Zero-shot Referring Expression Comprehension via Structural Similarity Between Images and Captions
2311.17048
0
0

Abstract
Zero-shot referring expression comprehension aims at localizing bounding boxes in an image corresponding to provided textual prompts, which requires: (i) a fine-grained disentanglement of complex visual scene and textual context, and (ii) a capacity to understand relationships among disentangled entities. Unfortunately, existing large vision-language alignment (VLA) models, e.g., CLIP, struggle with both aspects so cannot be directly used for this task. To mitigate this gap, we leverage large foundation models to disentangle both images and texts into triplets in the format of (subject, predicate, object). After that, grounding is accomplished by calculating the structural similarity matrix between visual and textual triplets with a VLA model, and subsequently propagate it to an instance-level similarity matrix. Furthermore, to equip VLA models with the ability of relationship understanding, we design a triplet-matching objective to fine-tune the VLA models on a collection of curated dataset containing abundant entity relationships. Experiments demonstrate that our visual grounding performance increase of up to 19.5% over the SOTA zero-shot model on RefCOCO/+/g. On the more challenging Who's Waldo dataset, our zero-shot approach achieves comparable accuracy to the fully supervised model. Code is available at https://github.com/Show-han/Zeroshot_REC.
Create account to get full access
Overview
- This paper proposes a novel approach for zero-shot referring expression comprehension, which aims to locate objects in images based on textual descriptions without any prior training examples.
- The key idea is to leverage the structural similarity between image-caption pairs to enable zero-shot learning, without relying on explicit object annotations or bounding boxes.
- The proposed method outperforms existing state-of-the-art approaches on several benchmark datasets, demonstrating its effectiveness in grounding textual descriptions to corresponding visual regions.
Plain English Explanation
The paper focuses on a computer vision task called "zero-shot referring expression comprehension." This means being able to find an object in an image based on a textual description, even if the model has never seen that exact object-description pair before.
The researchers developed a new approach that takes advantage of the inherent connection between images and the captions that describe them. By learning the structural patterns in how images and their captions relate to each other, the model can then apply this knowledge to understand new descriptions and locate the corresponding objects, without needing any prior examples of those specific object-description pairs.
This is a significant advancement, as previous methods required explicit annotations linking visual objects to their textual descriptions. The new approach is more flexible and can generalize to novel scenarios, which is an important step towards building AI systems that can truly understand and interact with the world in human-like ways.
Technical Explanation
The key innovation in this paper is the idea of leveraging the structural similarity between images and their captions to enable zero-shot referring expression comprehension.
The authors propose a multi-task learning framework that jointly trains two neural network modules: an image-caption alignment module and a referring expression comprehension module. The alignment module learns to predict whether a given image-caption pair matches, while the referring module learns to locate the referred object in an image given a textual description.
By sharing visual and linguistic encoding components between these two tasks, the model can learn rich cross-modal representations that capture the inherent structural correspondence between images and text. This allows the referring module to generalize to unseen object-description pairs during inference, without requiring any object-level annotations.
The authors evaluate their approach on several benchmark datasets for referring expression comprehension, and show that it outperforms existing state-of-the-art methods that rely on explicit object annotations. This highlights the power of exploiting the natural structural similarity between visual and linguistic data, as opposed to requiring detailed supervision.
Critical Analysis
The paper presents a compelling and well-designed approach for zero-shot referring expression comprehension. One key strength is the elegant way it leverages the structural alignment between images and their captions, without requiring any object-level annotations.
However, the authors do acknowledge several limitations and avenues for future work. For example, the model may struggle with complex scenes or descriptions that require higher-level reasoning beyond simple object localization. Additionally, the performance is still below human-level, suggesting there is room for improvement.
It would also be interesting to see how this approach generalizes to other zero-shot vision-language tasks, such as improved zero-shot classification by adapting VLMs or using language models for open-world detection. Exploring synergies with semantically prompted language models for better visual descriptions could also be a fruitful direction.
Overall, this paper represents an important step towards more flexible and generalizable vision-language models, bringing us closer to the goal of language models that can truly understand and interact with the visual world.
Conclusion
This paper introduces a novel approach for zero-shot referring expression comprehension that leverages the structural similarity between images and their captions. By jointly learning to align image-caption pairs and locate referred objects, the model can generalize to unseen object-description combinations without requiring explicit object annotations.
The results demonstrate the effectiveness of this approach, outperforming existing state-of-the-art methods. This work represents an important advancement in vision-language understanding, moving us closer to the goal of building AI systems that can seamlessly interact with the world in human-like ways. Further research exploring the broader applications and limitations of this technique could yield valuable insights for the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Visual-Text Cross Alignment: Refining the Similarity Score in Vision-Language Models
Jinhao Li, Haopeng Li, Sarah Erfani, Lei Feng, James Bailey, Feng Liu
0
0
It has recently been discovered that using a pre-trained vision-language model (VLM), e.g., CLIP, to align a whole query image with several finer text descriptions generated by a large language model can significantly enhance zero-shot performance. However, in this paper, we empirically find that the finer descriptions tend to align more effectively with local areas of the query image rather than the whole image, and then we theoretically validate this finding. Thus, we present a method called weighted visual-text cross alignment (WCA). This method begins with a localized visual prompting technique, designed to identify local visual areas within the query image. The local visual areas are then cross-aligned with the finer descriptions by creating a similarity matrix using the pre-trained VLM. To determine how well a query image aligns with each category, we develop a score function based on the weighted similarities in this matrix. Extensive experiments demonstrate that our method significantly improves zero-shot performance across various datasets, achieving results that are even comparable to few-shot learning methods.
6/6/2024
🖼️
ComCLIP: Training-Free Compositional Image and Text Matching
Kenan Jiang, Xuehai He, Ruize Xu, Xin Eric Wang
0
0
Contrastive Language-Image Pretraining (CLIP) has demonstrated great zero-shot performance for matching images and text. However, it is still challenging to adapt vision-lanaguage pretrained models like CLIP to compositional image and text matching -- a more challenging image and text matching task requiring the model understanding of compositional word concepts and visual components. Towards better compositional generalization in zero-shot image and text matching, in this paper, we study the problem from a causal perspective: the erroneous semantics of individual entities are essentially confounders that cause the matching failure. Therefore, we propose a novel textbf{textit{training-free}} compositional CLIP model (ComCLIP). ComCLIP disentangles input images into subjects, objects, and action sub-images and composes CLIP's vision encoder and text encoder to perform evolving matching over compositional text embedding and sub-image embeddings. In this way, ComCLIP can mitigate spurious correlations introduced by the pretrained CLIP models and dynamically evaluate the importance of each component. Experiments on four compositional image-text matching datasets: SVO, ComVG, Winoground, and VL-checklist, and two general image-text retrieval datasets: Flick30K, and MSCOCO demonstrate the effectiveness of our plug-and-play method, which boosts the textbf{textit{zero-shot}} inference ability of CLIP, SLIP, and BLIP2 even without further training or fine-tuning. Our codes can be found at https://github.com/eric-ai-lab/ComCLIP.
4/16/2024
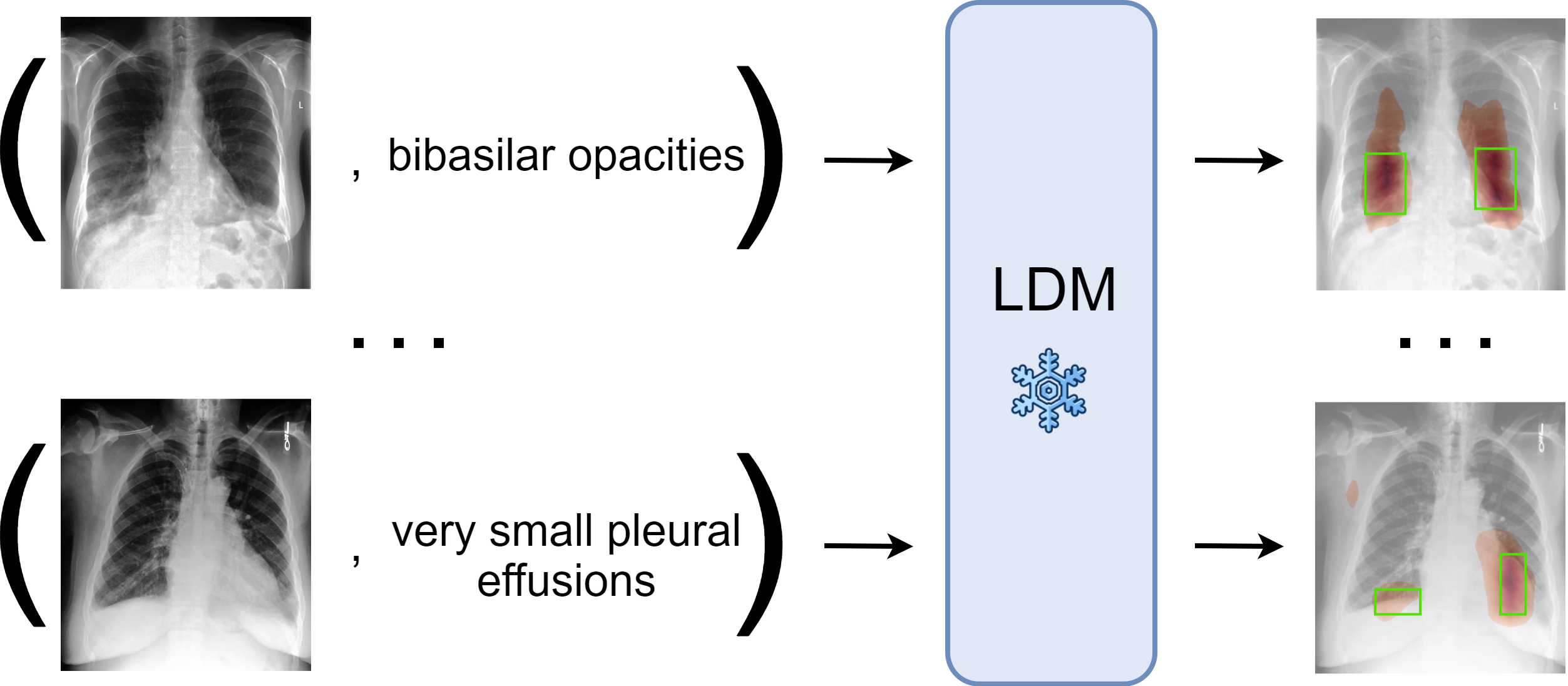
Zero-Shot Medical Phrase Grounding with Off-the-shelf Diffusion Models
Konstantinos Vilouras, Pedro Sanchez, Alison Q. O'Neil, Sotirios A. Tsaftaris
0
0
Localizing the exact pathological regions in a given medical scan is an important imaging problem that requires a large amount of bounding box ground truth annotations to be accurately solved. However, there exist alternative, potentially weaker, forms of supervision, such as accompanying free-text reports, which are readily available. The task of performing localization with textual guidance is commonly referred to as phrase grounding. In this work, we use a publicly available Foundation Model, namely the Latent Diffusion Model, to solve this challenging task. This choice is supported by the fact that the Latent Diffusion Model, despite being generative in nature, contains mechanisms (cross-attention) that implicitly align visual and textual features, thus leading to intermediate representations that are suitable for the task at hand. In addition, we aim to perform this task in a zero-shot manner, i.e., without any further training on target data, meaning that the model's weights remain frozen. To this end, we devise strategies to select features and also refine them via post-processing without extra learnable parameters. We compare our proposed method with state-of-the-art approaches which explicitly enforce image-text alignment in a joint embedding space via contrastive learning. Results on a popular chest X-ray benchmark indicate that our method is competitive wih SOTA on different types of pathology, and even outperforms them on average in terms of two metrics (mean IoU and AUC-ROC). Source code will be released upon acceptance.
4/22/2024

A Simple Framework for Open-Vocabulary Zero-Shot Segmentation
Thomas Stegmuller, Tim Lebailly, Nikola Dukic, Behzad Bozorgtabar, Jean-Philippe Thiran, Tinne Tuytelaars
0
0
Zero-shot classification capabilities naturally arise in models trained within a vision-language contrastive framework. Despite their classification prowess, these models struggle in dense tasks like zero-shot open-vocabulary segmentation. This deficiency is often attributed to the absence of localization cues in captions and the intertwined nature of the learning process, which encompasses both image representation learning and cross-modality alignment. To tackle these issues, we propose SimZSS, a Simple framework for open-vocabulary Zero-Shot Segmentation. The method is founded on two key principles: i) leveraging frozen vision-only models that exhibit spatial awareness while exclusively aligning the text encoder and ii) exploiting the discrete nature of text and linguistic knowledge to pinpoint local concepts within captions. By capitalizing on the quality of the visual representations, our method requires only image-caption pairs datasets and adapts to both small curated and large-scale noisy datasets. When trained on COCO Captions across 8 GPUs, SimZSS achieves state-of-the-art results on 7 out of 8 benchmark datasets in less than 15 minutes.
6/26/2024