SimpleFusion: A Simple Fusion Framework for Infrared and Visible Images

0

Sign in to get full access
Overview
- This paper presents a simple and effective framework called SimpleFusion for fusing infrared and visible images.
- The proposed method combines the advantages of infrared and visible images to create a more informative and useful output.
- The framework is designed to be lightweight and efficient, making it suitable for real-world applications.
Plain English Explanation
Infrared and visible images can provide complementary information about a scene, but combining them effectively can be challenging. SimpleFusion: A Simple Fusion Framework for Infrared and Visible Images introduces a straightforward approach to fuse these two types of images.
The key idea is to take the best features from both the infrared and visible images and blend them together. Infrared cameras can see heat sources and provide details that are not visible to the naked eye, while visible cameras capture color and texture information. By combining these, the resulting fused image can be more informative and useful for tasks like surveillance, object detection, and scene understanding.
The SimpleFusion framework is designed to be lightweight and efficient, so it can be used in real-world applications without requiring a lot of computing power. This makes it a practical solution compared to more complex fusion methods.
Technical Explanation
SimpleFusion: A Simple Fusion Framework for Infrared and Visible Images proposes a straightforward approach to combine infrared and visible images. The method first extracts features from the input images using convolutional neural networks. It then applies a fusion module that learns to effectively blend the complementary information from the two modalities.
The fusion module consists of several convolutional and pooling layers that progressively combine the features. This allows the model to adaptively determine which aspects of the infrared and visible inputs should be emphasized in the final fused output.
Experiments on benchmark datasets show that SimpleFusion achieves competitive performance compared to more complex fusion approaches, while being more computationally efficient. This makes it a practical solution for real-world applications that require fast and accurate image fusion, such as UNIRGB-IR: A Unified Framework for Visible and Infrared Downstream Tasks or VIFNet: An End-to-End Visible-Infrared Fusion Network.
Critical Analysis
The SimpleFusion framework presents a straightforward and effective approach to fusing infrared and visible images. However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the method.
One potential concern is that the fusion process may not always be able to perfectly combine the complementary information from the two modalities. In some cases, there may be conflicts or inconsistencies between the infrared and visible data that are not fully resolved by the fusion module.
Additionally, the paper focuses on the performance of the overall fused output, but does not investigate the individual contributions of the infrared and visible inputs. It would be interesting to understand how the method behaves in edge cases or when one modality is significantly more informative than the other.
Despite these potential issues, SimpleFusion represents a valuable addition to the field of image fusion, providing a practical and efficient solution that can be readily deployed in real-world applications.
Conclusion
SimpleFusion: A Simple Fusion Framework for Infrared and Visible Images introduces a straightforward and effective approach to combining infrared and visible images. By leveraging the complementary strengths of these two modalities, the framework can produce fused outputs that are more informative and useful for a variety of computer vision tasks.
The key advantages of SimpleFusion are its simplicity, efficiency, and practical applicability. The lightweight design makes it suitable for deployment in real-world scenarios, while still maintaining competitive performance compared to more complex fusion methods.
Overall, this work represents an important contribution to the field of image fusion, providing a valuable tool for researchers and practitioners working on applications that require the integration of multiple imaging modalities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SimpleFusion: A Simple Fusion Framework for Infrared and Visible Images
Ming Chen, Yuxuan Cheng, Xinwei He, Xinyue Wang, Yan Aze, Jinhai Xiang
Integrating visible and infrared images into one high-quality image, also known as visible and infrared image fusion, is a challenging yet critical task for many downstream vision tasks. Most existing works utilize pretrained deep neural networks or design sophisticated frameworks with strong priors for this task, which may be unsuitable or lack flexibility. This paper presents SimpleFusion, a simple yet effective framework for visible and infrared image fusion. Our framework follows the decompose-and-fusion paradigm, where the visible and the infrared images are decomposed into reflectance and illumination components via Retinex theory and followed by the fusion of these corresponding elements. The whole framework is designed with two plain convolutional neural networks without downsampling, which can perform image decomposition and fusion efficiently. Moreover, we introduce decomposition loss and a detail-to-semantic loss to preserve the complementary information between the two modalities for fusion. We conduct extensive experiments on the challenging benchmarks, verifying the superiority of our method over previous state-of-the-arts. Code is available at href{https://github.com/hxwxss/SimpleFusion-A-Simple-Fusion-Framework-for-Infrared-and-Visible-Images}{https://github.com/hxwxss/SimpleFusion-A-Simple-Fusion-Framework-for-Infrared-and-Visible-Images}
Read more6/28/2024
0
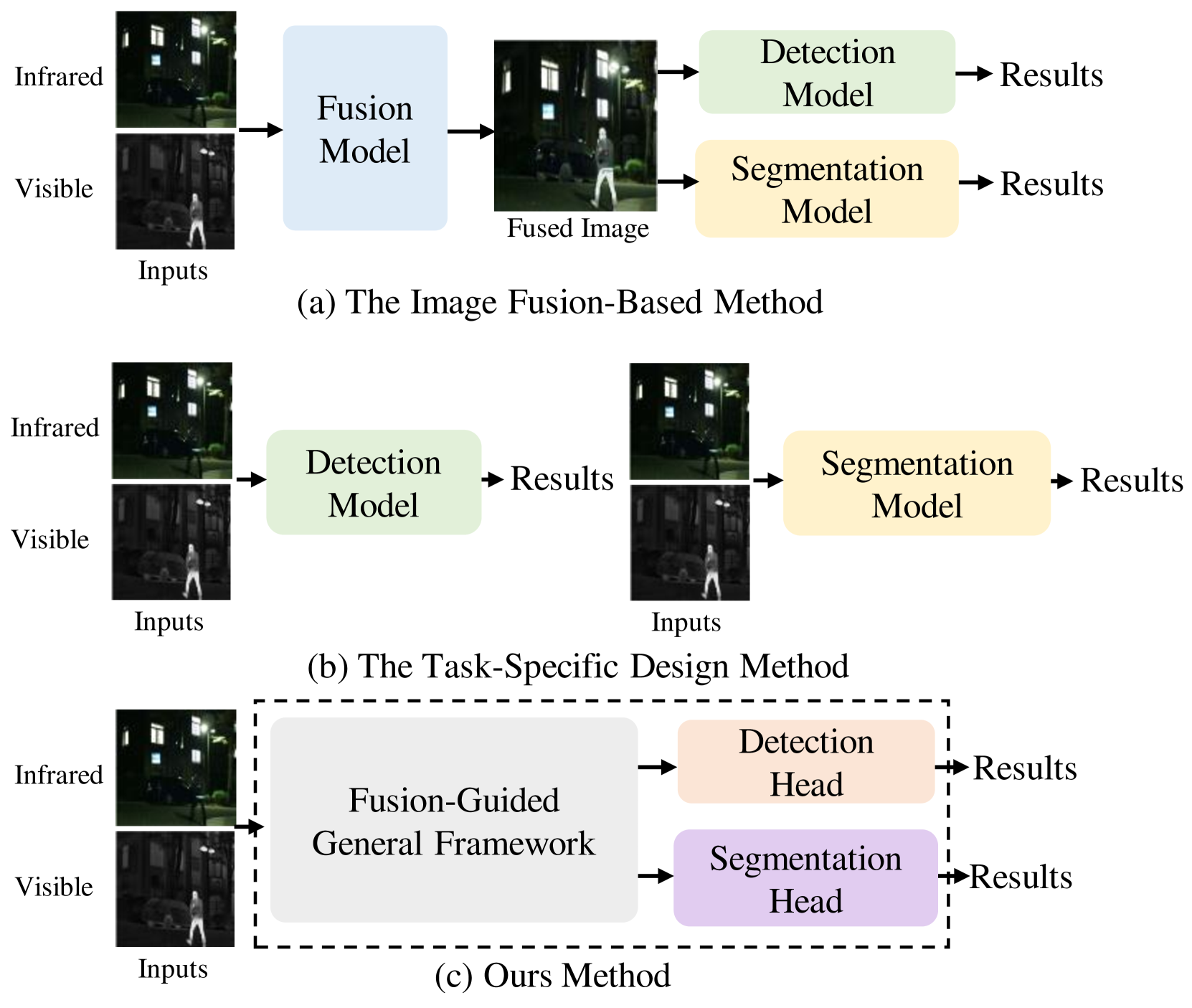
IVGF: The Fusion-Guided Infrared and Visible General Framework
Fangcen Liu, Chenqiang Gao, Fang Chen, Pengcheng Li, Junjie Guo, Deyu Meng
Infrared and visible dual-modality tasks such as semantic segmentation and object detection can achieve robust performance even in extreme scenes by fusing complementary information. Most current methods design task-specific frameworks, which are limited in generalization across multiple tasks. In this paper, we propose a fusion-guided infrared and visible general framework, IVGF, which can be easily extended to many high-level vision tasks. Firstly, we adopt the SOTA infrared and visible foundation models to extract the general representations. Then, to enrich the semantics information of these general representations for high-level vision tasks, we design the feature enhancement module and token enhancement module for feature maps and tokens, respectively. Besides, the attention-guided fusion module is proposed for effectively fusing by exploring the complementary information of two modalities. Moreover, we also adopt the cutout&mix augmentation strategy to conduct the data augmentation, which further improves the ability of the model to mine the regional complementary between the two modalities. Extensive experiments show that the IVGF outperforms state-of-the-art dual-modality methods in the semantic segmentation and object detection tasks. The detailed ablation studies demonstrate the effectiveness of each module, and another experiment explores the anti-missing modality ability of the proposed method in the dual-modality semantic segmentation task.
Read more9/17/2024

0
HSFusion: A high-level vision task-driven infrared and visible image fusion network via semantic and geometric domain transformation
Chengjie Jiang, Xiaowen Liu, Bowen Zheng, Lu Bai, Jing Li
Infrared and visible image fusion has been developed from vision perception oriented fusion methods to strategies which both consider the vision perception and high-level vision task. However, the existing task-driven methods fail to address the domain gap between semantic and geometric representation. To overcome these issues, we propose a high-level vision task-driven infrared and visible image fusion network via semantic and geometric domain transformation, terms as HSFusion. Specifically, to minimize the gap between semantic and geometric representation, we design two separate domain transformation branches by CycleGAN framework, and each includes two processes: the forward segmentation process and the reverse reconstruction process. CycleGAN is capable of learning domain transformation patterns, and the reconstruction process of CycleGAN is conducted under the constraint of these patterns. Thus, our method can significantly facilitate the integration of semantic and geometric information and further reduces the domain gap. In fusion stage, we integrate the infrared and visible features that extracted from the reconstruction process of two seperate CycleGANs to obtain the fused result. These features, containing varying proportions of semantic and geometric information, can significantly enhance the high level vision tasks. Additionally, we generate masks based on segmentation results to guide the fusion task. These masks can provide semantic priors, and we design adaptive weights for two distinct areas in the masks to facilitate image fusion. Finally, we conducted comparative experiments between our method and eleven other state-of-the-art methods, demonstrating that our approach surpasses others in both visual appeal and semantic segmentation task.
Read more7/16/2024

0
Implicit Multi-Spectral Transformer: An Lightweight and Effective Visible to Infrared Image Translation Model
Yijia Chen, Pinghua Chen, Xiangxin Zhou, Yingtie Lei, Ziyang Zhou, Mingxian Li
In the field of computer vision, visible light images often exhibit low contrast in low-light conditions, presenting a significant challenge. While infrared imagery provides a potential solution, its utilization entails high costs and practical limitations. Recent advancements in deep learning, particularly the deployment of Generative Adversarial Networks (GANs), have facilitated the transformation of visible light images to infrared images. However, these methods often experience unstable training phases and may produce suboptimal outputs. To address these issues, we propose a novel end-to-end Transformer-based model that efficiently converts visible light images into high-fidelity infrared images. Initially, the Texture Mapping Module and Color Perception Adapter collaborate to extract texture and color features from the visible light image. The Dynamic Fusion Aggregation Module subsequently integrates these features. Finally, the transformation into an infrared image is refined through the synergistic action of the Color Perception Adapter and the Enhanced Perception Attention mechanism. Comprehensive benchmarking experiments confirm that our model outperforms existing methods, producing infrared images of markedly superior quality, both qualitatively and quantitatively. Furthermore, the proposed model enables more effective downstream applications for infrared images than other methods.
Read more4/30/2024