MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
2404.03413
0
0
Abstract
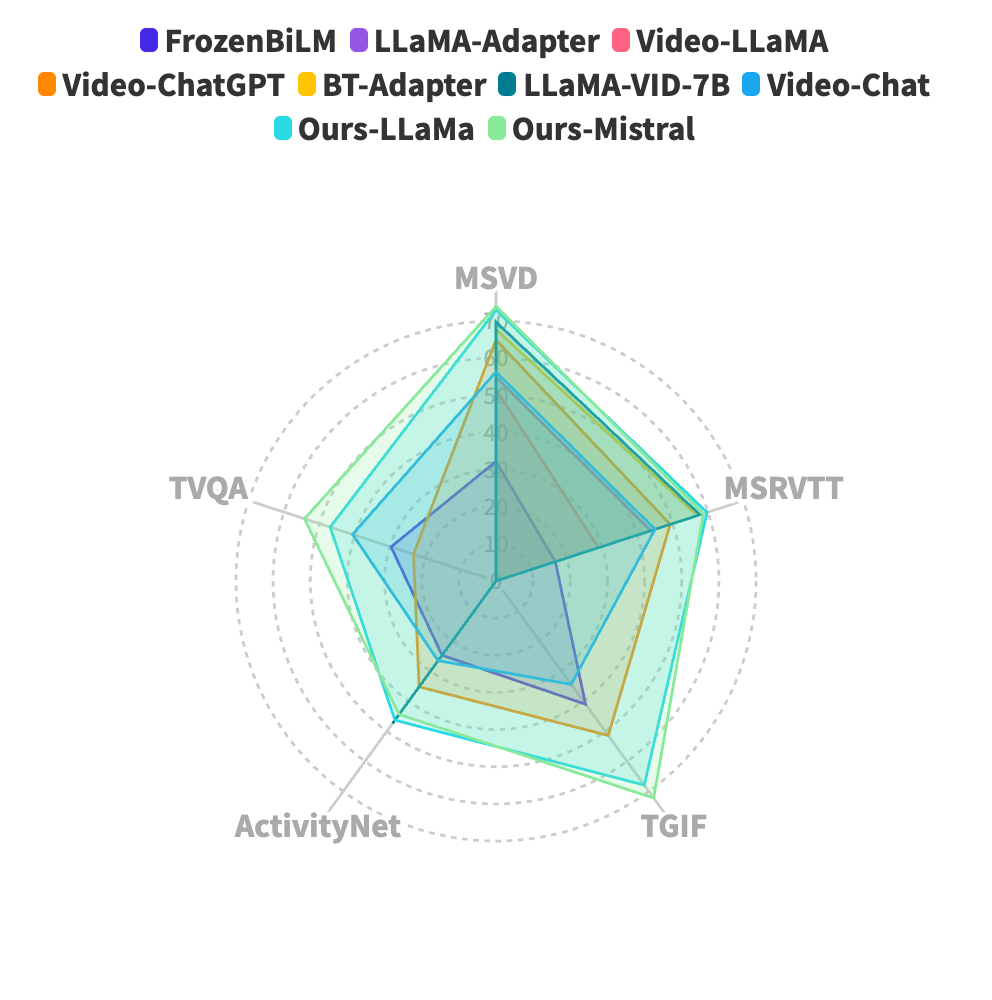
This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces MiniGPT4-Video, a new multimodal large language model (LLM) that can understand and reason about video content.
- The key innovation is the use of "interleaved visual-textual tokens" that allow the model to jointly process both visual and textual information.
- Experiments show that MiniGPT4-Video outperforms previous state-of-the-art models on various video understanding tasks, demonstrating the potential of this approach.
Plain English Explanation
MiniGPT4-Video is a new artificial intelligence system that can understand and analyze video content. Traditional AI models have struggled with this, as they typically focus on processing either visual information (like images) or textual information (like captions), but not both together.
The researchers behind MiniGPT4-Video have come up with a clever solution to this problem. They've created a system that can process both the visual and textual elements of a video simultaneously, using what they call "interleaved visual-textual tokens." This allows the model to build a more complete understanding of the video content, considering both the images and the accompanying text or dialogue.
By combining these two modalities, MiniGPT4-Video is able to outperform previous state-of-the-art models on a variety of video understanding tasks. For example, it can better answer questions about the plot and events in a video, or provide more accurate summaries of the content.
This is an important advance, as the ability to deeply understand video content has many potential applications, from improving video search and recommendation systems to enabling more natural interactions with virtual assistants. MiniGPT4-Video represents a step towards making AI systems that can truly comprehend the rich, multimodal information contained in videos.
Technical Explanation
MiniGPT4-Video is a new multimodal large language model (LLM) that has been designed to understand and reason about video content. The key innovation is the use of "interleaved visual-textual tokens" that allow the model to jointly process both the visual and textual information in a video.
Traditionally, video understanding models have struggled to fully capture the rich, multimodal nature of video content, as they have typically focused on either the visual or textual modality, but not both. MiniGPT4-Video addresses this by transforming LLMs into cross-modal and cross-lingual models that can seamlessly integrate and reason about both visual and textual inputs.
The architecture of MiniGPT4-Video is based on the GPT-4 language model, but with several key modifications. First, the model is pre-trained on a large corpus of video data, allowing it to build a strong understanding of the visual and textual patterns found in videos. Second, the input to the model is a sequence of interleaved visual and textual tokens, which are processed by the model's attention mechanisms to build a unified representation.
Experiments show that MiniGPT4-Video outperforms previous state-of-the-art models on a variety of video understanding tasks, including video question answering, video captioning, and video summarization. This demonstrates the power of the interleaved visual-textual token approach in enabling the model to deeply comprehend the multimodal nature of video content.
Critical Analysis
The MiniGPT4-Video model represents an exciting advancement in the field of video understanding, but it is important to consider some potential limitations and areas for further research.
One key concern is the scalability of the approach. While the interleaved visual-textual tokens allow the model to jointly process both modalities, the computational complexity of this approach may limit its applicability to longer or more complex videos. The researchers acknowledge this issue and suggest that further work is needed to improve the efficiency of the model.
Additionally, the paper does not provide a detailed analysis of the model's performance on specific video understanding tasks or on different types of video content. It would be valuable to understand how the model's capabilities vary across different domains or scenarios, and whether there are any biases or limitations in its understanding.
Further research could also explore ways to make the model more interpretable, so that users can better understand the reasoning behind its outputs. This could involve developing techniques to visualize the model's internal representations or to explain its decision-making process.
Despite these potential areas for improvement, the MiniGPT4-Video model represents an important step forward in the quest to build AI systems that can truly comprehend the richness of video content. As the field of multimodal learning continues to advance, we can expect to see even more powerful and versatile video understanding models in the future.
Conclusion
MiniGPT4-Video is a groundbreaking new multimodal large language model that can understand and reason about video content by jointly processing both visual and textual information. The key innovation is the use of "interleaved visual-textual tokens" that allow the model to build a more comprehensive understanding of the video.
Experiments show that MiniGPT4-Video outperforms previous state-of-the-art models on a variety of video understanding tasks, demonstrating the power of this approach. This represents an important step forward in the quest to build AI systems that can truly comprehend the rich, multimodal nature of video content, with potential applications ranging from improved video search and recommendation to more natural interactions with virtual assistants.
While the MiniGPT4-Video model has some potential limitations, such as scalability and interpretability, the research team has produced a compelling demonstration of the value of combining visual and textual information for video understanding. As the field of multimodal learning continues to advance, we can expect to see even more innovative and powerful video understanding models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
Zhengqing Yuan, Zhaoxu Li, Weiran Huang, Yanfang Ye, Lichao Sun
0
0
In recent years, multimodal large language models (MLLMs) such as GPT-4V have demonstrated remarkable advancements, excelling in a variety of vision-language tasks. Despite their prowess, the closed-source nature and computational demands of such models limit their accessibility and applicability. This study introduces TinyGPT-V, a novel open-source MLLM, designed for efficient training and inference across various vision-language tasks, including image captioning (IC) and visual question answering (VQA). Leveraging a compact yet powerful architecture, TinyGPT-V integrates the Phi-2 language model with pre-trained vision encoders, utilizing a unique mapping module for visual and linguistic information fusion. With a training regimen optimized for small backbones and employing a diverse dataset amalgam, TinyGPT-V requires significantly lower computational resources 24GB for training and as little as 8GB for inference without compromising on performance. Our experiments demonstrate that TinyGPT-V, with its language model 2.8 billion parameters, achieves comparable results in VQA and image inference tasks to its larger counterparts while being uniquely suited for deployment on resource-constrained devices through innovative quantization techniques. This work not only paves the way for more accessible and efficient MLLMs but also underscores the potential of smaller, optimized models in bridging the gap between high performance and computational efficiency in real-world applications. Additionally, this paper introduces a new approach to multimodal large language models using smaller backbones. Our code and training weights are available in url{https://github.com/DLYuanGod/TinyGPT-V}.
4/8/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
From Image to Video, what do we need in multimodal LLMs?
Suyuan Huang, Haoxin Zhang, Yan Gao, Yao Hu, Zengchang Qin
0
0
Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.
4/19/2024
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
0
0
Empowered by Large Language Models (LLMs), recent advancements in VideoLLMs have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding in videos due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a straightforward yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each local segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples demonstrate that our model produces more precise responses for long videos understanding. Code will be available at https://github.com/ziplab/LongVLM.
4/11/2024