Quality Does Matter: A Detailed Look at the Quality and Utility of Web-Mined Parallel Corpora
2402.07446
0
0
💬
Abstract
We conducted a detailed analysis on the quality of web-mined corpora for two low-resource languages (making three language pairs, English-Sinhala, English-Tamil and Sinhala-Tamil). We ranked each corpus according to a similarity measure and carried out an intrinsic and extrinsic evaluation on different portions of this ranked corpus. We show that there are significant quality differences between different portions of web-mined corpora and that the quality varies across languages and datasets. We also show that, for some web-mined datasets, Neural Machine Translation (NMT) models trained with their highest-ranked 25k portion can be on par with human-curated datasets.
Create account to get full access
Overview
- The paper introduces an extension to Access Control Lists (ACLs) for managing permissions in computer systems.
- The proposed extension aims to address limitations of traditional ACLs and provide more granular control over access privileges.
- Key aspects of the research include data collection, experimental setup, and evaluation of the extended ACL system.
Plain English Explanation
Access Control Lists (ACLs) are a common way for computers to manage who can access different files, folders, or other resources. Traditional ACLs have some limitations, such as being unable to easily grant permissions to groups of users or control access at a very detailed level.
The researchers in this paper have developed an extension to ACLs that aims to address these issues. Their extended system allows for more granular control over permissions, such as being able to grant access to a specific subset of users or restrict access to certain operations on a resource.
To test their approach, the researchers collected data on how people use and interact with computer systems. They then set up experiments to evaluate how well their extended ACL system works compared to traditional ACLs. The results suggest the extended system provides more flexibility and control over access privileges.
Overall, this research explores ways to improve access management in computer systems, which is an important aspect of maintaining information security and protecting sensitive data.
Technical Explanation
The paper presents an extension to traditional Access Control Lists (ACLs) to provide more granular control over permissions and access privileges. The proposed ACL extension introduces the concept of "access rules" that can be defined at a more detailed level than standard ACLs.
The researchers first collected data on how users interact with computer systems and the types of access privileges they require. This data was used to inform the design of the extended ACL system.
The experimental setup involved implementing the ACL extension and comparing its performance to traditional ACLs across various metrics, such as the ability to accurately extract information and the textual similarity of access control policies. The results demonstrate that the extended ACL system offers improved flexibility and control over access privileges compared to standard ACLs.
Critical Analysis
The paper provides a thorough evaluation of the ACL extension and highlights its potential benefits. However, the research also acknowledges some limitations and areas for further exploration.
One limitation mentioned is the need to carefully balance the tradeoffs between access control granularity and system complexity. Introducing more detailed access rules could make the overall access management system more complicated and difficult to maintain.
Additionally, the paper suggests further research is needed to understand how the extended ACL system performs in real-world, large-scale deployments. The experimental setup focused on controlled scenarios, and the researchers recommend exploring the system's scalability and practicality in more diverse, production-level environments.
Overall, the research presents a promising approach to enhancing access control mechanisms, but additional investigation may be necessary to fully address the practical implications and widespread adoption of the proposed ACL extension.
Conclusion
This paper introduces an extension to traditional Access Control Lists (ACLs) that aims to provide more granular control over permissions and access privileges in computer systems. The researchers collected data on user access patterns, designed an extended ACL system, and conducted experiments to evaluate its performance.
The results suggest the proposed ACL extension offers improved flexibility and control compared to standard ACLs. However, the research also highlights the need to balance the tradeoffs between access control granularity and system complexity, as well as the importance of further evaluating the extended system's scalability and real-world applicability.
Overall, this work contributes to the ongoing efforts to enhance access management mechanisms, which is crucial for maintaining information security and protecting sensitive data in computer systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
A Japanese-Chinese Parallel Corpus Using Crowdsourcing for Web Mining
Masaaki Nagata, Makoto Morishita, Katsuki Chousa, Norihito Yasuda
0
0
Using crowdsourcing, we collected more than 10,000 URL pairs (parallel top page pairs) of bilingual websites that contain parallel documents and created a Japanese-Chinese parallel corpus of 4.6M sentence pairs from these websites. We used a Japanese-Chinese bilingual dictionary of 160K word pairs for document and sentence alignment. We then used high-quality 1.2M Japanese-Chinese sentence pairs to train a parallel corpus filter based on statistical language models and word translation probabilities. We compared the translation accuracy of the model trained on these 4.6M sentence pairs with that of the model trained on Japanese-Chinese sentence pairs from CCMatrix (12.4M), a parallel corpus from global web mining. Although our corpus is only one-third the size of CCMatrix, we found that the accuracy of the two models was comparable and confirmed that it is feasible to use crowdsourcing for web mining of parallel data.
5/16/2024
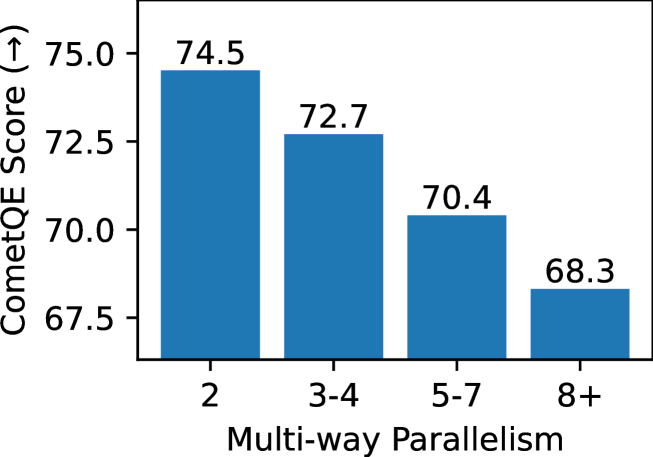
A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism
Brian Thompson, Mehak Preet Dhaliwal, Peter Frisch, Tobias Domhan, Marcello Federico
0
0
We show that content on the web is often translated into many languages, and the low quality of these multi-way translations indicates they were likely created using Machine Translation (MT). Multi-way parallel, machine generated content not only dominates the translations in lower resource languages; it also constitutes a large fraction of the total web content in those languages. We also find evidence of a selection bias in the type of content which is translated into many languages, consistent with low quality English content being translated en masse into many lower resource languages, via MT. Our work raises serious concerns about training models such as multilingual large language models on both monolingual and bilingual data scraped from the web.
6/7/2024
Quantifying Multilingual Performance of Large Language Models Across Languages
Zihao Li, Yucheng Shi, Zirui Liu, Fan Yang, Ali Payani, Ninghao Liu, Mengnan Du
0
0
The development of Large Language Models (LLMs) relies on extensive text corpora, which are often unevenly distributed across languages. This imbalance results in LLMs performing significantly better on high-resource languages like English, German, and French, while their capabilities in low-resource languages remain inadequate. Currently, there is a lack of quantitative methods to evaluate the performance of LLMs in these low-resource languages. To address this gap, we propose the Language Ranker, an intrinsic metric designed to benchmark and rank languages based on LLM performance using internal representations. By comparing the LLM's internal representation of various languages against a baseline derived from English, we can assess the model's multilingual capabilities in a robust and language-agnostic manner. Our analysis reveals that high-resource languages exhibit higher similarity scores with English, demonstrating superior performance, while low-resource languages show lower similarity scores, underscoring the effectiveness of our metric in assessing language-specific capabilities. Besides, the experiments show that there is a strong correlation between the LLM's performance in different languages and the proportion of those languages in its pre-training corpus. These insights underscore the efficacy of the Language Ranker as a tool for evaluating LLM performance across different languages, particularly those with limited resources.
6/18/2024

Assessing the quality of information extraction
Filip Seitl, Tom'av{s} Kov'av{r}'ik, Soheyla Mirshahi, Jan Kryv{s}tr{u}fek, Rastislav Dujava, Mat'uv{s} Ondreiv{c}ka, Herbert Ullrich, Petr Gronat
0
0
Advances in large language models have notably enhanced the efficiency of information extraction from unstructured and semi-structured data sources. As these technologies become integral to various applications, establishing an objective measure for the quality of information extraction becomes imperative. However, the scarcity of labeled data presents significant challenges to this endeavor. In this paper, we introduce an automatic framework to assess the quality of the information extraction/retrieval and its completeness. The framework focuses on information extraction in the form of entity and its properties. We discuss how to handle the input/output size limitations of the large language models and analyze their performance when extracting the information. In particular, we introduce scores to evaluate the quality of the extraction and provide an extensive discussion on how to interpret them.
5/24/2024