JetMoE: Reaching Llama2 Performance with 0.1M Dollars
2404.07413
2
0
Abstract
Large Language Models (LLMs) have achieved remarkable results, but their increasing resource demand has become a major obstacle to the development of powerful and accessible super-human intelligence. This report introduces JetMoE-8B, a new LLM trained with less than $0.1 million, using 1.25T tokens from carefully mixed open-source corpora and 30,000 H100 GPU hours. Despite its low cost, the JetMoE-8B demonstrates impressive performance, with JetMoE-8B outperforming the Llama2-7B model and JetMoE-8B-Chat surpassing the Llama2-13B-Chat model. These results suggest that LLM training can be much more cost-effective than generally thought. JetMoE-8B is based on an efficient Sparsely-gated Mixture-of-Experts (SMoE) architecture, composed of attention and feedforward experts. Both layers are sparsely activated, allowing JetMoE-8B to have 8B parameters while only activating 2B for each input token, reducing inference computation by about 70% compared to Llama2-7B. Moreover, JetMoE-8B is highly open and academia-friendly, using only public datasets and training code. All training parameters and data mixtures have been detailed in this report to facilitate future efforts in the development of open foundation models. This transparency aims to encourage collaboration and further advancements in the field of accessible and efficient LLMs. The model weights are publicly available at https://github.com/myshell-ai/JetMoE.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Introduces a new language model called JetMoE that can match the performance of Llama2 while costing only $0.1 million to train
- Leverages a Mixture of Experts (MoE) architecture to achieve high performance with a much smaller model size
- Demonstrates impressive results on a variety of benchmarks, rivaling the performance of larger language models like Llama2
Plain English Explanation
The paper introduces a new language model called JetMoE that can achieve similar performance to the powerful Llama2 model, but at a fraction of the cost. Llama2 is a highly capable language model that requires significant computational resources to train, on the order of millions of dollars. In contrast, the researchers behind JetMoE were able to train their model for just $0.1 million.
The key to JetMoE's efficiency is its use of a Mixture of Experts (MoE) architecture. Rather than having a single large neural network, MoE models use a collection of smaller "expert" networks that each specialize in different tasks or types of information. During inference, the model dynamically selects the most appropriate experts to use for a given input, allowing it to leverage its specialized knowledge while remaining compact.
This approach allows JetMoE to achieve Llama2-level performance without requiring the same massive model size and computational resources. The researchers demonstrate that JetMoE performs on par with Llama2 on a variety of benchmarks, including language understanding, generation, and reasoning tasks. This is an impressive feat considering the significant cost and resource differences between the two models.
The success of JetMoE highlights the potential of efficient Mixture of Experts architectures for building highly capable language models at a much lower cost. It also raises interesting questions about the role of prompting and prompt-based adaptation in enabling small models to achieve large-language-model-level performance.
Technical Explanation
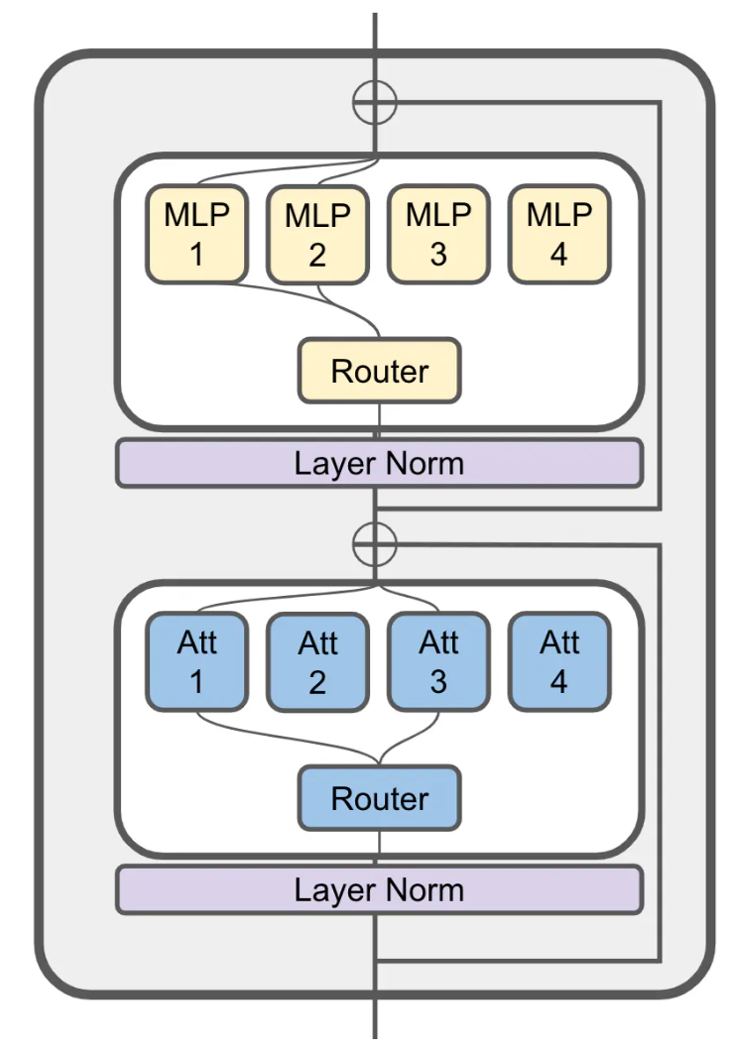
The key innovation in the JetMoE model is its use of a Mixture of Experts (MoE) architecture. Rather than a single large neural network, JetMoE consists of a collection of smaller "expert" networks that each specialize in different tasks or types of information. During inference, the model dynamically selects the most appropriate experts to use for a given input, allowing it to leverage its specialized knowledge while remaining compact.
The MoE architecture is implemented as follows:
- The input is first processed by a shared "trunk" network, which extracts general features.
- The trunk output is then fed into a gating network, which determines how to weight and combine the different expert networks.
- The weighted expert outputs are then combined to produce the final model output.
This allows JetMoE to achieve high performance without requiring a single large monolithic network. The researchers demonstrate that JetMoE can match the performance of Llama2 on a variety of benchmarks, including language understanding, generation, and reasoning tasks, while having a much smaller model size and training cost.
The researchers also explore the role of prompt-based adaptation in enabling JetMoE to achieve Llama2-level performance. By fine-tuning the model on carefully crafted prompts, they are able to further enhance its capabilities without increasing the model size.
Overall, the JetMoE model represents an exciting advance in efficient language modeling, demonstrating that Mixture of Experts architectures can be a powerful tool for building highly capable models at a fraction of the cost of traditional approaches.
Critical Analysis
The JetMoE paper presents a compelling approach to building efficient language models, but it is important to consider some potential limitations and areas for further research.
One potential concern is the reliance on prompt-based adaptation to achieve Llama2-level performance. While this technique is effective, it raises questions about the stability and generalization of the model's capabilities. It's possible that the model may be overly specialized to the specific prompts used during fine-tuning, which could limit its broader applicability.
Additionally, the paper does not provide a detailed analysis of the computational efficiency of the JetMoE model during inference. While the training cost is significantly lower than Llama2, the runtime performance and energy efficiency of the model during deployment are also important considerations, especially for real-world applications.
Further research could also explore the scalability of the MoE approach, as the number of experts and the complexity of the gating network may become a bottleneck as the model size increases. [Techniques like TeenyTinyLLaMA could be leveraged to address this challenge.
Finally, it would be valuable to see how JetMoE performs on a broader range of tasks and datasets, beyond the specific benchmarks reported in the paper. This could provide a more comprehensive understanding of the model's strengths, weaknesses, and potential use cases.
Conclusion
The JetMoE model представs an exciting development in the field of efficient language modeling. By leveraging a Mixture of Experts architecture, the researchers were able to achieve Llama2-level performance at a fraction of the training cost, demonstrating the potential of this approach to democratize access to powerful language models.
The success of JetMoE highlights the importance of continued research into innovative model architectures and efficient training techniques for language models. As the field continues to evolve, models like JetMoE could play a crucial role in making advanced language capabilities more widely available and accessible to a diverse range of applications and users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
0
0
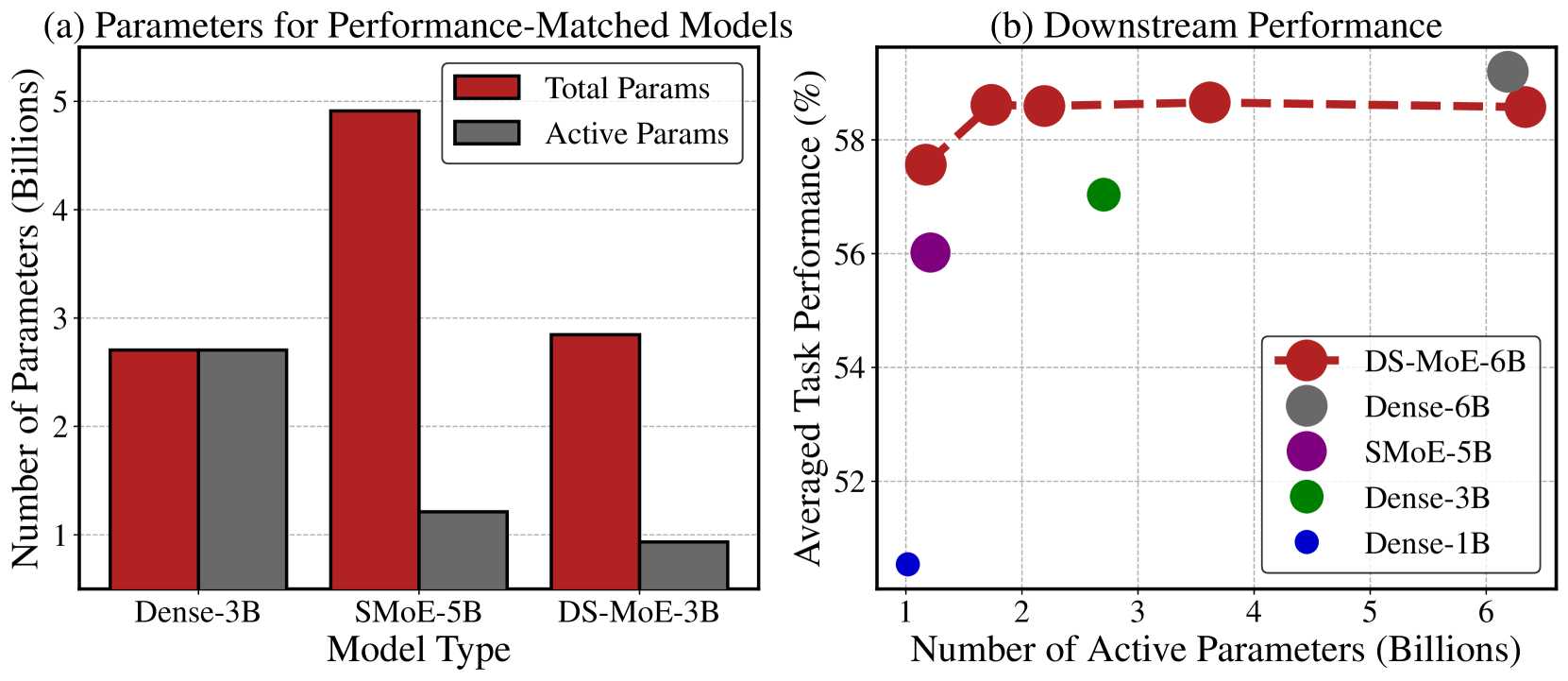
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
4/9/2024
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
0
0
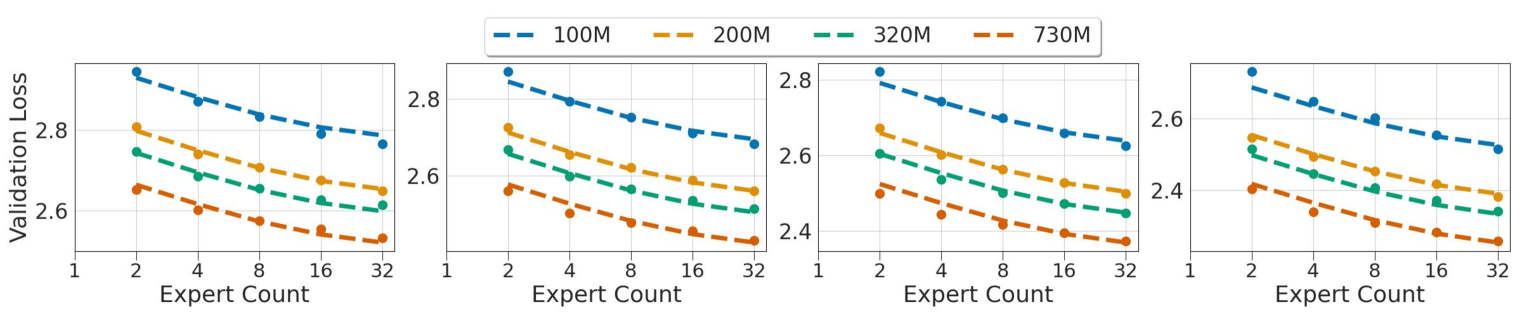
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
4/4/2024
LocMoE: A Low-Overhead MoE for Large Language Model Training
Jing Li, Zhijie Sun, Xuan He, Li Zeng, Yi Lin, Entong Li, Binfan Zheng, Rongqian Zhao, Xin Chen
0
0
The Mixtures-of-Experts (MoE) model is a widespread distributed and integrated learning method for large language models (LLM), which is favored due to its ability to sparsify and expand models efficiently. However, the performance of MoE is limited by load imbalance and high latency of All-to-All communication, along with relatively redundant computation owing to large expert capacity. Load imbalance may result from existing routing policies that consistently tend to select certain experts. The frequent inter-node communication in the All-to-All procedure also significantly prolongs the training time. To alleviate the above performance problems, we propose a novel routing strategy that combines load balance and locality by converting partial inter-node communication to that of intra-node. Notably, we elucidate that there is a minimum threshold for expert capacity, calculated through the maximal angular deviation between the gating weights of the experts and the assigned tokens. We port these modifications on the PanGu-Sigma model based on the MindSpore framework with multi-level routing and conduct experiments on Ascend clusters. The experiment results demonstrate that the proposed LocMoE reduces training time per epoch by 12.68% to 22.24% compared to classical routers, such as hash router and switch router, without impacting the model accuracy.
5/14/2024
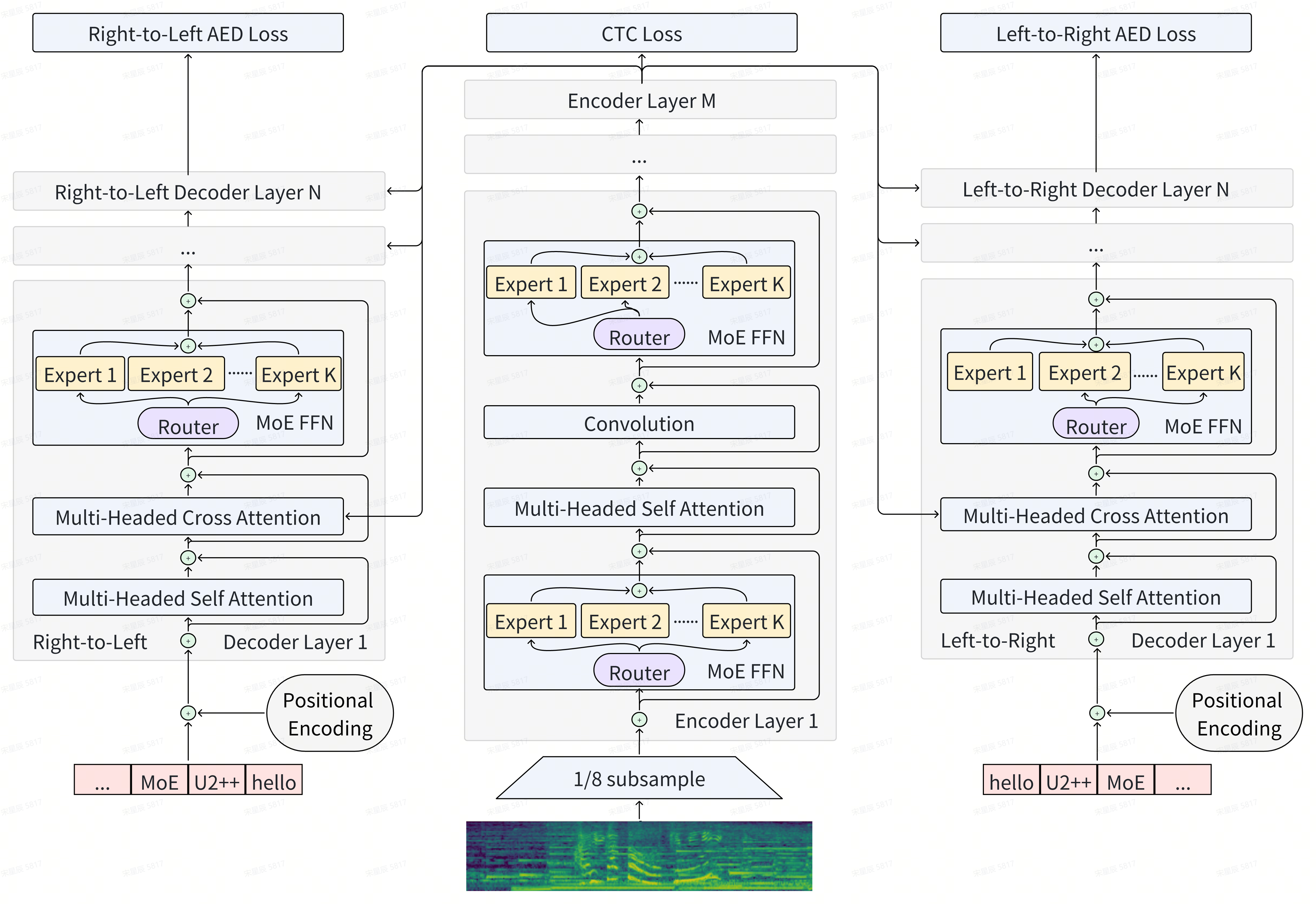
U2++ MoE: Scaling 4.7x parameters with minimal impact on RTF
Xingchen Song, Di Wu, Binbin Zhang, Dinghao Zhou, Zhendong Peng, Bo Dang, Fuping Pan, Chao Yang
0
0
Scale has opened new frontiers in natural language processing, but at a high cost. In response, by learning to only activate a subset of parameters in training and inference, Mixture-of-Experts (MoE) have been proposed as an energy efficient path to even larger and more capable language models and this shift towards a new generation of foundation models is gaining momentum, particularly within the field of Automatic Speech Recognition (ASR). Recent works that incorporating MoE into ASR models have complex designs such as routing frames via supplementary embedding network, improving multilingual ability for the experts, and utilizing dedicated auxiliary losses for either expert load balancing or specific language handling. We found that delicate designs are not necessary, while an embarrassingly simple substitution of MoE layers for all Feed-Forward Network (FFN) layers is competent for the ASR task. To be more specific, we benchmark our proposed model on a large scale inner-source dataset (160k hours), the results show that we can scale our baseline Conformer (Dense-225M) to its MoE counterparts (MoE-1B) and achieve Dense-1B level Word Error Rate (WER) while maintaining a Dense-225M level Real Time Factor (RTF). Furthermore, by applying Unified 2-pass framework with bidirectional attention decoders (U2++), we achieve the streaming and non-streaming decoding modes in a single MoE based model, which we call U2++ MoE. We hope that our study can facilitate the research on scaling speech foundation models without sacrificing deployment efficiency.
4/26/2024