Spherical Linear Interpolation and Text-Anchoring for Zero-shot Composed Image Retrieval

0
Sign in to get full access
Overview
- This paper introduces a novel approach for zero-shot composed image retrieval, which aims to retrieve relevant images based on compositional text queries without any prior training on the target images.
- The key innovations include spherical linear interpolation (Slerp) to generate intermediate image representations and text-anchored tuning to align the retrieved images with the compositional text.
- The proposed method outperforms state-of-the-art approaches on several benchmark datasets, demonstrating its effectiveness for zero-shot composed image retrieval.
Plain English Explanation
The paper describes a new way to search for images based on text descriptions that combine multiple concepts, without having to train the system on those specific images beforehand. For example, you could search for an "angry dog chasing a cat" and the system would try to find relevant images, even if it had never seen that exact combination of concepts before.
The researchers use a technique called "spherical linear interpolation" (or Slerp) to create intermediate representations between the images in their database. This allows the system to find images that are a closer match to the text query, even if an exact match doesn't exist. They also use "text-anchored tuning" to further align the retrieved images with the specific wording of the text query.
By combining these innovations, the researchers were able to outperform other state-of-the-art methods for this task of zero-shot composed image retrieval. This could be very useful for applications where users want to search for images based on complex, compositional descriptions, without requiring a large training dataset of labeled images.
Technical Explanation
The paper proposes a novel approach for zero-shot composed image retrieval, where the goal is to retrieve relevant images based on text queries that combine multiple concepts, without any prior training on the target images.
The key innovations include:
-
Spherical Linear Interpolation (Slerp): The researchers use Slerp to generate intermediate image representations between the existing images in the database. This allows the system to find images that are a closer match to the compositional text query, even if an exact match doesn't exist.
-
Text-Anchored Tuning: The authors introduce a text-anchoring mechanism to further align the retrieved images with the specific wording of the text query. This is done by fine-tuning the image representations to better match the semantics of the compositional text.
The proposed method is evaluated on several benchmark datasets for zero-shot composed image retrieval, including CFIR, DualCLIP, and PromptCIR. The results show that the approach outperforms state-of-the-art methods, demonstrating its effectiveness for this task.
Critical Analysis
The paper presents a compelling approach to the challenge of zero-shot composed image retrieval, addressing the limitations of previous methods. The use of Slerp to generate intermediate image representations and the text-anchored tuning mechanism are innovative and well-justified.
However, the paper does not discuss the computational complexity or runtime efficiency of the proposed method, which could be an important consideration for real-world applications. Additionally, the impact of the text-anchored tuning on the model's generalization capabilities is not thoroughly explored.
It would also be interesting to see how the method performs on more diverse or challenging datasets, such as those with a broader range of compositional queries or more complex visual scenes. Exploring the integration of the proposed approach with compositional image-text matching could also be a valuable direction for future research.
Conclusion
This paper introduces a novel approach for zero-shot composed image retrieval that leverages spherical linear interpolation and text-anchored tuning to effectively match compositional text queries to relevant images. The proposed method outperforms state-of-the-art techniques on several benchmark datasets, demonstrating its potential for applications where users need to search for images based on complex, multi-faceted descriptions.
The innovations presented in this work could have significant implications for the field of image retrieval and the development of more advanced, user-friendly image search systems. The critical analysis also suggests directions for further research to refine and expand the capabilities of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Spherical Linear Interpolation and Text-Anchoring for Zero-shot Composed Image Retrieval
Young Kyun Jang, Dat Huynh, Ashish Shah, Wen-Kai Chen, Ser-Nam Lim
Composed Image Retrieval (CIR) is a complex task that retrieves images using a query, which is configured with an image and a caption that describes desired modifications to that image. Supervised CIR approaches have shown strong performance, but their reliance on expensive manually-annotated datasets restricts their scalability and broader applicability. To address these issues, previous studies have proposed pseudo-word token-based Zero-Shot CIR (ZS-CIR) methods, which utilize a projection module to map images to word tokens. However, we conjecture that this approach has a downside: the projection module distorts the original image representation and confines the resulting composed embeddings to the text-side. In order to resolve this, we introduce a novel ZS-CIR method that uses Spherical Linear Interpolation (Slerp) to directly merge image and text representations by identifying an intermediate embedding of both. Furthermore, we introduce Text-Anchored-Tuning (TAT), a method that fine-tunes the image encoder while keeping the text encoder fixed. TAT closes the modality gap between images and text, making the Slerp process much more effective. Notably, the TAT method is not only efficient in terms of the scale of the training dataset and training time, but it also serves as an excellent initial checkpoint for training supervised CIR models, thereby highlighting its wider potential. The integration of the Slerp-based ZS-CIR with a TAT-tuned model enables our approach to deliver state-of-the-art retrieval performance across CIR benchmarks.
Read more5/2/2024
0
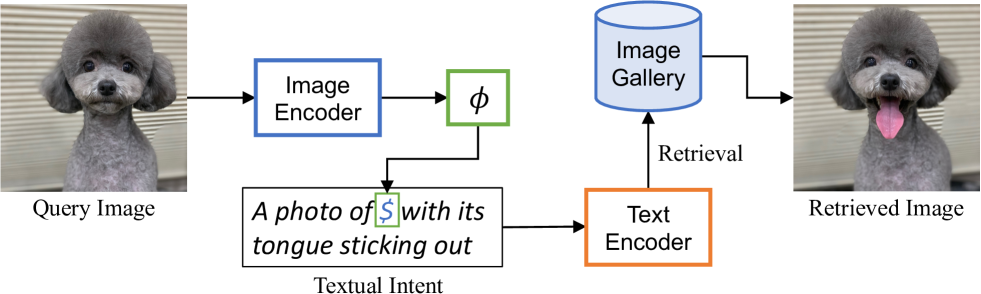
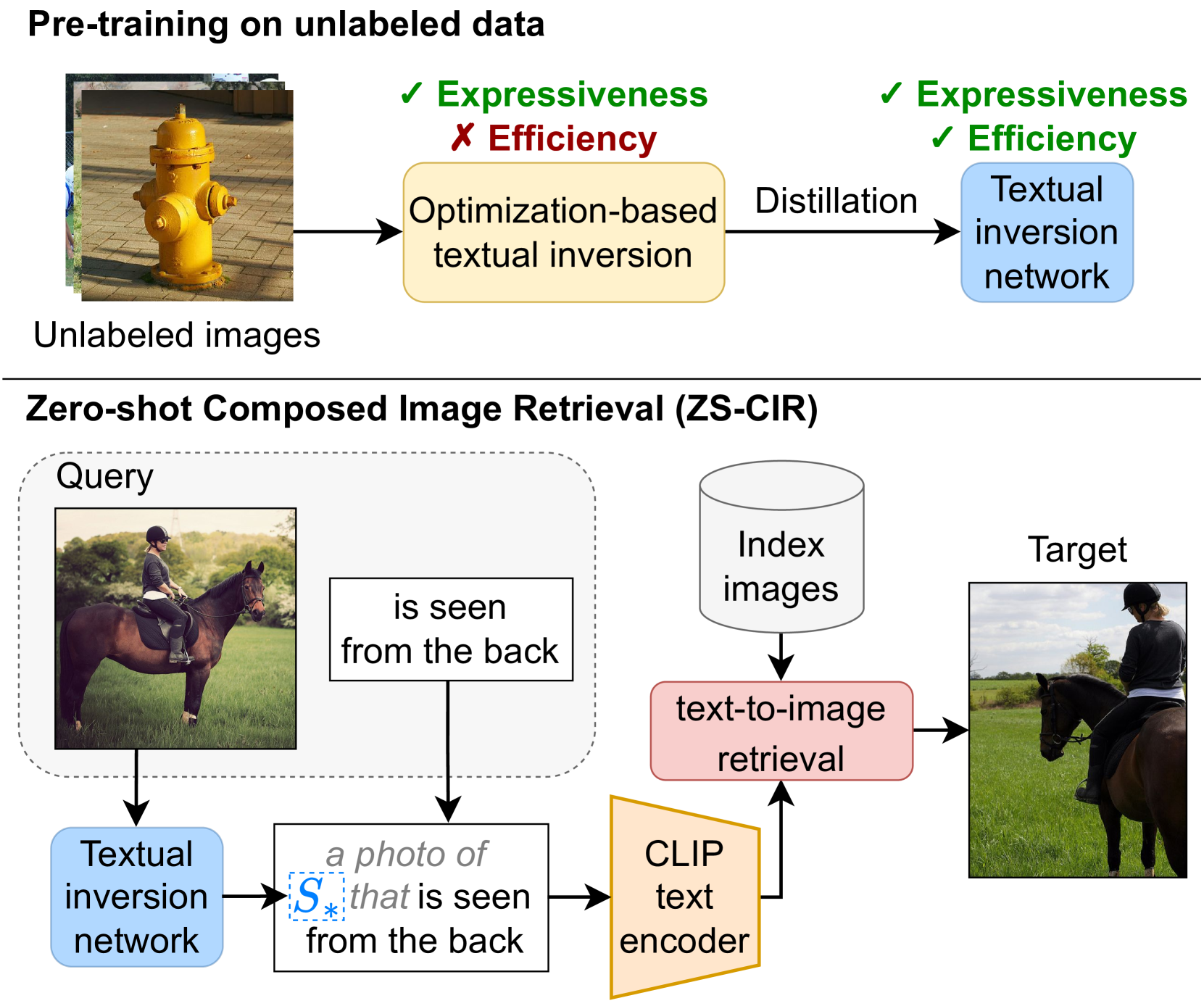
iSEARLE: Improving Textual Inversion for Zero-Shot Composed Image Retrieval
Lorenzo Agnolucci, Alberto Baldrati, Marco Bertini, Alberto Del Bimbo
Given a query consisting of a reference image and a relative caption, Composed Image Retrieval (CIR) aims to retrieve target images visually similar to the reference one while incorporating the changes specified in the relative caption. The reliance of supervised methods on labor-intensive manually labeled datasets hinders their broad applicability. In this work, we introduce a new task, Zero-Shot CIR (ZS-CIR), that addresses CIR without the need for a labeled training dataset. We propose an approach named iSEARLE (improved zero-Shot composEd imAge Retrieval with textuaL invErsion) that involves mapping the visual information of the reference image into a pseudo-word token in CLIP token embedding space and combining it with the relative caption. To foster research on ZS-CIR, we present an open-domain benchmarking dataset named CIRCO (Composed Image Retrieval on Common Objects in context), the first CIR dataset where each query is labeled with multiple ground truths and a semantic categorization. The experimental results illustrate that iSEARLE obtains state-of-the-art performance on three different CIR datasets -- FashionIQ, CIRR, and the proposed CIRCO -- and two additional evaluation settings, namely domain conversion and object composition. The dataset, the code, and the model are publicly available at https://github.com/miccunifi/SEARLE.
Read more5/7/2024
0
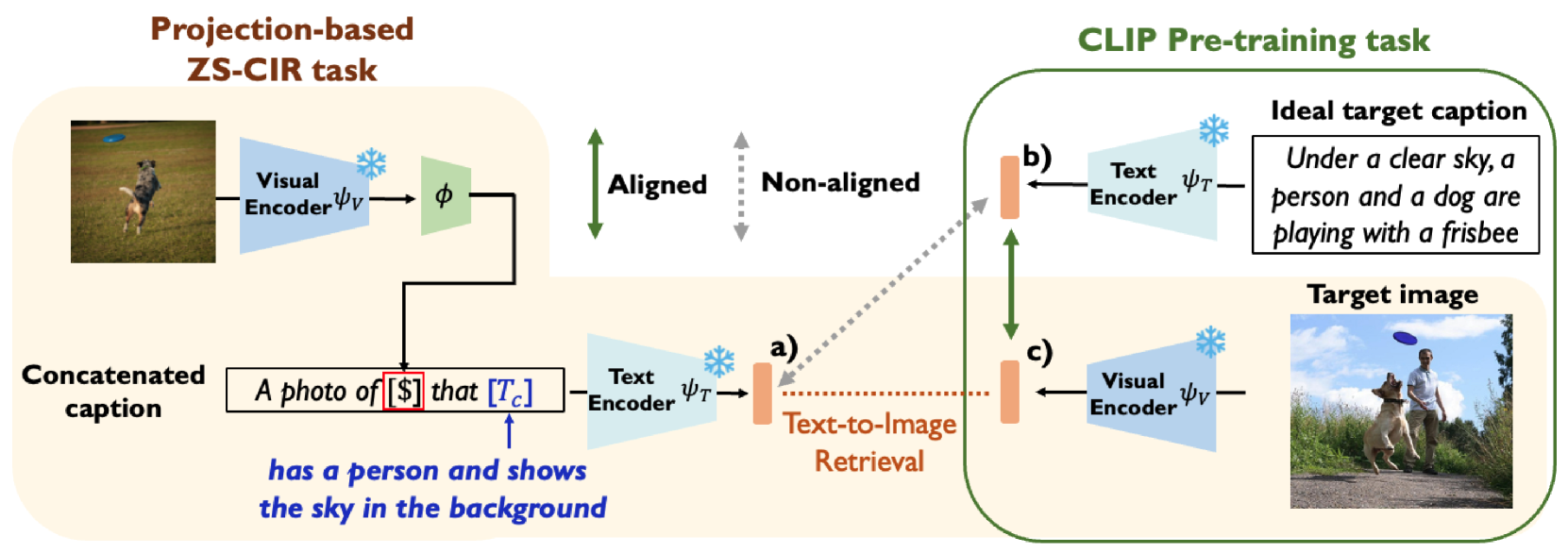
Reducing Task Discrepancy of Text Encoders for Zero-Shot Composed Image Retrieval
Jaeseok Byun, Seokhyeon Jeong, Wonjae Kim, Sanghyuk Chun, Taesup Moon
Composed Image Retrieval (CIR) aims to retrieve a target image based on a reference image and conditioning text, enabling controllable searches. Due to the expensive dataset construction cost for CIR triplets, a zero-shot (ZS) CIR setting has been actively studied to eliminate the need for human-collected triplet datasets. The mainstream of ZS-CIR employs an efficient projection module that projects a CLIP image embedding to the CLIP text token embedding space, while fixing the CLIP encoders. Using the projected image embedding, these methods generate image-text composed features by using the pre-trained text encoder. However, their CLIP image and text encoders suffer from the task discrepancy between the pre-training task (text $leftrightarrow$ image) and the target CIR task (image + text $leftrightarrow$ image). Conceptually, we need expensive triplet samples to reduce the discrepancy, but we use cheap text triplets instead and update the text encoder. To that end, we introduce the Reducing Task Discrepancy of text encoders for Composed Image Retrieval (RTD), a plug-and-play training scheme for the text encoder that enhances its capability using a novel target-anchored text contrastive learning. We also propose two additional techniques to improve the proposed learning scheme: a hard negatives-based refined batch sampling strategy and a sophisticated concatenation scheme. Integrating RTD into the state-of-the-art projection-based ZS-CIR methods significantly improves performance across various datasets and backbones, demonstrating its efficiency and generalizability.
Read more6/14/2024

0
Zero-shot Composed Image Retrieval Considering Query-target Relationship Leveraging Masked Image-text Pairs
Huaying Zhang, Rintaro Yanagi, Ren Togo, Takahiro Ogawa, Miki Haseyama
This paper proposes a novel zero-shot composed image retrieval (CIR) method considering the query-target relationship by masked image-text pairs. The objective of CIR is to retrieve the target image using a query image and a query text. Existing methods use a textual inversion network to convert the query image into a pseudo word to compose the image and text and use a pre-trained visual-language model to realize the retrieval. However, they do not consider the query-target relationship to train the textual inversion network to acquire information for retrieval. In this paper, we propose a novel zero-shot CIR method that is trained end-to-end using masked image-text pairs. By exploiting the abundant image-text pairs that are convenient to obtain with a masking strategy for learning the query-target relationship, it is expected that accurate zero-shot CIR using a retrieval-focused textual inversion network can be realized. Experimental results show the effectiveness of the proposed method.
Read more6/28/2024