Exploring the Compositional Deficiency of Large Language Models in Mathematical Reasoning
2405.06680
0
0
💬
Abstract
Human cognition exhibits systematic compositionality, the algebraic ability to generate infinite novel combinations from finite learned components, which is the key to understanding and reasoning about complex logic. In this work, we investigate the compositionality of large language models (LLMs) in mathematical reasoning. Specifically, we construct a new dataset textsc{MathTrap}footnotemark[3] by introducing carefully designed logical traps into the problem descriptions of MATH and GSM8k. Since problems with logical flaws are quite rare in the real world, these represent ``unseen'' cases to LLMs. Solving these requires the models to systematically compose (1) the mathematical knowledge involved in the original problems with (2) knowledge related to the introduced traps. Our experiments show that while LLMs possess both components of requisite knowledge, they do not textbf{spontaneously} combine them to handle these novel cases. We explore several methods to mitigate this deficiency, such as natural language prompts, few-shot demonstrations, and fine-tuning. We find that LLMs' performance can be textbf{passively} improved through the above external intervention. Overall, systematic compositionality remains an open challenge for large language models.
Create account to get full access
Overview
- This paper explores the limitations of large language models (LLMs) in mathematical reasoning tasks.
- The authors introduce the MathTrap dataset, which tests the compositional abilities of LLMs on mathematical word problems.
- The results suggest that while LLMs can perform well on individual steps, they struggle with more complex, multi-step problems that require composing multiple skills.
- The paper provides insights into the challenges of building truly compositional language models that can generalize mathematical reasoning.
Plain English Explanation
Large language models (LLMs) like GPT-3 have made impressive strides in natural language processing, but their mathematical reasoning abilities are still limited. The MathTrap dataset was created to test how well these models can handle more complex, multi-step math word problems.
The researchers found that LLMs can do well on individual math operations, like addition or subtraction. However, when faced with problems that require combining multiple steps, the models start to struggle. They have difficulty keeping track of the different components and putting them together in a logical way.
This reveals a fundamental limitation in the compositional abilities of current LLMs. They may excel at processing language, but they lack the deeper understanding needed to systematically compose different skills and reasoning steps. This is an important challenge to overcome if we want AI systems that can truly excel at mathematical problem-solving.
Technical Explanation
The paper investigates the compositional abilities of large language models (LLMs) in the domain of mathematical reasoning. The authors introduce the MathTrap dataset, which consists of multi-step word problems that require composing various mathematical concepts and skills.
Through extensive experiments, the researchers evaluate the performance of state-of-the-art LLMs, including GPT-3, on the MathTrap dataset. The results show that while the models can handle individual mathematical operations like addition or subtraction reasonably well, they struggle significantly when faced with problems that require combining multiple steps and reasoning components.
The authors delve deeper into the models' deductive competence and find that the models often fail to maintain a coherent understanding of the problem state and context, leading to breakdowns in their ability to compose the necessary mathematical skills.
The paper provides valuable insights into the theoretical underpinnings of compositional reasoning and how current LLM architectures fall short in this regard. The authors discuss potential directions for improving the compositional generalization of language models, which could pave the way for more robust and versatile AI systems capable of advanced mathematical reasoning.
Critical Analysis
The paper presents a comprehensive analysis of the limitations of large language models (LLMs) in the domain of mathematical reasoning. The authors have designed a well-structured dataset, MathTrap, that effectively tests the compositional abilities of these models, which is a valuable contribution to the field.
One potential limitation of the study is the reliance on a relatively narrow set of models (GPT-3 and its variants), which may not fully capture the diversity of LLM architectures and training approaches. It would be interesting to see how other prominent LLMs, such as those developed by companies like Google or DeepMind, perform on the MathTrap dataset.
Additionally, the paper focuses on the inherent challenges of compositional reasoning in LLMs, but it does not explore potential solutions or architectural modifications that could address these limitations. While the theoretical insights provided are valuable, more research is needed to develop strategies for enhancing the compositional generalization of these models.
Overall, the paper makes a significant contribution to our understanding of the current shortcomings of LLMs in mathematical reasoning and highlights the need for continued research to overcome these limitations. The insights provided can inform the development of more robust and versatile AI systems capable of advanced problem-solving.
Conclusion
This paper sheds light on the compositional deficiencies of large language models (LLMs) in the domain of mathematical reasoning. The introduction of the MathTrap dataset allows for a comprehensive evaluation of these models' abilities to handle complex, multi-step word problems.
The results reveal that while LLMs can perform well on individual mathematical operations, they struggle when required to compose multiple reasoning steps. This finding underscores the fundamental challenge of building truly compositional language models that can generalize their knowledge and skills to solve novel, complex problems.
The insights from this study can inform the ongoing efforts to develop more robust and versatile AI systems capable of advanced problem-solving. By addressing the limitations in compositional reasoning, researchers can work towards creating language models that can better understand and apply mathematical concepts in a systematic and generalizable manner, with far-reaching implications for the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
From Frege to chatGPT: Compositionality in language, cognition, and deep neural networks
Jacob Russin, Sam Whitman McGrath, Danielle J. Williams, Lotem Elber-Dorozko
0
0
Compositionality has long been considered a key explanatory property underlying human intelligence: arbitrary concepts can be composed into novel complex combinations, permitting the acquisition of an open ended, potentially infinite expressive capacity from finite learning experiences. Influential arguments have held that neural networks fail to explain this aspect of behavior, leading many to dismiss them as viable models of human cognition. Over the last decade, however, modern deep neural networks (DNNs), which share the same fundamental design principles as their predecessors, have come to dominate artificial intelligence, exhibiting the most advanced cognitive behaviors ever demonstrated in machines. In particular, large language models (LLMs), DNNs trained to predict the next word on a large corpus of text, have proven capable of sophisticated behaviors such as writing syntactically complex sentences without grammatical errors, producing cogent chains of reasoning, and even writing original computer programs -- all behaviors thought to require compositional processing. In this chapter, we survey recent empirical work from machine learning for a broad audience in philosophy, cognitive science, and neuroscience, situating recent breakthroughs within the broader context of philosophical arguments about compositionality. In particular, our review emphasizes two approaches to endowing neural networks with compositional generalization capabilities: (1) architectural inductive biases, and (2) metalearning, or learning to learn. We also present findings suggesting that LLM pretraining can be understood as a kind of metalearning, and can thereby equip DNNs with compositional generalization abilities in a similar way. We conclude by discussing the implications that these findings may have for the study of compositionality in human cognition and by suggesting avenues for future research.
5/27/2024

Large Language Models for Mathematical Reasoning: Progresses and Challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin
0
0
Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
4/8/2024

Towards Truly Zero-shot Compositional Visual Reasoning with LLMs as Programmers
Aleksandar Stani'c, Sergi Caelles, Michael Tschannen
0
0
Visual reasoning is dominated by end-to-end neural networks scaled to billions of model parameters and training examples. However, even the largest models struggle with compositional reasoning, generalization, fine-grained spatial and temporal reasoning, and counting. Visual reasoning with large language models (LLMs) as controllers can, in principle, address these limitations by decomposing the task and solving subtasks by orchestrating a set of (visual) tools. Recently, these models achieved great performance on tasks such as compositional visual question answering, visual grounding, and video temporal reasoning. Nevertheless, in their current form, these models heavily rely on human engineering of in-context examples in the prompt, which are often dataset- and task-specific and require significant labor by highly skilled programmers. In this work, we present a framework that mitigates these issues by introducing spatially and temporally abstract routines and by leveraging a small number of labeled examples to automatically generate in-context examples, thereby avoiding human-created in-context examples. On a number of visual reasoning tasks, we show that our framework leads to consistent gains in performance, makes LLMs as controllers setup more robust, and removes the need for human engineering of in-context examples.
5/16/2024
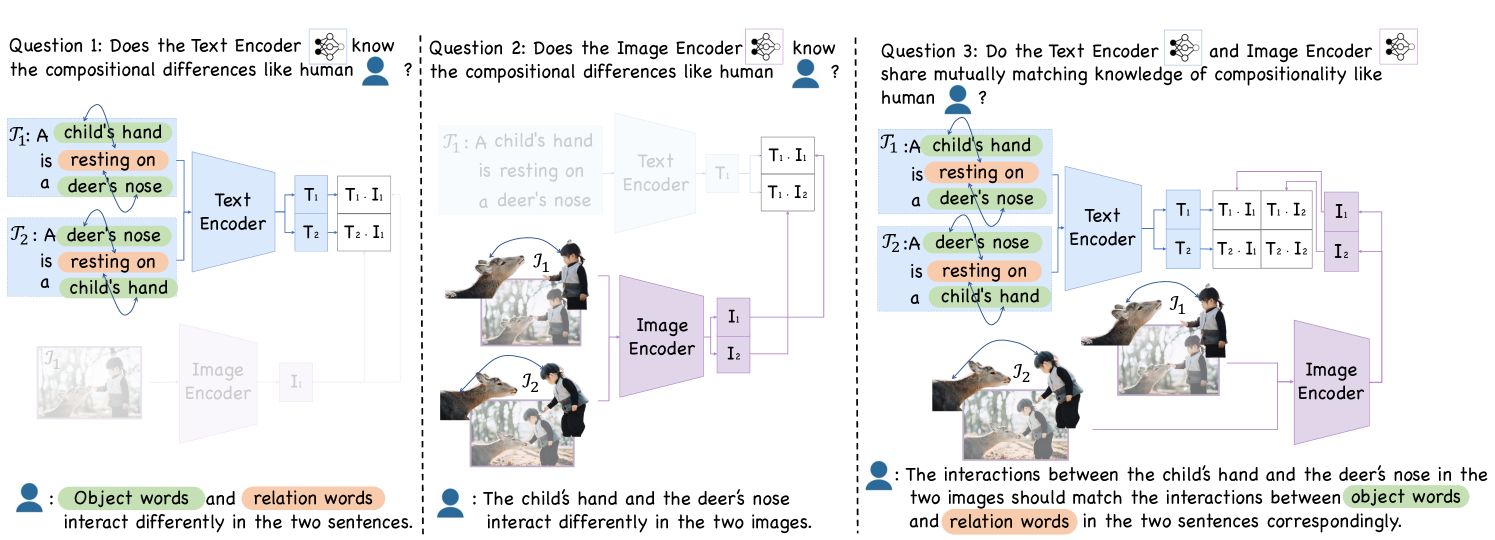
Diagnosing the Compositional Knowledge of Vision Language Models from a Game-Theoretic View
Jin Wang, Shichao Dong, Yapeng Zhu, Kelu Yao, Weidong Zhao, Chao Li, Ping Luo
0
0
Compositional reasoning capabilities are usually considered as fundamental skills to characterize human perception. Recent studies show that current Vision Language Models (VLMs) surprisingly lack sufficient knowledge with respect to such capabilities. To this end, we propose to thoroughly diagnose the composition representations encoded by VLMs, systematically revealing the potential cause for this weakness. Specifically, we propose evaluation methods from a novel game-theoretic view to assess the vulnerability of VLMs on different aspects of compositional understanding, e.g., relations and attributes. Extensive experimental results demonstrate and validate several insights to understand the incapabilities of VLMs on compositional reasoning, which provide useful and reliable guidance for future studies. The deliverables will be updated at https://vlms-compositionality-gametheory.github.io/.
5/28/2024