Mamba in Speech: Towards an Alternative to Self-Attention
2405.12609
0
0
🤯
Abstract
Transformer and its derivatives have achieved success in diverse tasks across computer vision, natural language processing, and speech processing. To reduce the complexity of computations within the multi-head self-attention mechanism in Transformer, Selective State Space Models (i.e., Mamba) were proposed as an alternative. Mamba exhibited its effectiveness in natural language processing and computer vision tasks, but its superiority has rarely been investigated in speech signal processing. This paper explores solutions for applying Mamba to speech processing using two typical speech processing tasks: speech recognition, which requires semantic and sequential information, and speech enhancement, which focuses primarily on sequential patterns. The experimental results exhibit the superiority of bidirectional Mamba (BiMamba) for speech processing to vanilla Mamba. Moreover, experiments demonstrate the effectiveness of BiMamba as an alternative to the self-attention module in Transformer and its derivates, particularly for the semantic-aware task. The crucial technologies for transferring Mamba to speech are then summarized in ablation studies and the discussion section to offer insights for future research.
Create account to get full access
Overview
- Transformers and their variants have been successful in various tasks across computer vision, natural language processing, and speech processing.
- To reduce the complexity of computations in Transformers, Selective State Space Models (Mamba) were proposed as an alternative.
- Mamba has shown effectiveness in natural language processing and computer vision tasks, but its superiority in speech processing has not been thoroughly investigated.
- This paper explores the application of Mamba, particularly the bidirectional variant (BiMamba), to speech processing tasks like speech recognition and speech enhancement.
Plain English Explanation
The Transformer model and its derivatives have been very successful in a wide range of applications, from understanding language to recognizing objects in images. However, the computations within the Transformer's self-attention mechanism can be quite complex.
To address this, researchers proposed an alternative called Selective State Space Models (Mamba). Mamba has been shown to work well for natural language processing and computer vision tasks, but its effectiveness in speech processing tasks has not been extensively studied.
This paper looks at using Mamba, and specifically the bidirectional version called BiMamba, for two common speech processing tasks: speech recognition and speech enhancement. Speech recognition requires understanding both the meaning and the sequence of the sounds, while speech enhancement focuses more on the patterns in the sound itself.
The results suggest that BiMamba outperforms the original Mamba model, and can be a good alternative to the self-attention module in Transformer-based models, especially for tasks that involve understanding the meaning of the speech.
Technical Explanation
The paper explores the application of Selective State Space Models (Mamba) and its bidirectional variant (BiMamba) to speech processing tasks, specifically speech recognition and speech enhancement.
In the speech recognition task, the model needs to understand both the semantic meaning and the sequential nature of the speech. For speech enhancement, the focus is more on identifying and removing unwanted noise or distortion in the speech signal.
The researchers found that the BiMamba model outperformed the original Mamba model in both speech tasks. They also demonstrated that BiMamba can be an effective alternative to the self-attention module in Transformer-based models, particularly for tasks that require understanding the semantic content of the speech, such as speech recognition.
The paper includes ablation studies and a detailed discussion to identify the key factors that enable the successful application of Mamba and BiMamba to speech processing. These insights can inform future research in this area.
Critical Analysis
The paper provides a comprehensive evaluation of the Mamba and BiMamba models for speech processing tasks, addressing an important gap in the literature. The authors have carefully designed their experiments to compare the models' performance on speech recognition and speech enhancement, which are two representative speech processing tasks.
One potential limitation of the study is that it focuses primarily on the comparison between Mamba, BiMamba, and Transformer-based models. While this provides valuable insights, it would be interesting to see how these models perform relative to other state-of-the-art speech processing techniques, such as those based on SPMamba or SSAMamba approaches.
Additionally, the paper does not delve deeply into the potential reasons why BiMamba outperforms the original Mamba model in speech processing tasks. A more detailed analysis of the specific architectural differences and their implications could further strengthen the understanding of the model's strengths and limitations.
Overall, the paper presents a well-designed study that demonstrates the effectiveness of the BiMamba model for speech processing tasks. The insights provided can serve as a valuable foundation for future research in this area.
Conclusion
This paper explores the application of Selective State Space Models (Mamba) and its bidirectional variant (BiMamba) to speech processing tasks, including speech recognition and speech enhancement. The results show that BiMamba outperforms the original Mamba model and can be a promising alternative to the self-attention module in Transformer-based models, particularly for tasks that require understanding the semantic content of speech.
The insights gained from this research can inform future efforts to develop more efficient and effective speech processing models, with potential applications in areas like voice assistants, speech-to-text transcription, and audio signal enhancement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
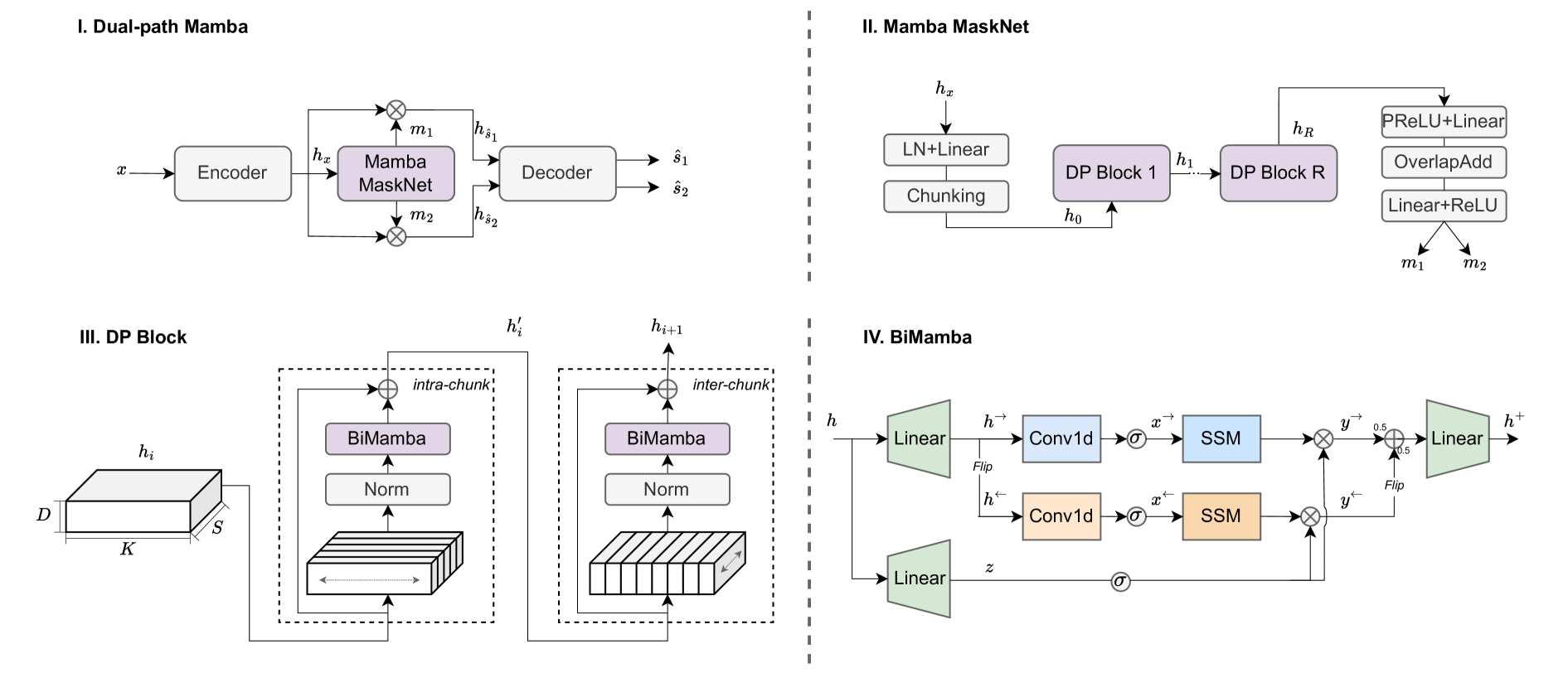
Dual-path Mamba: Short and Long-term Bidirectional Selective Structured State Space Models for Speech Separation
Xilin Jiang, Cong Han, Nima Mesgarani
0
0
Transformers have been the most successful architecture for various speech modeling tasks, including speech separation. However, the self-attention mechanism in transformers with quadratic complexity is inefficient in computation and memory. Recent models incorporate new layers and modules along with transformers for better performance but also introduce extra model complexity. In this work, we replace transformers with Mamba, a selective state space model, for speech separation. We propose dual-path Mamba, which models short-term and long-term forward and backward dependency of speech signals using selective state spaces. Our experimental results on the WSJ0-2mix data show that our dual-path Mamba models of comparably smaller sizes outperform state-of-the-art RNN model DPRNN, CNN model WaveSplit, and transformer model Sepformer. Code: https://github.com/xi-j/Mamba-TasNet
5/2/2024

Exploring the Capability of Mamba in Speech Applications
Koichi Miyazaki, Yoshiki Masuyama, Masato Murata
0
0
This paper explores the capability of Mamba, a recently proposed architecture based on state space models (SSMs), as a competitive alternative to Transformer-based models. In the speech domain, well-designed Transformer-based models, such as the Conformer and E-Branchformer, have become the de facto standards. Extensive evaluations have demonstrated the effectiveness of these Transformer-based models across a wide range of speech tasks. In contrast, the evaluation of SSMs has been limited to a few tasks, such as automatic speech recognition (ASR) and speech synthesis. In this paper, we compared Mamba with state-of-the-art Transformer variants for various speech applications, including ASR, text-to-speech, spoken language understanding, and speech summarization. Experimental evaluations revealed that Mamba achieves comparable or better performance than Transformer-based models, and demonstrated its efficiency in long-form speech processing.
6/26/2024
🤷
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu, Tri Dao
0
0
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5$times$ higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
6/3/2024
🗣️
An Investigation of Incorporating Mamba for Speech Enhancement
Rong Chao, Wen-Huang Cheng, Moreno La Quatra, Sabato Marco Siniscalchi, Chao-Han Huck Yang, Szu-Wei Fu, Yu Tsao
0
0
This work aims to study a scalable state-space model (SSM), Mamba, for the speech enhancement (SE) task. We exploit a Mamba-based regression model to characterize speech signals and build an SE system upon Mamba, termed SEMamba. We explore the properties of Mamba by integrating it as the core model in both basic and advanced SE systems, along with utilizing signal-level distances as well as metric-oriented loss functions. SEMamba demonstrates promising results and attains a PESQ score of 3.55 on the VoiceBank-DEMAND dataset. When combined with the perceptual contrast stretching technique, the proposed SEMamba yields a new state-of-the-art PESQ score of 3.69.
5/13/2024