Jamba: A Hybrid Transformer-Mamba Language Model
2403.19887
73
46

Abstract
We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU. Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.
Create account to get full access
Introduction
The paper introduces Jamba, a new publicly available large language model with a novel hybrid architecture. Jamba combines Transformer layers with Mamba layers (a state-space model) and a mixture-of-experts component. This hybrid design aims to improve performance, increase throughput, and maintain a manageable memory footprint.
The key novelty of Jamba is its combination of the Transformer architecture, known for its strong performance, with the Mamba architecture, which excels at handling long contexts and efficient training. By varying the ratio of Transformer and Mamba layers, Jamba can balance memory usage, training efficiency, and long context capabilities.
The paper discusses previous attempts to combine attention and state-space models, noting that Jamba is the first production-grade model of this type. It also incorporates mixture-of-experts layers, allowing for increased model capacity without proportionally increasing compute requirements.
Jamba's performance is comparable to similarly sized models like Mixtral-8x7B and Llama-2 70B, but excels on long-context evaluations. It also boasts high throughput and can fit on a single GPU even with contexts over 128K tokens.
The authors have released Jamba (12B active parameters, 52B total parameters) under an open-source license to encourage further study and optimization by the community. However, they note that the released model is a pretrained base without additional tuning or moderation mechanisms.
Model Architecture
The provided text introduces the Jamba architecture, a hybrid decoder that combines three key components: Transformer layers, Mamba layers (a recent state-space model), and a mixture-of-experts (MoE) module. These components are referred to as a Jamba block. The text refers to Figure 1 for an illustration of this architecture, although the figure itself is not provided.
The paper describes the Jamba architecture, which combines transformer, Mixture of Experts (MoE), and Mamba elements to balance memory usage, throughput, and model quality. Key points:
-
Total model parameters can be misleading for MoE models, as only a subset of parameters are active during inference.
-
The key-value (KV) cache size for storing attention keys/values is a limiting factor, especially for long sequences. Jamba aims for a smaller KV cache compared to standard transformers.
-
Replacing attention layers with more compute-efficient Mamba layers improves throughput, especially for long sequences.
-
Jamba blocks contain a mix of attention and Mamba layers, with multi-layer perceptrons (MLPs) that can be replaced with MoE layers.
-
Configurable parameters include: number of layers, attention-to-Mamba ratio, MoE frequency, number of experts per layer, and number of top experts used.
-
Increasing the Mamba ratio reduces KV cache size but may lower quality. More MoE experts increases capacity but uses more memory.
-
Mamba layers use RMSNorm for stable training at scale. No explicit positional embeddings are used.
-
Other standard components like grouped query attention and SwiGLU activations are used.
The architecture allows flexibility in optimizing for different objectives by tuning the configurable parameters.
Reaping the Benefits
The paper describes the implementation details of Jamba, a large language model designed to fit on a single 80GB GPU while achieving high performance in terms of quality and throughput.
Jamba consists of four Jamba blocks, each with 8 layers. The ratio of attention to Mamba layers is 1:7. The model uses a mixture of experts (MoE) instead of a single MLP every other layer. It has 16 experts in total, with 2 top experts used at each token.
This configuration was chosen to balance model quality, compute requirements, and memory transfers while fitting on an 80GB GPU. It allows for up to 1M token context length during training, and the released model supports up to 256K tokens.
In terms of throughput, Jamba achieves 3x higher throughput than Mixtral on a single GPU with a batch size of 16 and 8K context length. On 4 GPUs with 128K context length, Jamba's throughput is 3x higher than Mixtral's, despite not being optimized for pure transformer models like Mixtral.
The paper highlights that Jamba enables significantly longer context lengths compared to other recent open models like Mixtral and Llama-2-70B when fitting on an 80GB GPU.
Training Infrastructure and Dataset
The model was trained using NVIDIA H100 GPUs and an in-house proprietary framework that enabled efficient large-scale training through techniques like FSDP, tensor parallelism, sequence parallelism, and expert parallelism. The model, named Jamba, was trained on an in-house dataset containing text data from the Web, books, and code. This dataset was last updated in March 2024. A data processing pipeline with quality filters and deduplication methods was employed.
Evaluation
The paper presents performance results of the proposed Jamba model on various academic benchmarks and long-context evaluations. Key points:
Academic Benchmarks:
- Jamba performs comparably or better than leading publicly available models like Llama-2 70B and Mixtral on benchmarks covering reasoning, reading comprehension, and others.
- Despite having fewer total parameters (52B) than Llama-2 70B, Jamba achieves strong performance while offering up to 3x better throughput.
Long-Context Evaluations:
- Jamba can handle contexts up to 1M tokens, with the released model supporting 256K tokens.
- It shows excellent performance on the needle-in-a-haystack evaluation, which tests recall of statements in long contexts.
- On naturalistic long-context QA benchmarks (up to 62K tokens), Jamba outperforms Mixtral on most datasets and has better average performance.
- Jamba's efficiency shines on these long-context tasks, offering much better throughput.
The paper highlights Jamba's ability to reach state-of-the-art performance while leveraging the benefits of a hybrid architecture with improved efficiency.
Ablations and Insights
The section discusses ablation experiments conducted to evaluate different design choices for the Jamba architecture, which combines attention and Mamba (state-space) layers. Key findings include:
-
Combining attention and Mamba layers improves performance over pure attention or pure Mamba models. A ratio of 1 attention layer to 7 Mamba layers works well.
-
The pure Mamba model struggles with in-context learning capabilities, while the hybrid Attention-Mamba model exhibits in-context learning similar to vanilla Transformers. Visualizations suggest the attention layers develop induction heads that support in-context learning.
-
Adding a Mixture-of-Experts (MoE) layer further improves the performance of the hybrid Attention-Mamba architecture at larger scales.
-
Special normalization (RMSNorm) is required to stabilize training of Mamba layers at very large scales.
-
Explicit positional information is not needed in Jamba, as the Mamba layers likely provide implicit position information.
The authors present results on academic benchmarks, log-probability evaluations, and other tasks to support these findings. Overall, the hybrid Attention-Mamba architecture with MoE outperforms pure attention or Mamba models.
Conclusion
The paper presents Jamba, a novel architecture that combines Attention and Mamba layers with Mixture-of-Experts (MoE) modules. It provides an open implementation of Jamba, achieving state-of-the-art performance while supporting long contexts. The architecture offers flexibility in balancing performance and memory requirements while maintaining high throughput. The researchers experimented with various design choices, such as the ratio of Attention-to-Mamba layers, and discussed discoveries made during the development process, which will inform future work on hybrid attention–state-space models. The authors plan to release model checkpoints from smaller-scale training runs to facilitate further research in this area. The largest model provided with this release has 12 billion active and 52 billion total available parameters, supporting context lengths of up to 256,000 tokens and fitting on a single 80GB GPU even when processing texts up to 140,000 tokens.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
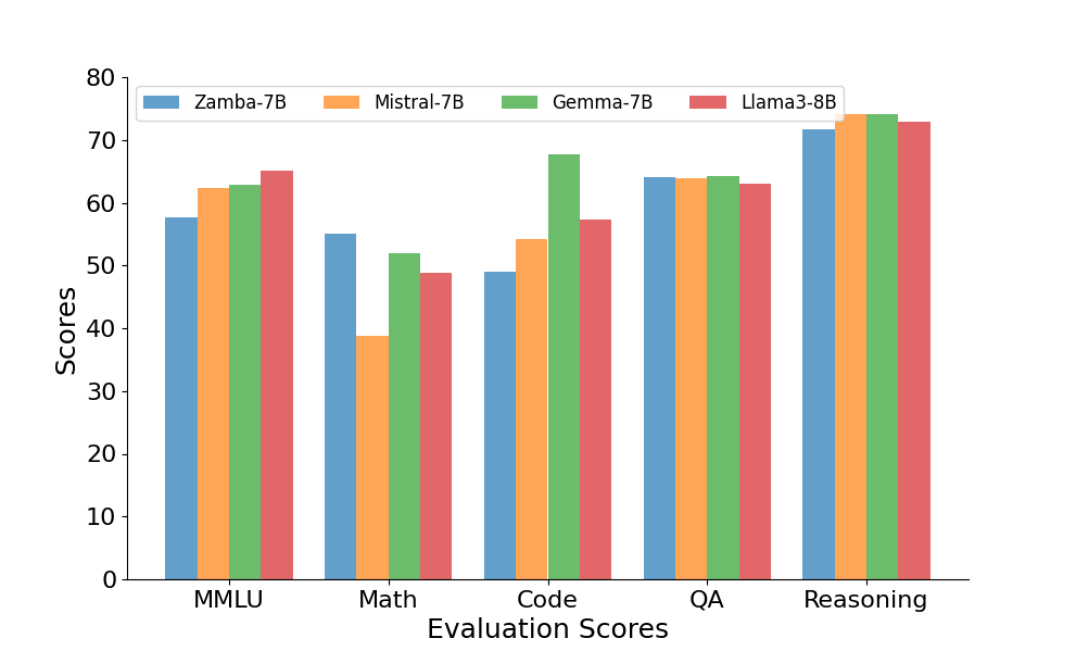
Zamba: A Compact 7B SSM Hybrid Model
Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Adam Ibrahim, Beren Millidge
0
0
In this technical report, we present Zamba, a novel 7B SSM-transformer hybrid model which achieves competitive performance against leading open-weight models at a comparable scale. Zamba is trained on 1T tokens from openly available datasets and is the best non-transformer model at this scale. Zamba pioneers a unique architecture combining a Mamba backbone with a single shared attention module, thus obtaining the benefits of attention at minimal parameter cost. Due to its architecture, Zamba is significantly faster at inference than comparable transformer models and requires substantially less memory for generation of long sequences. Zamba is pretrained in two phases: the first phase is based on existing web datasets, while the second one consists of annealing the model over high-quality instruct and synthetic datasets, and is characterized by a rapid learning rate decay. We open-source the weights and all checkpoints for Zamba, through both phase 1 and annealing phases.
5/28/2024

Dimba: Transformer-Mamba Diffusion Models
Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, Youqiang Zhang, Junshi Huang
0
0
This paper unveils Dimba, a new text-to-image diffusion model that employs a distinctive hybrid architecture combining Transformer and Mamba elements. Specifically, Dimba sequentially stacked blocks alternate between Transformer and Mamba layers, and integrate conditional information through the cross-attention layer, thus capitalizing on the advantages of both architectural paradigms. We investigate several optimization strategies, including quality tuning, resolution adaption, and identify critical configurations necessary for large-scale image generation. The model's flexible design supports scenarios that cater to specific resource constraints and objectives. When scaled appropriately, Dimba offers substantial throughput and a reduced memory footprint relative to conventional pure Transformers-based benchmarks. Extensive experiments indicate that Dimba achieves comparable performance compared with benchmarks in terms of image quality, artistic rendering, and semantic control. We also report several intriguing properties of architecture discovered during evaluation and release checkpoints in experiments. Our findings emphasize the promise of large-scale hybrid Transformer-Mamba architectures in the foundational stage of diffusion models, suggesting a bright future for text-to-image generation.
6/4/2024
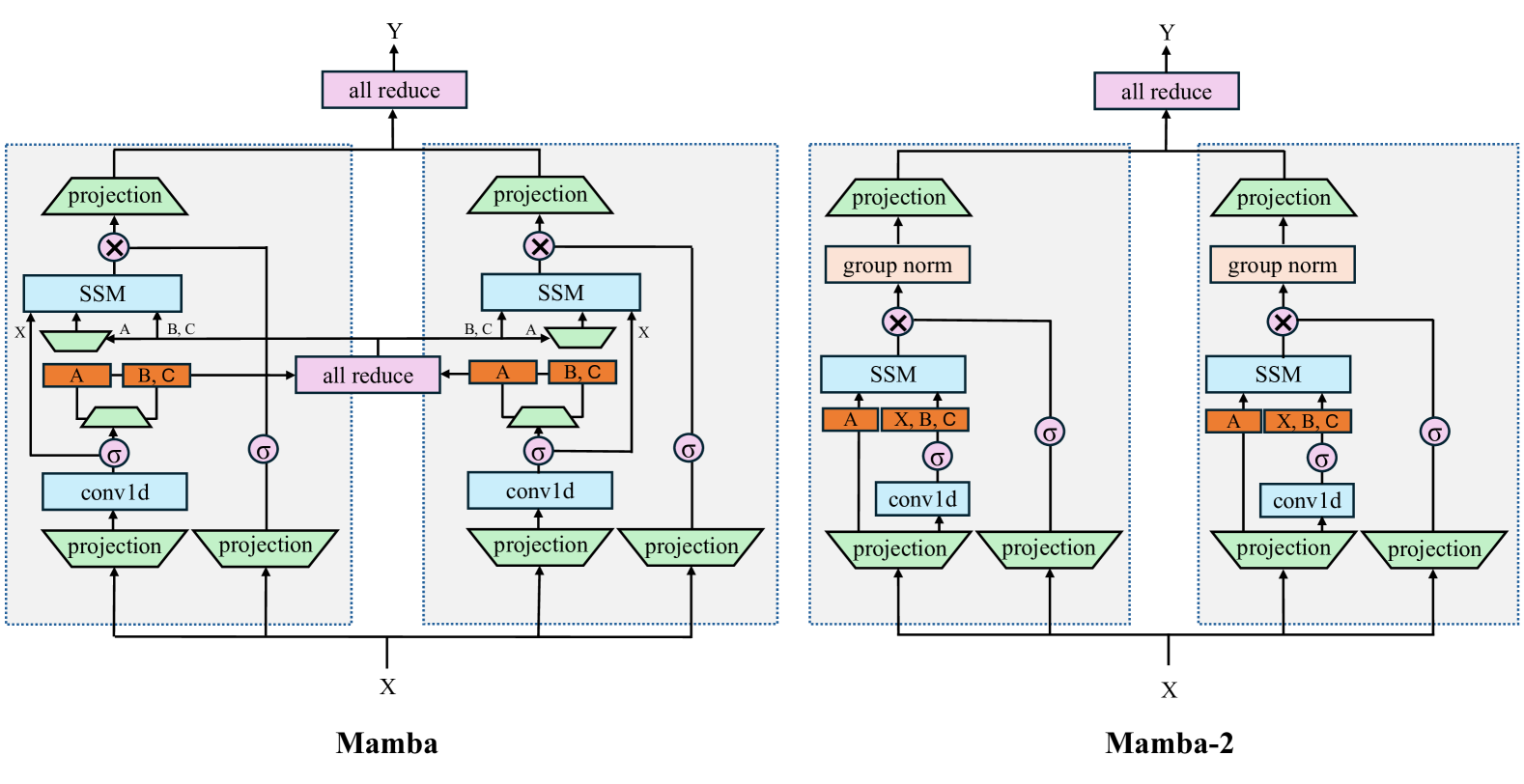
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan Catanzaro
0
0
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
6/13/2024
🤯
Mamba in Speech: Towards an Alternative to Self-Attention
Xiangyu Zhang, Qiquan Zhang, Hexin Liu, Tianyi Xiao, Xinyuan Qian, Beena Ahmed, Eliathamby Ambikairajah, Haizhou Li, Julien Epps
0
0
Transformer and its derivatives have achieved success in diverse tasks across computer vision, natural language processing, and speech processing. To reduce the complexity of computations within the multi-head self-attention mechanism in Transformer, Selective State Space Models (i.e., Mamba) were proposed as an alternative. Mamba exhibited its effectiveness in natural language processing and computer vision tasks, but its superiority has rarely been investigated in speech signal processing. This paper explores solutions for applying Mamba to speech processing using two typical speech processing tasks: speech recognition, which requires semantic and sequential information, and speech enhancement, which focuses primarily on sequential patterns. The experimental results exhibit the superiority of bidirectional Mamba (BiMamba) for speech processing to vanilla Mamba. Moreover, experiments demonstrate the effectiveness of BiMamba as an alternative to the self-attention module in Transformer and its derivates, particularly for the semantic-aware task. The crucial technologies for transferring Mamba to speech are then summarized in ablation studies and the discussion section to offer insights for future research.
5/27/2024