VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding
2406.09418
0
0
Abstract
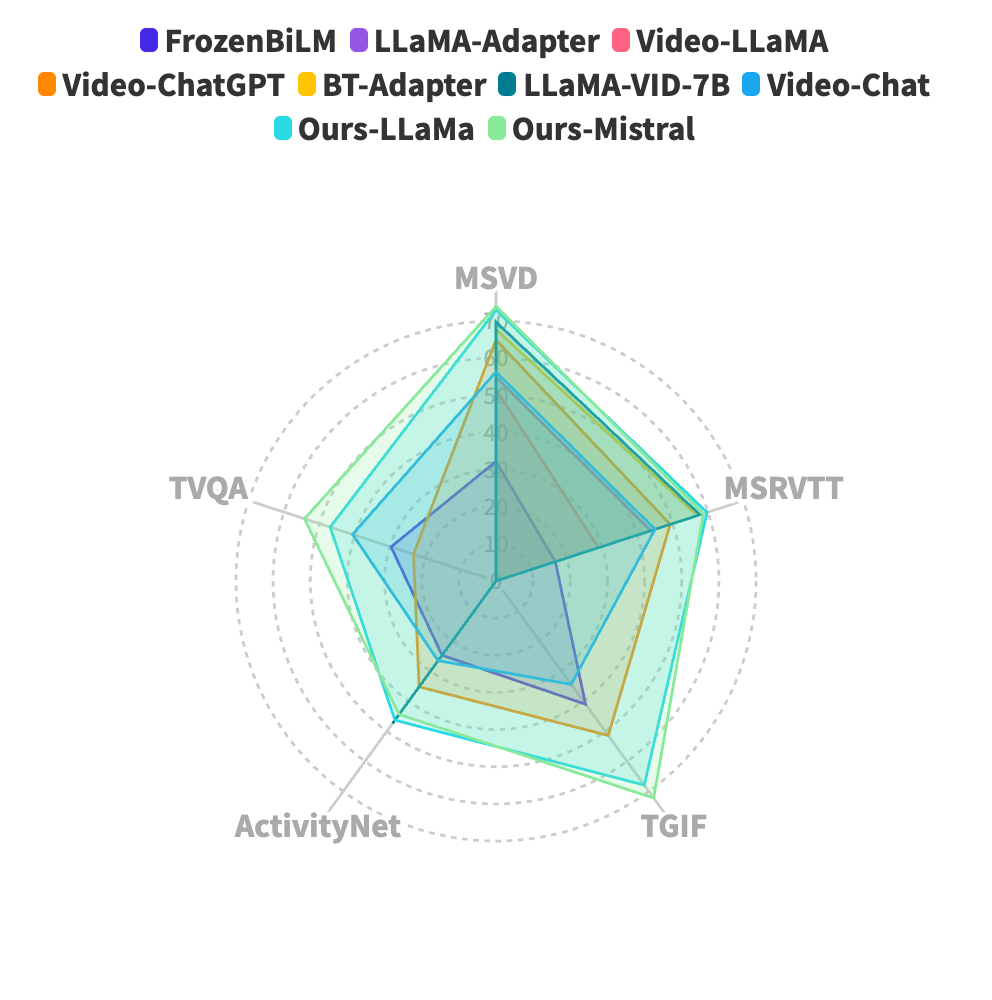
Building on the advances of language models, Large Multimodal Models (LMMs) have contributed significant improvements in video understanding. While the current video LMMs utilize advanced Large Language Models (LLMs), they rely on either image or video encoders to process visual inputs, each of which has its own limitations. Image encoders excel at capturing rich spatial details from frame sequences but lack explicit temporal context, which can be important in videos with intricate action sequences. On the other hand, video encoders provide temporal context but are often limited by computational constraints that lead to processing only sparse frames at lower resolutions, resulting in reduced contextual and spatial understanding. To this end, we introduce VideoGPT+, which combines the complementary benefits of the image encoder (for detailed spatial understanding) and the video encoder (for global temporal context modeling). The model processes videos by dividing them into smaller segments and applies an adaptive pooling strategy on features extracted by both image and video encoders. Our architecture showcases improved performance across multiple video benchmarks, including VCGBench, MVBench and Zero-shot question-answering. Further, we develop 112K video-instruction set using a novel semi-automatic annotation pipeline which further improves the model performance. Additionally, to comprehensively evaluate video LMMs, we present VCGBench-Diverse, covering 18 broad video categories such as lifestyle, sports, science, gaming, and surveillance videos. This benchmark with 4,354 question-answer pairs evaluates the generalization of existing LMMs on dense video captioning, spatial and temporal understanding, and complex reasoning, ensuring comprehensive assessment across diverse video types and dynamics. Code: https://github.com/mbzuai-oryx/VideoGPT-plus.
Create account to get full access
Overview
- The paper "VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding" explores a novel approach to improve video understanding by combining image and video encoding techniques.
- The researchers aim to leverage the complementary strengths of image and video encoders to enhance the performance of various video-related tasks, such as video classification, action recognition, and video captioning.
Plain English Explanation
The researchers behind this study recognized that while image and video encoders have their own unique capabilities, integrating them could lead to even more powerful video understanding. Image-to-video and video-language models have shown promise in this area, and the team wanted to build on these advancements.
The core idea is to take the best of both worlds - the rich spatial understanding from image encoders and the temporal dynamics captured by video encoders - and combine them in a way that enhances the overall performance on various video-related tasks. This could help systems better comprehend the complete context and meaning of video content, going beyond what either type of encoder could do alone.
Technical Explanation
The paper proposes the "VideoGPT+" model, which integrates image and video encoding components. The image encoder extracts spatial features from individual frames, while the video encoder captures the temporal evolution of the video sequence. These complementary representations are then fused and fed into a shared transformer-based architecture for downstream tasks.
The researchers explored different fusion strategies, such as early, middle, and late fusion, to determine the optimal way to combine the image and video features. They also experimented with various transformer-based architectures, including VideoGPT, MiniGPT-4, and LongVLM, to find the most effective approach for video understanding.
Through extensive experiments on benchmark datasets, the team demonstrated that the VideoGPT+ model outperforms state-of-the-art approaches on a variety of video-related tasks, showcasing the benefits of integrating image and video encoders for enhanced video understanding.
Critical Analysis
The paper presents a well-designed and thorough study, exploring different fusion strategies and transformer-based architectures to maximize the synergies between image and video encoders. However, the authors acknowledge that the proposed approach may still have limitations, particularly when dealing with longer video sequences or more complex video understanding tasks.
Additionally, the paper does not delve deeply into the interpretability and explainability of the VideoGPT+ model, which could be an important consideration for real-world applications where understanding the model's decision-making process is crucial.
Further research could explore ways to address these limitations, such as incorporating specialized modules or techniques to handle longer videos, or investigating methods to improve the interpretability of the integrated image-video encoding approach.
Conclusion
The "VideoGPT+" paper presents a innovative approach to enhance video understanding by integrating image and video encoders. By leveraging the complementary strengths of these two encoding techniques, the researchers have demonstrated improved performance on a variety of video-related tasks, opening up new possibilities for more advanced video understanding systems.
The findings from this study contribute to the ongoing efforts in the field of video-language models and long-form video understanding, highlighting the value of combining different modalities to unlock the full potential of video data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, Fahad Shahbaz Khan
0
0
Conversation agents fueled by Large Language Models (LLMs) are providing a new way to interact with visual data. While there have been initial attempts for image-based conversation models, this work addresses the under-explored field of emph{video-based conversation} by introducing Video-ChatGPT. It is a multimodal model that merges a video-adapted visual encoder with an LLM. The resulting model is capable of understanding and generating detailed conversations about videos. We introduce a new dataset of 100,000 video-instruction pairs used to train Video-ChatGPT acquired via manual and semi-automated pipeline that is easily scalable and robust to label noise. We also develop a quantitative evaluation framework for video-based dialogue models to objectively analyze the strengths and weaknesses of video-based dialogue models. Code: https://github.com/mbzuai-oryx/Video-ChatGPT.
6/11/2024
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Deyao Zhu, Jian Ding, Mohamed Elhoseiny
0
0
This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
4/5/2024
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
0
0
Empowered by Large Language Models (LLMs), recent advancements in VideoLLMs have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding in videos due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a straightforward yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each local segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples demonstrate that our model produces more precise responses for long videos understanding. Code will be available at https://github.com/ziplab/LongVLM.
4/11/2024
📊
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
Yang Jin, Zhicheng Sun, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yuliang Liu, Di Zhang, Yang Song, Kun Gai, Yadong Mu
0
0
In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos. Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions. These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content. Our proposed framework is both capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation. Our code and models are available at https://video-lavit.github.io.
6/4/2024