Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
2306.05424
0
0
🤔
Abstract
Conversation agents fueled by Large Language Models (LLMs) are providing a new way to interact with visual data. While there have been initial attempts for image-based conversation models, this work addresses the under-explored field of emph{video-based conversation} by introducing Video-ChatGPT. It is a multimodal model that merges a video-adapted visual encoder with an LLM. The resulting model is capable of understanding and generating detailed conversations about videos. We introduce a new dataset of 100,000 video-instruction pairs used to train Video-ChatGPT acquired via manual and semi-automated pipeline that is easily scalable and robust to label noise. We also develop a quantitative evaluation framework for video-based dialogue models to objectively analyze the strengths and weaknesses of video-based dialogue models. Code: https://github.com/mbzuai-oryx/Video-ChatGPT.
Create account to get full access
Overview
- This paper introduces a new model called Video-ChatGPT, which combines a video-adapted visual encoder with a large language model (LLM) to enable detailed conversations about videos.
- The researchers created a dataset of 100,000 video-instruction pairs to train Video-ChatGPT, using a scalable pipeline to acquire the data.
- They also developed a quantitative evaluation framework to analyze the strengths and weaknesses of video-based dialogue models.
Plain English Explanation
The paper describes a new way to interact with videos using a model called Video-ChatGPT. This model combines a visual encoder that has been adapted to work with videos, with a powerful language model (an LLM) that can understand and generate detailed text.
The key idea is to create a system that can truly understand the content of a video and have a natural conversation about it, going beyond simple captions or descriptions. For example, you could show the model a video of someone assembling furniture, and it could engage in a back-and-forth dialog with you about the steps, materials, and techniques used.
To train this model, the researchers built a dataset of 100,000 video-instruction pairs. This means they collected a large number of videos, each paired with a set of instructions or explanations about the video's content. They used a combination of manual and semi-automated methods to build this dataset in a scalable way.
In addition, the researchers developed a new way to evaluate the performance of video-based dialogue models. This allows them to objectively assess the strengths and weaknesses of these models, which is important for continued progress in this area.
Technical Explanation
The core of this work is the Video-ChatGPT model, which merges a video-adapted visual encoder with a large language model (LLM). The visual encoder takes in video data and extracts relevant visual features, while the LLM can understand and generate detailed text.
By combining these two components, Video-ChatGPT is able to engage in natural conversations about the content of videos. This goes beyond simpler tasks like video captioning or video question answering, as the model can participate in a back-and-forth dialog about the video.
To train Video-ChatGPT, the researchers created a new dataset of 100,000 video-instruction pairs. This was done through a combination of manual and semi-automated methods, leveraging existing video datasets and crowdsourcing to efficiently scale up the data collection process.
The researchers also developed a quantitative evaluation framework for video-based dialogue models. This allows them to analyze the strengths and weaknesses of these models in a more objective way, going beyond simple metrics like video captioning performance.
Critical Analysis
One potential limitation of this work is the reliance on a manually-created dataset of video-instruction pairs. While the researchers describe a scalable pipeline, building a truly large-scale dataset of this nature could be challenging. Alternative approaches, such as retrieval-enhanced zero-shot video captioning, may be worth exploring to further expand the data available for training video-based dialogue models.
Additionally, the researchers do not delve deeply into the specific architectural choices and training procedures used for Video-ChatGPT. More details on these elements could help the community better understand the model's inner workings and potential areas for improvement.
That said, the development of a quantitative evaluation framework for video-based dialogue models is a valuable contribution. This type of rigorous, objective assessment will be crucial for driving progress in this emerging field.
Conclusion
This paper introduces Video-ChatGPT, a novel model that combines a video-adapted visual encoder with a powerful language model to enable natural conversations about video content. The researchers created a large dataset of video-instruction pairs and developed a quantitative evaluation framework to assess video-based dialogue models.
This work represents an important step forward in the field of multimodal language models, demonstrating the potential for AI systems to engage in rich, contextual interactions with visual data. As the research in this area continues to evolve, we can expect to see increasingly sophisticated and natural ways for humans to communicate with and understand the visual world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding
Muhammad Maaz, Hanoona Rasheed, Salman Khan, Fahad Khan
0
0
Building on the advances of language models, Large Multimodal Models (LMMs) have contributed significant improvements in video understanding. While the current video LMMs utilize advanced Large Language Models (LLMs), they rely on either image or video encoders to process visual inputs, each of which has its own limitations. Image encoders excel at capturing rich spatial details from frame sequences but lack explicit temporal context, which can be important in videos with intricate action sequences. On the other hand, video encoders provide temporal context but are often limited by computational constraints that lead to processing only sparse frames at lower resolutions, resulting in reduced contextual and spatial understanding. To this end, we introduce VideoGPT+, which combines the complementary benefits of the image encoder (for detailed spatial understanding) and the video encoder (for global temporal context modeling). The model processes videos by dividing them into smaller segments and applies an adaptive pooling strategy on features extracted by both image and video encoders. Our architecture showcases improved performance across multiple video benchmarks, including VCGBench, MVBench and Zero-shot question-answering. Further, we develop 112K video-instruction set using a novel semi-automatic annotation pipeline which further improves the model performance. Additionally, to comprehensively evaluate video LMMs, we present VCGBench-Diverse, covering 18 broad video categories such as lifestyle, sports, science, gaming, and surveillance videos. This benchmark with 4,354 question-answer pairs evaluates the generalization of existing LMMs on dense video captioning, spatial and temporal understanding, and complex reasoning, ensuring comprehensive assessment across diverse video types and dynamics. Code: https://github.com/mbzuai-oryx/VideoGPT-plus.
6/14/2024

MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies
Zhende Song, Chenchen Wang, Jiamu Sheng, Chi Zhang, Gang Yu, Jiayuan Fan, Tao Chen
0
0
Development of multimodal models has marked a significant step forward in how machines understand videos. These models have shown promise in analyzing short video clips. However, when it comes to longer formats like movies, they often fall short. The main hurdles are the lack of high-quality, diverse video data and the intensive work required to collect or annotate such data. In face of these challenges, we propose MovieLLM, a novel framework designed to synthesize consistent and high-quality video data for instruction tuning. The pipeline is carefully designed to control the style of videos by improving textual inversion technique with powerful text generation capability of GPT-4. As the first framework to do such thing, our approach stands out for its flexibility and scalability, empowering users to create customized movies with only one description. This makes it a superior alternative to traditional data collection methods. Our extensive experiments validate that the data produced by MovieLLM significantly improves the performance of multimodal models in understanding complex video narratives, overcoming the limitations of existing datasets regarding scarcity and bias.
6/26/2024
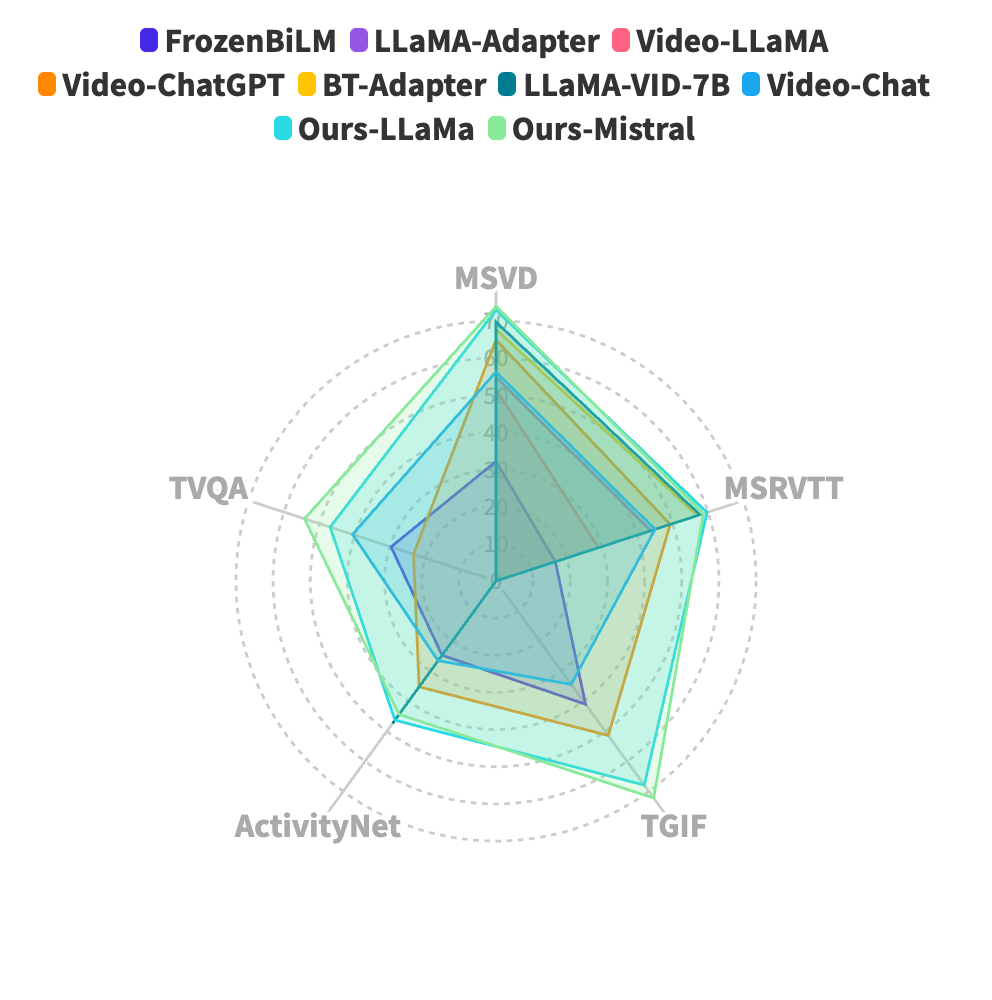
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Deyao Zhu, Jian Ding, Mohamed Elhoseiny
0
0
This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
4/5/2024

VideoLLM-online: Online Video Large Language Model for Streaming Video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, Mike Zheng Shou
0
0
Recent Large Language Models have been enhanced with vision capabilities, enabling them to comprehend images, videos, and interleaved vision-language content. However, the learning methods of these large multimodal models typically treat videos as predetermined clips, making them less effective and efficient at handling streaming video inputs. In this paper, we propose a novel Learning-In-Video-Stream (LIVE) framework, which enables temporally aligned, long-context, and real-time conversation within a continuous video stream. Our LIVE framework comprises comprehensive approaches to achieve video streaming dialogue, encompassing: (1) a training objective designed to perform language modeling for continuous streaming inputs, (2) a data generation scheme that converts offline temporal annotations into a streaming dialogue format, and (3) an optimized inference pipeline to speed up the model responses in real-world video streams. With our LIVE framework, we built VideoLLM-online model upon Llama-2/Llama-3 and demonstrate its significant advantages in processing streaming videos. For instance, on average, our model can support streaming dialogue in a 5-minute video clip at over 10 FPS on an A100 GPU. Moreover, it also showcases state-of-the-art performance on public offline video benchmarks, such as recognition, captioning, and forecasting. The code, model, data, and demo have been made available at https://showlab.github.io/videollm-online.
6/18/2024