iWISDM: Assessing instruction following in multimodal models at scale

0
Sign in to get full access
Overview
- This paper introduces iWISDM, a framework for assessing instruction following in multimodal language models at scale.
- The framework includes a dataset of over 1 million annotated multimodal instructions, as well as evaluation metrics and baseline models to measure instruction following performance.
- The authors conduct extensive experiments to analyze the capabilities and limitations of state-of-the-art multimodal models on this new benchmark.
Plain English Explanation
The paper discusses a new way to evaluate how well AI models can follow instructions that combine text and images. The researchers created a large dataset of over 1 million annotated instructions, which could involve things like cooking a recipe or assembling furniture. They then used this dataset to test the abilities of various AI models that can process both text and images.
The key idea is to have a standardized way to assess how well these "multimodal" AI models can understand and carry out the step-by-step instructions. This is an important capability, as many real-world tasks require interpreting both visual and textual information.
The paper provides detailed analyses of how well different AI models perform on this benchmark. This helps uncover the strengths and limitations of current state-of-the-art models when it comes to following multimodal instructions. The findings could inform the development of more capable AI assistants that can better understand and complete complex, multimedia-based tasks.
Technical Explanation
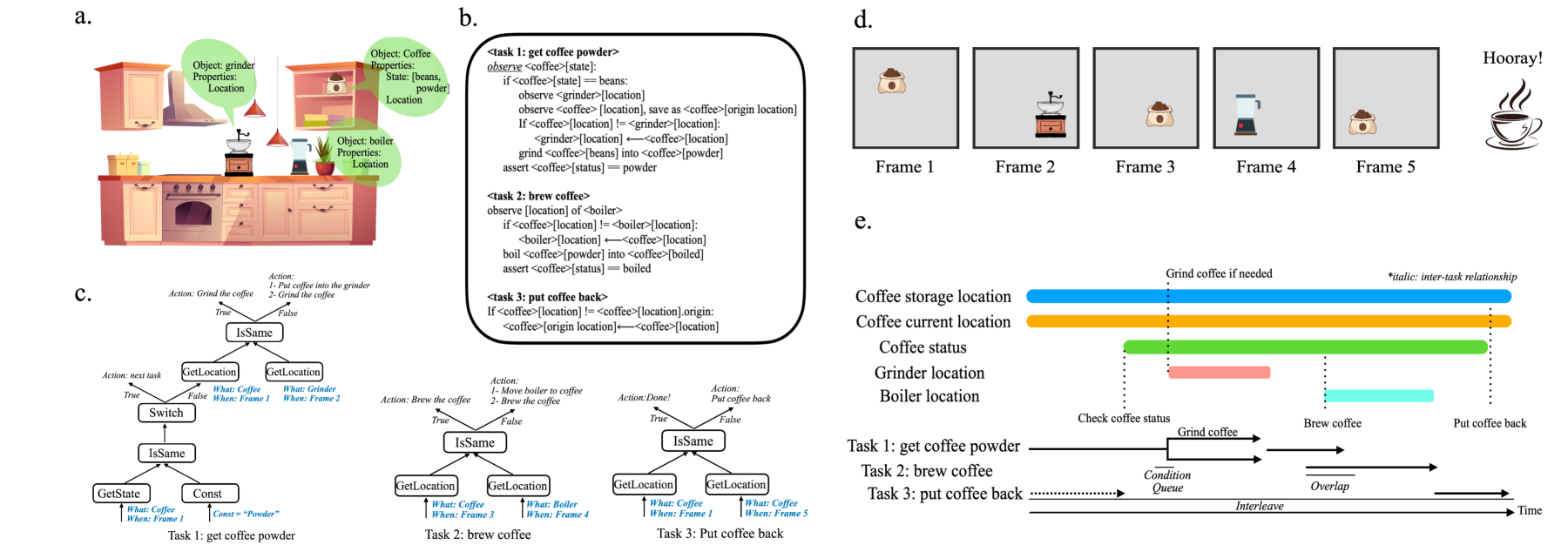
The paper introduces the iWISDM (Instruction-Following in Widely Instructive and Scalable Datasets of Multimodality) framework for assessing multimodal instruction following at scale. The framework includes a large dataset of over 1 million annotated multimodal instructions, as well as evaluation metrics and baseline models.
The dataset, called iWISDM-1M, covers a diverse range of instruction-following tasks, such as cooking recipes, assembling furniture, and performing craft activities. Each instruction is annotated with step-by-step textual descriptions and corresponding images.
The authors evaluate several state-of-the-art multimodal models, including Text-as-Images, IG-Mask, TextBind, and VisionX, on the iWISDM-1M dataset. They analyze the models' performance on various metrics, such as step completion accuracy, step ordering, and visual grounding.
The findings reveal that while current multimodal models show promising results, they still struggle with certain aspects of instruction following, such as maintaining step order and accurately grounding textual instructions to visual elements. The authors discuss the implications of these results and outline potential directions for future research in this area.
Critical Analysis
The iWISDM framework and dataset represent a valuable contribution to the field of multimodal instruction following. By providing a large-scale, diverse, and well-annotated benchmark, the authors enable more comprehensive evaluation of existing models and identification of their strengths and weaknesses.
One potential limitation of the dataset is that it may not capture the full complexity and diversity of real-world instruction-following tasks, which can involve more open-ended interactions, ambiguous or incomplete information, and dynamic environments. The authors acknowledge this and suggest that future work could explore more realistic and interactive instruction-following scenarios.
Additionally, while the baseline models evaluated in the paper provide a good starting point, there may be opportunities to develop more advanced techniques, such as those that exploit the hierarchical structure of instructions or incorporate more sophisticated reasoning and planning capabilities.
Overall, the iWISDM framework and the insights gleaned from the reported experiments represent an important step forward in advancing the field of multimodal instruction following. The findings highlighted in the paper can inform the development of more capable and versatile AI assistants that can better understand and execute complex, multimedia-based instructions.
Conclusion
This paper introduces the iWISDM framework for assessing instruction following in multimodal language models at scale. By providing a large-scale dataset of annotated multimodal instructions and a suite of evaluation metrics, the authors enable more comprehensive benchmarking of state-of-the-art models in this domain.
The extensive experiments conducted in the paper reveal that while current multimodal models show promise, they still face significant challenges in accurately following step-by-step instructions that combine textual and visual information. These insights can guide future research and development efforts to create AI systems that can better understand and execute complex, multimedia-based tasks, ultimately leading to more capable and versatile AI assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
iWISDM: Assessing instruction following in multimodal models at scale
Xiaoxuan Lei, Lucas Gomez, Hao Yuan Bai, Pouya Bashivan
The ability to perform complex tasks from detailed instructions is a key to many remarkable achievements of our species. As humans, we are not only capable of performing a wide variety of tasks but also very complex ones that may entail hundreds or thousands of steps to complete. Large language models and their more recent multimodal counterparts that integrate textual and visual inputs have achieved unprecedented success in performing complex tasks. Yet, most existing benchmarks are largely confined to single-modality inputs (either text or vision), narrowing the scope of multimodal assessments, particularly for instruction-following in multimodal contexts. To bridge this gap, we introduce the instructed-Virtual VISual Decision Making (iWISDM) environment engineered to generate a limitless array of vision-language tasks of varying complexity. Using iWISDM, we compiled three distinct benchmarks of instruction following visual tasks across varying complexity levels and evaluated several newly developed multimodal models on these benchmarks. Our findings establish iWISDM as a robust benchmark for assessing the instructional adherence of both existing and emergent multimodal models and highlight a large gap between these models' ability to precisely follow instructions with that of humans.The code of iWISDM is available on GitHub at https://github.com/BashivanLab/iWISDM.
Read more7/23/2024

0
Text as Images: Can Multimodal Large Language Models Follow Printed Instructions in Pixels?
Xiujun Li, Yujie Lu, Zhe Gan, Jianfeng Gao, William Yang Wang, Yejin Choi
Recent multimodal large language models (MLLMs) have shown promising instruction following capabilities on vision-language tasks. In this work, we introduce VISUAL MODALITY INSTRUCTION (VIM), and investigate how well multimodal models can understand textual instructions provided in pixels, despite not being explicitly trained on such data during pretraining or fine-tuning. We adapt VIM to eight benchmarks, including OKVQA, MM-Vet, MathVista, MMMU, and probe diverse MLLMs in both the text-modality instruction (TEM) setting and VIM setting. Notably, we observe a significant performance disparity between the original TEM and VIM settings for open-source MLLMs, indicating that open-source MLLMs face greater challenges when text instruction is presented solely in image form. To address this issue, we train v-MLLM, a generalizable model that is capable to conduct robust instruction following in both text-modality and visual-modality instructions.
Read more6/12/2024

0
Instruction-Guided Visual Masking
Jinliang Zheng, Jianxiong Li, Sijie Cheng, Yinan Zheng, Jiaming Li, Jihao Liu, Yu Liu, Jingjing Liu, Xianyuan Zhan
Instruction following is crucial in contemporary LLM. However, when extended to multimodal setting, it often suffers from misalignment between specific textual instruction and targeted local region of an image. To achieve more accurate and nuanced multimodal instruction following, we introduce Instruction-guided Visual Masking (IVM), a new versatile visual grounding model that is compatible with diverse multimodal models, such as LMM and robot model. By constructing visual masks for instruction-irrelevant regions, IVM-enhanced multimodal models can effectively focus on task-relevant image regions to better align with complex instructions. Specifically, we design a visual masking data generation pipeline and create an IVM-Mix-1M dataset with 1 million image-instruction pairs. We further introduce a new learning technique, Discriminator Weighted Supervised Learning (DWSL) for preferential IVM training that prioritizes high-quality data samples. Experimental results on generic multimodal tasks such as VQA and embodied robotic control demonstrate the versatility of IVM, which as a plug-and-play tool, significantly boosts the performance of diverse multimodal models, yielding new state-of-the-art results across challenging multimodal benchmarks. Code is available at https://github.com/2toinf/IVM.
Read more5/31/2024

0
MIA-Bench: Towards Better Instruction Following Evaluation of Multimodal LLMs
Yusu Qian, Hanrong Ye, Jean-Philippe Fauconnier, Peter Grasch, Yinfei Yang, Zhe Gan
We introduce MIA-Bench, a new benchmark designed to evaluate multimodal large language models (MLLMs) on their ability to strictly adhere to complex instructions. Our benchmark comprises a diverse set of 400 image-prompt pairs, each crafted to challenge the models' compliance with layered instructions in generating accurate responses that satisfy specific requested patterns. Evaluation results from a wide array of state-of-the-art MLLMs reveal significant variations in performance, highlighting areas for improvement in instruction fidelity. Additionally, we create extra training data and explore supervised fine-tuning to enhance the models' ability to strictly follow instructions without compromising performance on other tasks. We hope this benchmark not only serves as a tool for measuring MLLM adherence to instructions, but also guides future developments in MLLM training methods.
Read more7/29/2024