iVideoGPT: Interactive VideoGPTs are Scalable World Models
2405.15223
0
0

Abstract
World models empower model-based agents to interactively explore, reason, and plan within imagined environments for real-world decision-making. However, the high demand for interactivity poses challenges in harnessing recent advancements in video generative models for developing world models at scale. This work introduces Interactive VideoGPT (iVideoGPT), a scalable autoregressive transformer framework that integrates multimodal signals--visual observations, actions, and rewards--into a sequence of tokens, facilitating an interactive experience of agents via next-token prediction. iVideoGPT features a novel compressive tokenization technique that efficiently discretizes high-dimensional visual observations. Leveraging its scalable architecture, we are able to pre-train iVideoGPT on millions of human and robotic manipulation trajectories, establishing a versatile foundation that is adaptable to serve as interactive world models for a wide range of downstream tasks. These include action-conditioned video prediction, visual planning, and model-based reinforcement learning, where iVideoGPT achieves competitive performance compared with state-of-the-art methods. Our work advances the development of interactive general world models, bridging the gap between generative video models and practical model-based reinforcement learning applications.
Create account to get full access
Overview
- The paper introduces iVideoGPT, a novel approach to scaling up interactive video models using generative language models (LLMs).
- iVideoGPT combines a video model with an LLM to create a scalable world model that can interact with and reason about videos in a flexible, open-ended way.
- The authors demonstrate how iVideoGPT can be used for tasks like visual question answering, video captioning, and video manipulation, showcasing its versatility and capabilities.
Plain English Explanation
The paper presents a new system called iVideoGPT that aims to make video models more powerful and flexible. Typically, video models can only handle certain predefined tasks, like recognizing objects or describing what's happening in a video.
iVideoGPT takes a different approach by combining a video model with a large language model (LLM). LLMs are AI systems trained on massive amounts of text data, which allows them to understand and generate human-like language. By combining the video model with an LLM, iVideoGPT creates a "world model" that can interact with and reason about videos in more open-ended, conversational ways.
For example, with iVideoGPT you could ask questions about a video, give instructions to manipulate or edit the video, or even have a back-and-forth dialogue about the video's content. This makes iVideoGPT much more versatile than traditional video models, which are limited to specific pre-programmed tasks.
The authors demonstrate iVideoGPT's capabilities through a variety of experiments, showing how it can be used for things like visual question answering, video captioning, and even generating new videos based on text prompts. Overall, the aim of iVideoGPT is to create more scalable and interactive video models that can engage with the world in more natural, human-like ways.
Technical Explanation
The core idea behind iVideoGPT is to combine a video model with a large language model (LLM) to create a more flexible and scalable "world model" for interacting with video data.
The authors start by training a video model on a large dataset of videos, which allows the model to understand and reason about the visual content. They then integrate this video model with a state-of-the-art LLM, such as GPT-4 or MiniGPT-4, to create the iVideoGPT system.
The LLM provides the ability to engage in open-ended language interactions, while the video model contributes the visual understanding. Together, iVideoGPT can perform a wide range of video-related tasks, such as answering questions about video content, generating video captions, and even manipulating or editing videos based on text instructions.
The authors evaluate iVideoGPT on several benchmark tasks, demonstrating its strong performance compared to existing video models. They also showcase iVideoGPT's versatility by demonstrating its use in more interactive and open-ended scenarios, such as engaging in dialogues about video content and generating new videos from text prompts.
Critical Analysis
The iVideoGPT approach is a promising step towards more scalable and versatile video models. By integrating an LLM with a video model, the authors have created a system that can engage with video data in a much more flexible and natural way than traditional video models.
One potential limitation, however, is the computational and memory requirements of the combined iVideoGPT model, which may make it challenging to deploy at scale. The authors mention that they used techniques like prompt engineering and model distillation to mitigate these issues, but the scalability of iVideoGPT in real-world applications remains an area for further research.
Additionally, while the authors demonstrate impressive results on a range of tasks, the paper does not provide a thorough analysis of the system's limitations or failure modes. It would be useful to understand the types of situations where iVideoGPT may struggle or produce unreliable outputs, as this would help researchers and practitioners better assess its practical applicability.
Overall, the iVideoGPT approach represents an exciting step forward in video modeling, and the authors have made a compelling case for the value of integrating language models with video understanding. As research in this area continues to evolve, it will be interesting to see how these types of multimodal systems can be further refined and deployed to tackle increasingly complex real-world challenges.
Conclusion
The iVideoGPT paper introduces a novel approach to scaling up interactive video models by combining them with powerful language models. By integrating a video model with a large language model (LLM), the authors have created a "world model" that can engage with video data in more flexible, open-ended ways than traditional video models.
The key innovation of iVideoGPT is its ability to leverage the language understanding and generation capabilities of LLMs to enable more natural and versatile interactions with video content. This allows iVideoGPT to perform a wide range of tasks, from visual question answering to video captioning and manipulation, showcasing its potential for real-world applications.
While the paper highlights the impressive performance of iVideoGPT, it also raises questions about the scalability and robustness of the system. As research in this area continues to evolve, it will be important to further explore the limitations and failure modes of these types of multimodal models, as well as how they can be optimized for deployment at scale.
Overall, the iVideoGPT approach represents an exciting step forward in the development of more flexible and intelligent video understanding systems. As AI continues to advance, the integration of language models with other modalities, such as vision and audio, will likely play a crucial role in creating the next generation of scalable, interactive world models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, Fahad Shahbaz Khan
0
0
Conversation agents fueled by Large Language Models (LLMs) are providing a new way to interact with visual data. While there have been initial attempts for image-based conversation models, this work addresses the under-explored field of emph{video-based conversation} by introducing Video-ChatGPT. It is a multimodal model that merges a video-adapted visual encoder with an LLM. The resulting model is capable of understanding and generating detailed conversations about videos. We introduce a new dataset of 100,000 video-instruction pairs used to train Video-ChatGPT acquired via manual and semi-automated pipeline that is easily scalable and robust to label noise. We also develop a quantitative evaluation framework for video-based dialogue models to objectively analyze the strengths and weaknesses of video-based dialogue models. Code: https://github.com/mbzuai-oryx/Video-ChatGPT.
6/11/2024
ViD-GPT: Introducing GPT-style Autoregressive Generation in Video Diffusion Models
Kaifeng Gao, Jiaxin Shi, Hanwang Zhang, Chunping Wang, Jun Xiao
0
0
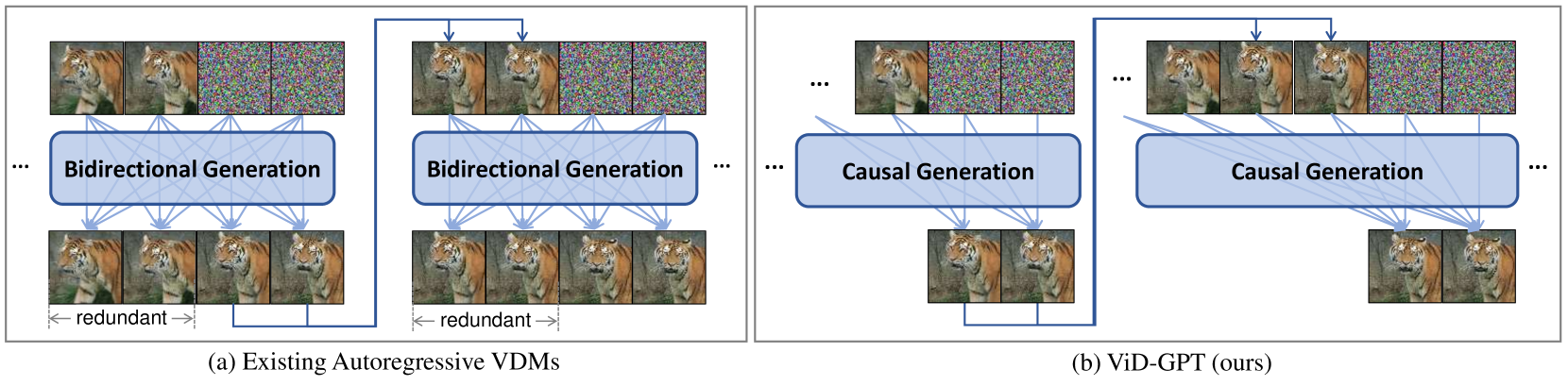
With the advance of diffusion models, today's video generation has achieved impressive quality. But generating temporal consistent long videos is still challenging. A majority of video diffusion models (VDMs) generate long videos in an autoregressive manner, i.e., generating subsequent clips conditioned on last frames of previous clip. However, existing approaches all involve bidirectional computations, which restricts the receptive context of each autoregression step, and results in the model lacking long-term dependencies. Inspired from the huge success of large language models (LLMs) and following GPT (generative pre-trained transformer), we bring causal (i.e., unidirectional) generation into VDMs, and use past frames as prompt to generate future frames. For Causal Generation, we introduce causal temporal attention into VDM, which forces each generated frame to depend on its previous frames. For Frame as Prompt, we inject the conditional frames by concatenating them with noisy frames (frames to be generated) along the temporal axis. Consequently, we present Video Diffusion GPT (ViD-GPT). Based on the two key designs, in each autoregression step, it is able to acquire long-term context from prompting frames concatenated by all previously generated frames. Additionally, we bring the kv-cache mechanism to VDMs, which eliminates the redundant computation from overlapped frames, significantly boosting the inference speed. Extensive experiments demonstrate that our ViD-GPT achieves state-of-the-art performance both quantitatively and qualitatively on long video generation. Code will be available at https://github.com/Dawn-LX/Causal-VideoGen.
6/18/2024
📈
WorldGPT: Empowering LLM as Multimodal World Model
Zhiqi Ge, Hongzhe Huang, Mingze Zhou, Juncheng Li, Guoming Wang, Siliang Tang, Yueting Zhuang
0
0
World models are progressively being employed across diverse fields, extending from basic environment simulation to complex scenario construction. However, existing models are mainly trained on domain-specific states and actions, and confined to single-modality state representations. In this paper, We introduce WorldGPT, a generalist world model built upon Multimodal Large Language Model (MLLM). WorldGPT acquires an understanding of world dynamics through analyzing millions of videos across various domains. To further enhance WorldGPT's capability in specialized scenarios and long-term tasks, we have integrated it with a novel cognitive architecture that combines memory offloading, knowledge retrieval, and context reflection. As for evaluation, we build WorldNet, a multimodal state transition prediction benchmark encompassing varied real-life scenarios. Conducting evaluations on WorldNet directly demonstrates WorldGPT's capability to accurately model state transition patterns, affirming its effectiveness in understanding and predicting the dynamics of complex scenarios. We further explore WorldGPT's emerging potential in serving as a world simulator, helping multimodal agents generalize to unfamiliar domains through efficiently synthesising multimodal instruction instances which are proved to be as reliable as authentic data for fine-tuning purposes. The project is available on url{https://github.com/DCDmllm/WorldGPT}.
4/30/2024
VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding
Muhammad Maaz, Hanoona Rasheed, Salman Khan, Fahad Khan
0
0
Building on the advances of language models, Large Multimodal Models (LMMs) have contributed significant improvements in video understanding. While the current video LMMs utilize advanced Large Language Models (LLMs), they rely on either image or video encoders to process visual inputs, each of which has its own limitations. Image encoders excel at capturing rich spatial details from frame sequences but lack explicit temporal context, which can be important in videos with intricate action sequences. On the other hand, video encoders provide temporal context but are often limited by computational constraints that lead to processing only sparse frames at lower resolutions, resulting in reduced contextual and spatial understanding. To this end, we introduce VideoGPT+, which combines the complementary benefits of the image encoder (for detailed spatial understanding) and the video encoder (for global temporal context modeling). The model processes videos by dividing them into smaller segments and applies an adaptive pooling strategy on features extracted by both image and video encoders. Our architecture showcases improved performance across multiple video benchmarks, including VCGBench, MVBench and Zero-shot question-answering. Further, we develop 112K video-instruction set using a novel semi-automatic annotation pipeline which further improves the model performance. Additionally, to comprehensively evaluate video LMMs, we present VCGBench-Diverse, covering 18 broad video categories such as lifestyle, sports, science, gaming, and surveillance videos. This benchmark with 4,354 question-answer pairs evaluates the generalization of existing LMMs on dense video captioning, spatial and temporal understanding, and complex reasoning, ensuring comprehensive assessment across diverse video types and dynamics. Code: https://github.com/mbzuai-oryx/VideoGPT-plus.
6/14/2024