Vision+X: A Survey on Multimodal Learning in the Light of Data
2210.02884
0
0
📊
Abstract
We are perceiving and communicating with the world in a multisensory manner, where different information sources are sophisticatedly processed and interpreted by separate parts of the human brain to constitute a complex, yet harmonious and unified sensing system. To endow the machines with true intelligence, multimodal machine learning that incorporates data from various sources has become an increasingly popular research area with emerging technical advances in recent years. In this paper, we present a survey on multimodal machine learning from a novel perspective considering not only the purely technical aspects but also the intrinsic nature of different data modalities. We analyze the commonness and uniqueness of each data format mainly ranging from vision, audio, text, and motions, and then present the methodological advancements categorized by the combination of data modalities, such as Vision+Text, with slightly inclined emphasis on the visual data. We investigate the existing literature on multimodal learning from both the representation learning and downstream application levels, and provide an additional comparison in the light of their technical connections with the data nature, e.g., the semantic consistency between image objects and textual descriptions, and the rhythm correspondence between video dance moves and musical beats. We hope that the exploitation of the alignment as well as the existing gap between the intrinsic nature of data modality and the technical designs, will benefit future research studies to better address a specific challenge related to the concrete multimodal task, prompting a unified multimodal machine learning framework closer to a real human intelligence system.
Create account to get full access
Overview
- Humans perceive and communicate with the world in a multisensory manner, processing information from various sources in the brain to create a unified experience.
- To develop truly intelligent machines, multimodal machine learning that incorporates data from multiple sources has become an increasingly popular research area.
- This paper presents a survey on multimodal machine learning, considering not only the technical aspects but also the intrinsic nature of different data modalities.
Plain English Explanation
Humans don't just see, hear, or feel the world around us - we experience it in a rich, multisensory way. Our brains take in and process information from various sources, like vision, sound, and touch, to create a complex yet harmonious understanding of our environment.
To make machines that are truly intelligent, researchers are exploring multimodal machine learning. This approach aims to have computers learn from and combine data from multiple modalities, just like humans do. The goal is to develop AI systems that can perceive and interact with the world in a more natural, human-like way.
This paper provides a comprehensive overview of the field of multimodal machine learning. It not only examines the technical advancements in this area, but also delves into the unique properties and relationships between different types of data, such as images, text, audio, and video. By understanding the fundamental characteristics of these data modalities, the researchers hope to inspire future work that can better harness the connections between them, leading to more unified and human-like AI systems.
Technical Explanation
The paper begins by highlighting the multisensory nature of human perception and communication, where the brain sophisticatedly processes and integrates information from various sources to create a unified experience. Drawing inspiration from this, the researchers argue that to truly endow machines with intelligence, multimodal machine learning has become an increasingly important area of study.
The authors present a comprehensive survey on multimodal machine learning, considering not only the technical advancements in this field but also the intrinsic properties of different data modalities, such as vision, audio, text, and motion. They analyze the commonalities and unique characteristics of each data format, and then discuss the methodological progress made in combining these modalities, with a slight emphasis on visual data.
The paper explores the existing literature on multimodal learning from both the representation learning and downstream application levels. It also provides comparisons between the technical approaches and the inherent nature of the data, such as the semantic consistency between image objects and textual descriptions, and the rhythm correspondence between video dance moves and musical beats.
The researchers hope that by examining the alignment as well as the gaps between the intrinsic properties of data modalities and the technical designs, future studies can better address specific challenges related to multimodal tasks, ultimately leading to the development of a more unified multimodal machine learning framework that is closer to real human intelligence.
Critical Analysis
The paper provides a comprehensive and insightful survey of the field of multimodal machine learning, highlighting the importance of understanding the intrinsic nature of different data modalities in addition to the technical advancements. However, the researchers acknowledge that their focus on visual data may not fully represent the breadth of the field, and they encourage further exploration of other modalities and their unique characteristics.
Additionally, the paper does not delve deeply into the potential limitations or challenges of multimodal machine learning, such as the difficulty in aligning and fusing data from disparate sources, the need for large and diverse datasets, and the computational and memory requirements of such systems. These are important considerations that could be addressed in future research.
The authors also do not discuss the ethical implications of developing more human-like AI systems, such as the potential for bias, privacy concerns, and the impact on human-machine interactions. As the field of multimodal machine learning continues to evolve, it will be crucial to consider these broader societal implications.
Conclusion
This paper provides a comprehensive survey of the field of multimodal machine learning, highlighting the importance of understanding the intrinsic nature of different data modalities and how they can be combined to create more intelligent and human-like AI systems. By exploring the technical advancements and the fundamental characteristics of data sources like vision, audio, text, and motion, the researchers hope to inspire future work that can better harness the connections between these modalities, leading to more unified and human-centric machine learning frameworks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey of Multimodal Large Language Model from A Data-centric Perspective
Tianyi Bai, Hao Liang, Binwang Wan, Ling Yang, Bozhou Li, Yifan Wang, Bin Cui, Conghui He, Binhang Yuan, Wentao Zhang
0
0
Human beings perceive the world through diverse senses such as sight, smell, hearing, and touch. Similarly, multimodal large language models (MLLMs) enhance the capabilities of traditional large language models by integrating and processing data from multiple modalities including text, vision, audio, video, and 3D environments. Data plays a pivotal role in the development and refinement of these models. In this survey, we comprehensively review the literature on MLLMs from a data-centric perspective. Specifically, we explore methods for preparing multimodal data during the pretraining and adaptation phases of MLLMs. Additionally, we analyze the evaluation methods for datasets and review benchmarks for evaluating MLLMs. Our survey also outlines potential future research directions. This work aims to provide researchers with a detailed understanding of the data-driven aspects of MLLMs, fostering further exploration and innovation in this field.
5/28/2024

The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
0
0
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
6/7/2024
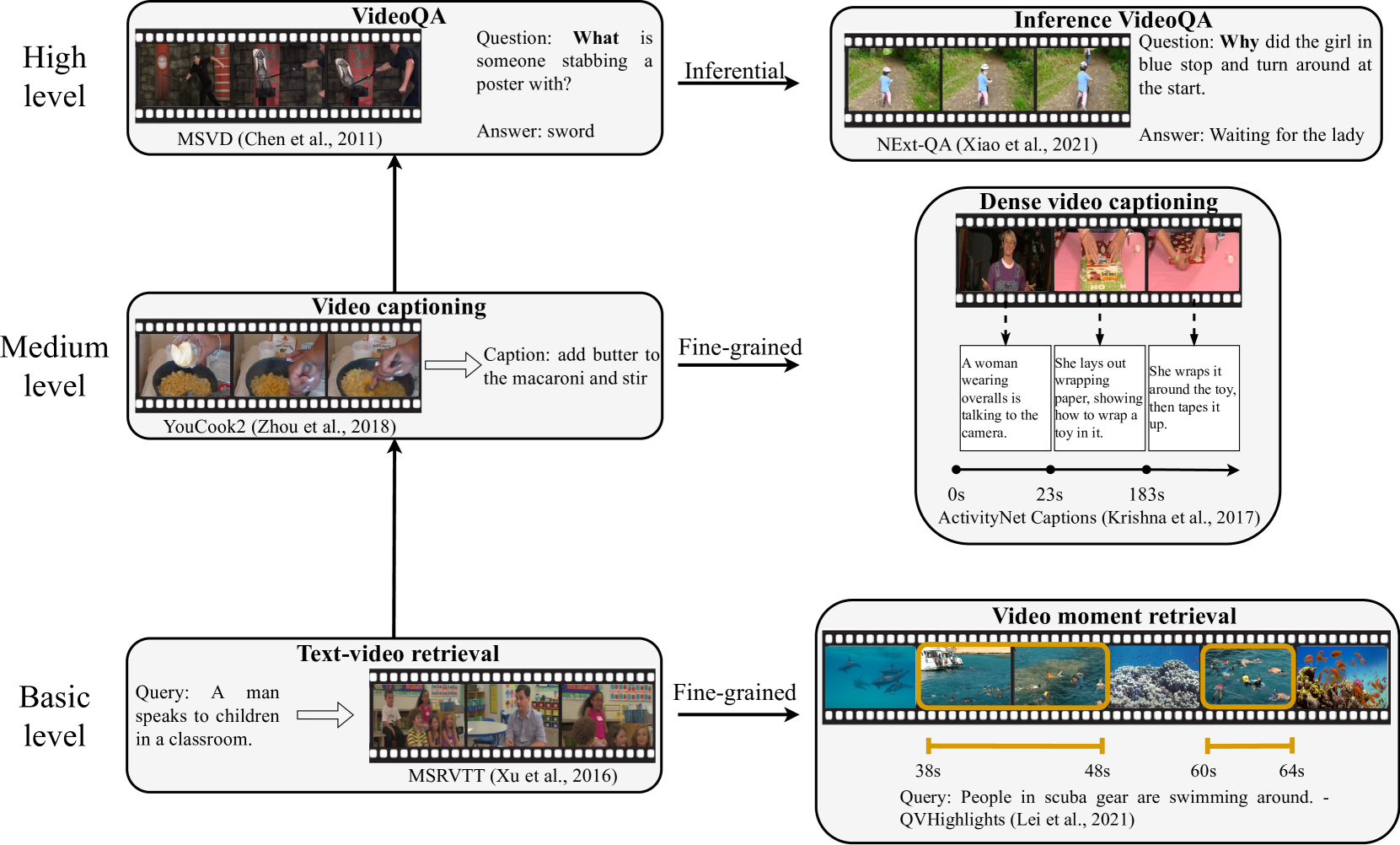
Video-Language Understanding: A Survey from Model Architecture, Model Training, and Data Perspectives
Thong Nguyen, Yi Bin, Junbin Xiao, Leigang Qu, Yicong Li, Jay Zhangjie Wu, Cong-Duy Nguyen, See-Kiong Ng, Luu Anh Tuan
0
0
Humans use multiple senses to comprehend the environment. Vision and language are two of the most vital senses since they allow us to easily communicate our thoughts and perceive the world around us. There has been a lot of interest in creating video-language understanding systems with human-like senses since a video-language pair can mimic both our linguistic medium and visual environment with temporal dynamics. In this survey, we review the key tasks of these systems and highlight the associated challenges. Based on the challenges, we summarize their methods from model architecture, model training, and data perspectives. We also conduct performance comparison among the methods, and discuss promising directions for future research.
6/11/2024
🤖
A Survey on Multi-modal Machine Translation: Tasks, Methods and Challenges
Huangjun Shen, Liangying Shao, Wenbo Li, Zhibin Lan, Zhanyu Liu, Jinsong Su
0
0
In recent years, multi-modal machine translation has attracted significant interest in both academia and industry due to its superior performance. It takes both textual and visual modalities as inputs, leveraging visual context to tackle the ambiguities in source texts. In this paper, we begin by offering an exhaustive overview of 99 prior works, comprehensively summarizing representative studies from the perspectives of dominant models, datasets, and evaluation metrics. Afterwards, we analyze the impact of various factors on model performance and finally discuss the possible research directions for this task in the future. Over time, multi-modal machine translation has developed more types to meet diverse needs. Unlike previous surveys confined to the early stage of multi-modal machine translation, our survey thoroughly concludes these emerging types from different aspects, so as to provide researchers with a better understanding of its current state.
5/24/2024