Jack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model

0
📈
Sign in to get full access
Overview
- This paper introduces VistaLLM, a new visual system that can handle a wide range of vision and vision-language tasks using a unified framework.
- VistaLLM uses an instruction-guided image tokenizer to extract compressed and refined features from multiple input images, and a gradient-aware adaptive sampling technique to represent segmentation masks as sequences.
- The researchers also introduce a new dataset, CoinIt, for coarse-to-fine instruction tuning, and a new task, AttCoSeg (Attribute-level Co-Segmentation), to improve multi-image grounding.
- Experiments show that VistaLLM achieves state-of-the-art performance on a variety of vision and vision-language tasks.
Plain English Explanation
VistaLLM: A Unified Vision System for Coarse and Fine-Grained Tasks is a powerful new model that can handle a wide range of visual tasks, from simple object recognition to complex segmentation and multi-image understanding. Unlike previous models that struggled to integrate different types of visual inputs and outputs, VistaLLM uses a clever approach to unify these tasks into a single framework.
The key innovation is the use of an "instruction-guided image tokenizer" that can extract important features from multiple images based on the specific task at hand. This allows VistaLLM to tackle coarse-grained tasks like image classification as well as fine-grained tasks like pixel-level segmentation, all using the same underlying model.
To further boost VistaLLM's capabilities, the researchers created a new dataset called CoinIt, which contains a diverse range of vision and vision-language tasks. They also introduced a novel task called AttCoSeg (Attribute-level Co-Segmentation) that challenges the model to reason about and ground visual attributes across multiple images.
Through extensive testing, the researchers showed that VistaLLM consistently outperforms other state-of-the-art models on a wide variety of visual tasks. This breakthrough suggests that general-purpose vision systems like VistaLLM could be the future of computer vision, unifying different tasks into a single, flexible framework.
Technical Explanation
VistaLLM is a novel visual system that addresses the challenge of integrating diverse input-output formats in the vision domain. Unlike previous general-purpose models that struggled with tasks like segmentation and multi-image inputs, VistaLLM uses a unified approach to handle a wide range of coarse- and fine-grained vision-language (VL) tasks.
At the core of VistaLLM is an instruction-guided image tokenizer that filters global embeddings using task descriptions to extract compressed and refined features from multiple input images. This allows the model to adaptively focus on relevant information for each specific task.
To address the challenge of representing binary segmentation masks, VistaLLM employs a gradient-aware adaptive sampling technique. This significantly improves over the previously used uniform sampling, resulting in better performance on segmentation tasks.
To further strengthen VistaLLM's capabilities, the researchers curated CoinIt, a comprehensive coarse-to-fine instruction tuning dataset with 6.8M samples. They also introduced a new task, AttCoSeg (Attribute-level Co-Segmentation), to boost the model's reasoning and grounding capability over multiple input images.
Extensive experiments on a wide range of vision and vision-language tasks demonstrate the effectiveness of VistaLLM. The model achieves consistent state-of-the-art performance across all downstream tasks, outperforming strong baselines.
Critical Analysis
While VistaLLM represents a significant advancement in the field of general-purpose vision systems, the paper does not address some potential limitations and areas for further research.
For example, the paper does not discuss the computational and memory requirements of VistaLLM, which could be a concern when deploying the model in real-world applications. Additionally, the paper does not explore the model's robustness to distribution shift or its ability to generalize to novel tasks and datasets beyond the ones used in the experiments.
Furthermore, the introduction of the AttCoSeg task is a valuable contribution, but the paper does not provide a thorough analysis of the model's performance on this task or its implications for multi-image grounding and reasoning. It would be interesting to see how VistaLLM compares to other approaches specifically designed for multi-image tasks.
Overall, while VistaLLM is a impressive and innovative system, there are still opportunities for further research and improvement, such as investigating the use of vision compression techniques to reduce the model's resource requirements or exploring its robustness and generalization capabilities.
Conclusion
VistaLLM represents a significant breakthrough in the field of general-purpose vision systems. By unifying a wide range of vision and vision-language tasks into a single framework, the model demonstrates the potential for vision-language models to serve as powerful, flexible tools for a variety of visual applications.
The key innovations of VistaLLM, including the instruction-guided image tokenizer and the gradient-aware adaptive sampling technique, have allowed the model to excel across a diverse set of tasks, from coarse-grained classification to fine-grained segmentation. The introduction of the CoinIt dataset and the AttCoSeg task further strengthen the model's capabilities and pave the way for future advancements in the field.
As vision-language models continue to evolve, VistaLLM's ability to serve as a unified, general-purpose visual system could have far-reaching implications for a wide range of industries and applications, from autonomous vehicles to medical imaging and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Jack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model
Shraman Pramanick, Guangxing Han, Rui Hou, Sayan Nag, Ser-Nam Lim, Nicolas Ballas, Qifan Wang, Rama Chellappa, Amjad Almahairi
The ability of large language models (LLMs) to process visual inputs has given rise to general-purpose vision systems, unifying various vision-language (VL) tasks by instruction tuning. However, due to the enormous diversity in input-output formats in the vision domain, existing general-purpose models fail to successfully integrate segmentation and multi-image inputs with coarse-level tasks into a single framework. In this work, we introduce VistaLLM, a powerful visual system that addresses coarse- and fine-grained VL tasks over single and multiple input images using a unified framework. VistaLLM utilizes an instruction-guided image tokenizer that filters global embeddings using task descriptions to extract compressed and refined features from numerous images. Moreover, VistaLLM employs a gradient-aware adaptive sampling technique to represent binary segmentation masks as sequences, significantly improving over previously used uniform sampling. To bolster the desired capability of VistaLLM, we curate CoinIt, a comprehensive coarse-to-fine instruction tuning dataset with 6.8M samples. We also address the lack of multi-image grounding datasets by introducing a novel task, AttCoSeg (Attribute-level Co-Segmentation), which boosts the model's reasoning and grounding capability over multiple input images. Extensive experiments on a wide range of V- and VL tasks demonstrate the effectiveness of VistaLLM by achieving consistent state-of-the-art performance over strong baselines across all downstream tasks. Our project page can be found at https://shramanpramanick.github.io/VistaLLM/.
Read more6/21/2024

0
VisionLLM v2: An End-to-End Generalist Multimodal Large Language Model for Hundreds of Vision-Language Tasks
Jiannan Wu, Muyan Zhong, Sen Xing, Zeqiang Lai, Zhaoyang Liu, Wenhai Wang, Zhe Chen, Xizhou Zhu, Lewei Lu, Tong Lu, Ping Luo, Yu Qiao, Jifeng Dai
We present VisionLLM v2, an end-to-end generalist multimodal large model (MLLM) that unifies visual perception, understanding, and generation within a single framework. Unlike traditional MLLMs limited to text output, VisionLLM v2 significantly broadens its application scope. It excels not only in conventional visual question answering (VQA) but also in open-ended, cross-domain vision tasks such as object localization, pose estimation, and image generation and editing. To this end, we propose a new information transmission mechanism termed super link, as a medium to connect MLLM with task-specific decoders. It not only allows flexible transmission of task information and gradient feedback between the MLLM and multiple downstream decoders but also effectively resolves training conflicts in multi-tasking scenarios. In addition, to support the diverse range of tasks, we carefully collected and combed training data from hundreds of public vision and vision-language tasks. In this way, our model can be joint-trained end-to-end on hundreds of vision language tasks and generalize to these tasks using a set of shared parameters through different user prompts, achieving performance comparable to task-specific models. We believe VisionLLM v2 will offer a new perspective on the generalization of MLLMs.
Read more6/17/2024
0
Effectiveness Assessment of Recent Large Vision-Language Models
Yao Jiang, Xinyu Yan, Ge-Peng Ji, Keren Fu, Meijun Sun, Huan Xiong, Deng-Ping Fan, Fahad Shahbaz Khan
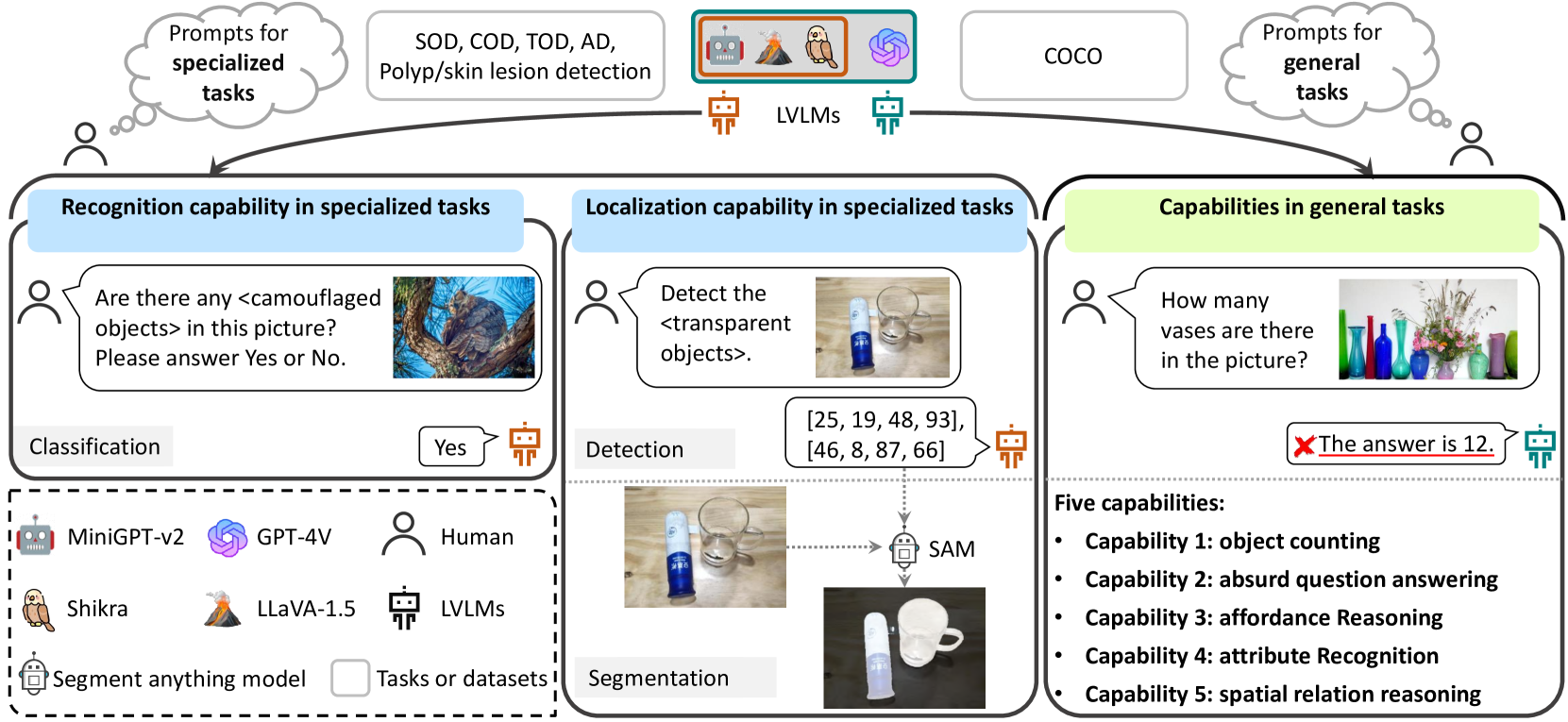
The advent of large vision-language models (LVLMs) represents a remarkable advance in the quest for artificial general intelligence. However, the model's effectiveness in both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their effectiveness in specialized tasks, we employ six challenging tasks in three different application scenarios: natural, healthcare, and industrial. These six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization in these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope that this study can provide useful insights for the future development of LVLMs, helping researchers improve LVLMs for both general and specialized applications.
Read more6/12/2024
💬
0
u-LLaVA: Unifying Multi-Modal Tasks via Large Language Model
Jinjin Xu, Liwu Xu, Yuzhe Yang, Xiang Li, Fanyi Wang, Yanchun Xie, Yi-Jie Huang, Yaqian Li
Recent advancements in multi-modal large language models (MLLMs) have led to substantial improvements in visual understanding, primarily driven by sophisticated modality alignment strategies. However, predominant approaches prioritize global or regional comprehension, with less focus on fine-grained, pixel-level tasks. To address this gap, we introduce u-LLaVA, an innovative unifying multi-task framework that integrates pixel, regional, and global features to refine the perceptual faculties of MLLMs. We commence by leveraging an efficient modality alignment approach, harnessing both image and video datasets to bolster the model's foundational understanding across diverse visual contexts. Subsequently, a joint instruction tuning method with task-specific projectors and decoders for end-to-end downstream training is presented. Furthermore, this work contributes a novel mask-based multi-task dataset comprising 277K samples, crafted to challenge and assess the fine-grained perception capabilities of MLLMs. The overall framework is simple, effective, and achieves state-of-the-art performance across multiple benchmarks. We also make our model, data, and code publicly accessible at https://github.com/OPPOMKLab/u-LLaVA.
Read more8/29/2024