Inversion for zero-shot composed image retrieval.
- Textual Inversion is a technique that allows text to be used to generate or edit images, but it has limitations in its ability to handle complex compositions.
- iSEARLE aims to address these limitations by introducing a novel training process and architectural changes to the Textual Inversion model.
Plain English Explanation
The paper presents a new method called iSEARLE that enhances the ability of Textual Inversion to retrieve images that are composed of multiple elements. Textual Inversion is a technique that enables text to be used to generate or modify images, but it struggles when the images involve complex combinations of objects, scenes, or other visual elements.
To overcome this, the researchers developed iSEARLE, which includes changes to the training process and the model architecture. These improvements allow the Textual Inversion model to better understand and represent the relationships between different visual elements, making it more effective at retrieving images that match complex textual descriptions.
For example, with regular Textual Inversion, it might be difficult to retrieve an image of "a dog playing fetch in a park" because the model doesn't fully grasp how a dog, a ball, and a park scene all fit together. But iSEARLE's enhancements enable the model to better capture those intricate compositional relationships, making it better at finding appropriate images for such complex queries.
Technical Explanation
The paper introduces iSEARLE, a method that improves Textual Inversion for zero-shot composed image retrieval. Textual Inversion is a technique that allows text to be used for image generation and editing, but it struggles with complex visual compositions involving multiple elements.
To address these limitations, the researchers propose several key innovations in iSEARLE:
-
Compositional Training: The model is trained on a dataset of composed images, where each image contains multiple visual elements. This helps the model learn how to represent and reason about the relationships between different visual components.
-
Multimodal Prompt Engineering: The textual input to the model is structured in a way that explicitly encodes the compositional nature of the desired image. This includes separate prompts for each visual element, as well as relational cues between them.
-
Architectural Modifications: The base Textual Inversion model is extended with additional modules that specialize in modeling the interactions and dependencies between different visual elements in a composition.
These changes allow iSEARLE to better understand and represent the complex relationships between objects, scenes, and other visual components, enabling more accurate retrieval of composed images from textual descriptions.
The paper evaluates iSEARLE on a zero-shot composed image retrieval task, where the model is tasked with finding relevant images for textual prompts describing complex visual compositions. The results demonstrate significant improvements over the original Textual Inversion approach, showcasing the effectiveness of the proposed innovations.
Critical Analysis
The paper makes a valuable contribution by addressing a key limitation of Textual Inversion - its inability to handle complex, compositional visual queries. The proposed iSEARLE approach successfully enhances the model's ability to understand and represent the relationships between different visual elements, leading to improved retrieval performance.
However, the paper also acknowledges some potential limitations and areas for further research:
-
Scalability: While iSEARLE demonstrates strong results on the evaluated dataset, it's unclear how the approach would scale to handle even more complex or diverse visual compositions. Further testing on a wider range of compositional scenarios would be helpful.
-
Interpretability: The architectural changes introduced in iSEARLE, while effective, may make the model less interpretable. Exploring ways to maintain transparency and explainability could be an interesting direction for future work.
-
Generalization: The paper focuses on zero-shot retrieval, but it's worth investigating how well iSEARLE's improvements translate to other Textual Inversion tasks, such as image generation or editing.
-
Computational Efficiency: The additional modules and training process in iSEARLE may come with increased computational and memory requirements. Investigating ways to optimize the efficiency of the approach could broaden its real-world applicability.
Overall, the iSEARLE method represents a meaningful step forward in enhancing Textual Inversion's ability to handle complex visual compositions. By thoughtfully addressing this challenge, the researchers have opened up new possibilities for more advanced and versatile multimodal learning systems.
Conclusion
The paper introduces iSEARLE, a novel approach that improves Textual Inversion for the task of zero-shot composed image retrieval. By incorporating compositional training, multimodal prompt engineering, and architectural modifications, iSEARLE enables the Textual Inversion model to better understand and represent the relationships between different visual elements in a scene.
The authors demonstrate that iSEARLE significantly outperforms the original Textual Inversion method on a zero-shot composed image retrieval benchmark, highlighting the effectiveness of the proposed innovations. While the paper acknowledges some potential limitations and areas for further research, the iSEARLE method represents an important step forward in enhancing the capabilities of Textual Inversion and advancing the field of multimodal learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Spherical Linear Interpolation and Text-Anchoring for Zero-shot Composed Image Retrieval
Young Kyun Jang, Dat Huynh, Ashish Shah, Wen-Kai Chen, Ser-Nam Lim
0
0
Composed Image Retrieval (CIR) is a complex task that retrieves images using a query, which is configured with an image and a caption that describes desired modifications to that image. Supervised CIR approaches have shown strong performance, but their reliance on expensive manually-annotated datasets restricts their scalability and broader applicability. To address these issues, previous studies have proposed pseudo-word token-based Zero-Shot CIR (ZS-CIR) methods, which utilize a projection module to map images to word tokens. However, we conjecture that this approach has a downside: the projection module distorts the original image representation and confines the resulting composed embeddings to the text-side. In order to resolve this, we introduce a novel ZS-CIR method that uses Spherical Linear Interpolation (Slerp) to directly merge image and text representations by identifying an intermediate embedding of both. Furthermore, we introduce Text-Anchored-Tuning (TAT), a method that fine-tunes the image encoder while keeping the text encoder fixed. TAT closes the modality gap between images and text, making the Slerp process much more effective. Notably, the TAT method is not only efficient in terms of the scale of the training dataset and training time, but it also serves as an excellent initial checkpoint for training supervised CIR models, thereby highlighting its wider potential. The integration of the Slerp-based ZS-CIR with a TAT-tuned model enables our approach to deliver state-of-the-art retrieval performance across CIR benchmarks.
5/2/2024

Zero-shot Referring Expression Comprehension via Structural Similarity Between Images and Captions
Zeyu Han, Fangrui Zhu, Qianru Lao, Huaizu Jiang
0
0
Zero-shot referring expression comprehension aims at localizing bounding boxes in an image corresponding to provided textual prompts, which requires: (i) a fine-grained disentanglement of complex visual scene and textual context, and (ii) a capacity to understand relationships among disentangled entities. Unfortunately, existing large vision-language alignment (VLA) models, e.g., CLIP, struggle with both aspects so cannot be directly used for this task. To mitigate this gap, we leverage large foundation models to disentangle both images and texts into triplets in the format of (subject, predicate, object). After that, grounding is accomplished by calculating the structural similarity matrix between visual and textual triplets with a VLA model, and subsequently propagate it to an instance-level similarity matrix. Furthermore, to equip VLA models with the ability of relationship understanding, we design a triplet-matching objective to fine-tune the VLA models on a collection of curated dataset containing abundant entity relationships. Experiments demonstrate that our visual grounding performance increase of up to 19.5% over the SOTA zero-shot model on RefCOCO/+/g. On the more challenging Who's Waldo dataset, our zero-shot approach achieves comparable accuracy to the fully supervised model. Code is available at https://github.com/Show-han/Zeroshot_REC.
4/10/2024
🖼️
ComCLIP: Training-Free Compositional Image and Text Matching
Kenan Jiang, Xuehai He, Ruize Xu, Xin Eric Wang
0
0
Contrastive Language-Image Pretraining (CLIP) has demonstrated great zero-shot performance for matching images and text. However, it is still challenging to adapt vision-lanaguage pretrained models like CLIP to compositional image and text matching -- a more challenging image and text matching task requiring the model understanding of compositional word concepts and visual components. Towards better compositional generalization in zero-shot image and text matching, in this paper, we study the problem from a causal perspective: the erroneous semantics of individual entities are essentially confounders that cause the matching failure. Therefore, we propose a novel textbf{textit{training-free}} compositional CLIP model (ComCLIP). ComCLIP disentangles input images into subjects, objects, and action sub-images and composes CLIP's vision encoder and text encoder to perform evolving matching over compositional text embedding and sub-image embeddings. In this way, ComCLIP can mitigate spurious correlations introduced by the pretrained CLIP models and dynamically evaluate the importance of each component. Experiments on four compositional image-text matching datasets: SVO, ComVG, Winoground, and VL-checklist, and two general image-text retrieval datasets: Flick30K, and MSCOCO demonstrate the effectiveness of our plug-and-play method, which boosts the textbf{textit{zero-shot}} inference ability of CLIP, SLIP, and BLIP2 even without further training or fine-tuning. Our codes can be found at https://github.com/eric-ai-lab/ComCLIP.
4/16/2024
CFIR: Fast and Effective Long-Text To Image Retrieval for Large Corpora
Zijun Long, Xuri Ge, Richard Mccreadie, Joemon Jose
0
0
Text-to-image retrieval aims to find the relevant images based on a text query, which is important in various use-cases, such as digital libraries, e-commerce, and multimedia databases. Although Multimodal Large Language Models (MLLMs) demonstrate state-of-the-art performance, they exhibit limitations in handling large-scale, diverse, and ambiguous real-world needs of retrieval, due to the computation cost and the injective embeddings they produce. This paper presents a two-stage Coarse-to-Fine Index-shared Retrieval (CFIR) framework, designed for fast and effective large-scale long-text to image retrieval. The first stage, Entity-based Ranking (ER), adapts to long-text query ambiguity by employing a multiple-queries-to-multiple-targets paradigm, facilitating candidate filtering for the next stage. The second stage, Summary-based Re-ranking (SR), refines these rankings using summarized queries. We also propose a specialized Decoupling-BEiT-3 encoder, optimized for handling ambiguous user needs and both stages, which also enhances computational efficiency through vector-based similarity inference. Evaluation on the AToMiC dataset reveals that CFIR surpasses existing MLLMs by up to 11.06% in Recall@1000, while reducing training and retrieval times by 68.75% and 99.79%, respectively. We will release our code to facilitate future research at https://github.com/longkukuhi/CFIR.
4/4/2024