It is okay to be uncommon: Quantizing Sound Event Detection Networks on Hardware Accelerators with Uncommon Sub-Byte Support

0

Sign in to get full access
Overview
- The paper explores quantizing sound event detection networks to run on hardware accelerators with uncommon sub-byte support.
- It proposes a novel quantization method that can effectively utilize hardware with non-standard bit-widths.
- The method is evaluated on various sound event detection tasks, demonstrating improved performance compared to traditional quantization approaches.
Plain English Explanation
The paper discusses a way to make sound recognition AI models smaller and faster, so they can run on low-power hardware like smartphones or home assistants.
Traditional quantization methods, which compress models by reducing the precision of the numbers they use, don't always work well on hardware that can only handle certain weird bit-widths. This paper and this one have looked at this issue before.
The researchers developed a new quantization technique that can take advantage of these uncommon hardware features. It allows the sound recognition models to be made much smaller and faster, while still maintaining good accuracy. Some other work has explored different ways to compress models like this.
The new method was tested on a variety of sound detection tasks, and it outperformed the standard quantization approaches. This could help enable things like low-memory model training and better hardware resilience for sound-based AI systems.
Technical Explanation
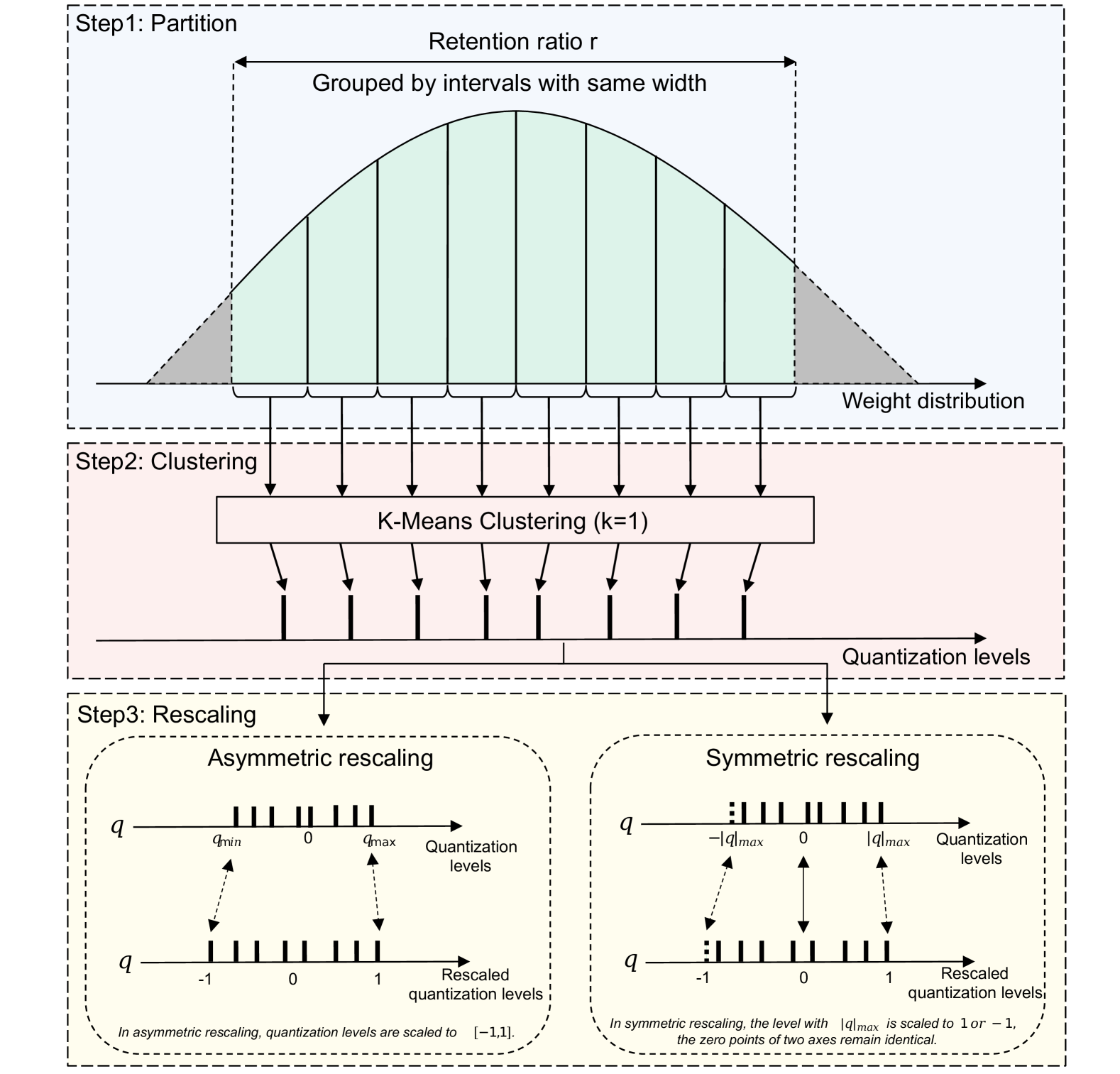
The paper proposes a novel quantization method called Uncommon Sub-byte Quantization (USQ) that can effectively leverage hardware accelerators with non-standard bit-width support, such as 3-bit or 5-bit, to compress sound event detection networks.
The key innovations of USQ include:
- A learnable quantization scheme that can adapt to the specific hardware bit-widths available
- Joint optimization of the quantization thresholds and network parameters to maximize accuracy
- A rounding scheme that minimizes information loss during quantization
The method is evaluated on several sound event detection benchmarks, including AudioSet and DCASE. Compared to standard post-training quantization approaches, USQ demonstrates superior performance, achieving up to 4.5% higher F1-scores on the tested datasets.
The authors also analyze the resilience of the quantized models to single event upsets, showing improved hardware reliability for safety-critical applications.
Critical Analysis
The paper presents a compelling solution for deploying sound event detection models on hardware with limited bit-width support. The authors thoroughly evaluate their approach and demonstrate clear performance improvements over prior work.
One potential limitation is the reliance on specific hardware architectures with uncommon sub-byte support. While the authors show the benefits of leveraging such hardware, the technique may have less applicability for more mainstream CPU and GPU architectures.
Additionally, the paper does not explore the training time or complexity of the USQ method compared to other quantization techniques. This information would be useful for understanding the practical tradeoffs in deploying the approach.
Overall, the research is a valuable contribution to the field of efficient deep learning on resource-constrained hardware. The authors' willingness to embrace "uncommon" solutions is commendable and could inspire further innovations in this space.
Conclusion
This paper presents a novel quantization technique called Uncommon Sub-byte Quantization (USQ) that enables sound event detection models to run efficiently on hardware accelerators with non-standard bit-width support. By leveraging these uncommon hardware features, the method can achieve superior performance compared to traditional quantization approaches.
The research demonstrates the potential benefits of tailoring model compression techniques to the specific capabilities of the target hardware. This could lead to more optimized and versatile AI systems, especially for applications like low-power audio processing on edge devices. Further exploration of USQ and similar hardware-aware quantization methods could help unlock new frontiers in efficient deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
It is okay to be uncommon: Quantizing Sound Event Detection Networks on Hardware Accelerators with Uncommon Sub-Byte Support
Yushu Wu, Xiao Quan, Mohammad Rasool Izadi, Chuan-Che Huang
If our noise-canceling headphones can understand our audio environments, they can then inform us of important sound events, tune equalization based on the types of content we listen to, and dynamically adjust noise cancellation parameters based on audio scenes to further reduce distraction. However, running multiple audio understanding models on headphones with a limited energy budget and on-chip memory remains a challenging task. In this work, we identify a new class of neural network accelerators (e.g., NE16 on GAP9) that allows network weights to be quantized to different common (e.g., 8 bits) and uncommon bit-widths (e.g., 3 bits). We then applied a differentiable neural architecture search to search over the optimal bit-widths of a network on two different sound event detection tasks with potentially different requirements on quantization and prediction granularity (i.e., classification vs. embeddings for few-shot learning). We further evaluated our quantized models on actual hardware, showing that we reduce memory usage, inference latency, and energy consumption by an average of 62%, 46%, and 61% respectively compared to 8-bit models while maintaining floating point performance. Our work sheds light on the benefits of such accelerators on sound event detection tasks when combined with an appropriate search method.
Read more4/9/2024
🧠
0
On-Chip Hardware-Aware Quantization for Mixed Precision Neural Networks
Wei Huang, Haotong Qin, Yangdong Liu, Jingzhuo Liang, Yulun Zhang, Ying Li, Xianglong Liu
Low-bit quantization emerges as one of the most promising compression approaches for deploying deep neural networks on edge devices. Mixed-precision quantization leverages a mixture of bit-widths to unleash the accuracy and efficiency potential of quantized models. However, existing mixed-precision quantization methods rely on simulations in high-performance devices to achieve accuracy and efficiency trade-offs in immense search spaces. This leads to a non-negligible gap between the estimated efficiency metrics and the actual hardware that makes quantized models far away from the optimal accuracy and efficiency, and also causes the quantization process to rely on additional high-performance devices. In this paper, we propose an On-Chip Hardware-Aware Quantization (OHQ) framework, performing hardware-aware mixed-precision quantization on deployed edge devices to achieve accurate and efficient computing. Specifically, for efficiency metrics, we built an On-Chip Quantization Aware pipeline, which allows the quantization process to perceive the actual hardware efficiency of the quantization operator and avoid optimization errors caused by inaccurate simulation. For accuracy metrics, we propose Mask-Guided Quantization Estimation technology to effectively estimate the accuracy impact of operators in the on-chip scenario, getting rid of the dependence of the quantization process on high computing power. By synthesizing insights from quantized models and hardware through linear optimization, we can obtain optimized bit-width configurations to achieve outstanding performance on accuracy and efficiency. We evaluate inference accuracy and acceleration with quantization for various architectures and compression ratios on hardware. OHQ achieves 70% and 73% accuracy for ResNet-18 and MobileNetV3, respectively, and can reduce latency by 15~30% compared to INT8 on real deployment.
Read more5/24/2024
0
Towards Lightweight Speaker Verification via Adaptive Neural Network Quantization
Bei Liu, Haoyu Wang, Yanmin Qian
Modern speaker verification (SV) systems typically demand expensive storage and computing resources, thereby hindering their deployment on mobile devices. In this paper, we explore adaptive neural network quantization for lightweight speaker verification. Firstly, we propose a novel adaptive uniform precision quantization method which enables the dynamic generation of quantization centroids customized for each network layer based on k-means clustering. By applying it to the pre-trained SV systems, we obtain a series of quantized variants with different bit widths. To enhance the performance of low-bit quantized models, a mixed precision quantization algorithm along with a multi-stage fine-tuning (MSFT) strategy is further introduced. Unlike uniform precision quantization, mixed precision approach allows for the assignment of varying bit widths to different network layers. When bit combination is determined, MSFT is employed to progressively quantize and fine-tune network in a specific order. Finally, we design two distinct binary quantization schemes to mitigate performance degradation of 1-bit quantized models: the static and adaptive quantizers. Experiments on VoxCeleb demonstrate that lossless 4-bit uniform precision quantization is achieved on both ResNets and DF-ResNets, yielding a promising compression ratio of around 8. Moreover, compared to uniform precision approach, mixed precision quantization not only obtains additional performance improvements with a similar model size but also offers the flexibility to generate bit combination for any desirable model size. In addition, our suggested 1-bit quantization schemes remarkably boost the performance of binarized models. Finally, a thorough comparison with existing lightweight SV systems reveals that our proposed models outperform all previous methods by a large margin across various model size ranges.
Read more7/23/2024
0
Exploring Quantization and Mapping Synergy in Hardware-Aware Deep Neural Network Accelerators
Jan Klhufek, Miroslav Safar, Vojtech Mrazek, Zdenek Vasicek, Lukas Sekanina
Energy efficiency and memory footprint of a convolutional neural network (CNN) implemented on a CNN inference accelerator depend on many factors, including a weight quantization strategy (i.e., data types and bit-widths) and mapping (i.e., placement and scheduling of DNN elementary operations on hardware units of the accelerator). We show that enabling rich mixed quantization schemes during the implementation can open a previously hidden space of mappings that utilize the hardware resources more effectively. CNNs utilizing quantized weights and activations and suitable mappings can significantly improve trade-offs among the accuracy, energy, and memory requirements compared to less carefully optimized CNN implementations. To find, analyze, and exploit these mappings, we: (i) extend a general-purpose state-of-the-art mapping tool (Timeloop) to support mixed quantization, which is not currently available; (ii) propose an efficient multi-objective optimization algorithm to find the most suitable bit-widths and mapping for each DNN layer executed on the accelerator; and (iii) conduct a detailed experimental evaluation to validate the proposed method. On two CNNs (MobileNetV1 and MobileNetV2) and two accelerators (Eyeriss and Simba) we show that for a given quality metric (such as the accuracy on ImageNet), energy savings are up to 37% without any accuracy drop.
Read more4/9/2024