Prompt-prompted Mixture of Experts for Efficient LLM Generation
2404.01365
0
0
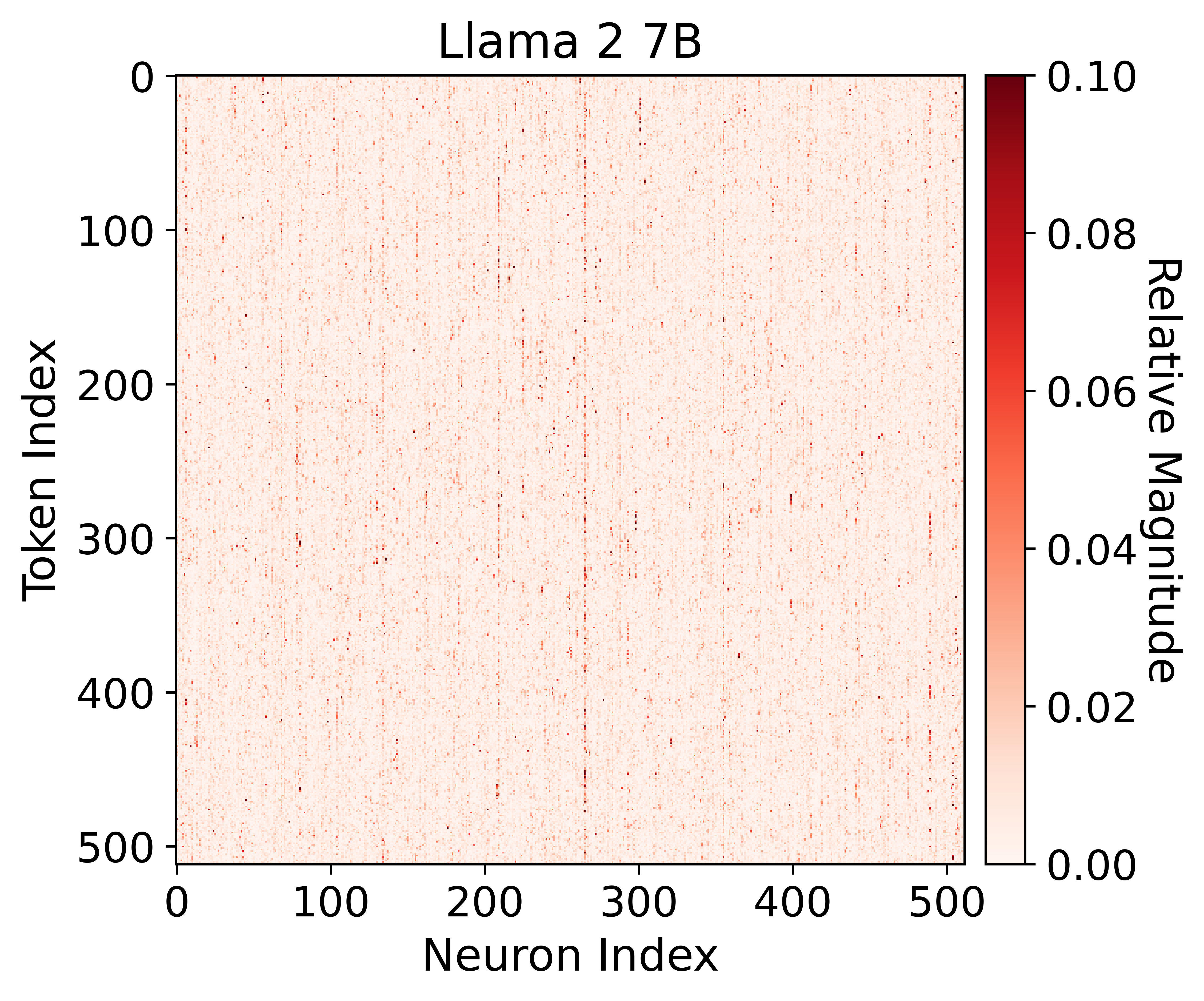
Abstract
With the development of transformer-based large language models (LLMs), they have been applied to many fields due to their remarkable utility, but this comes at a considerable computational cost at deployment. Fortunately, some methods such as pruning or constructing a mixture of experts (MoE) aim at exploiting sparsity in transformer feedforward (FF) blocks to gain boosts in speed and reduction in memory requirements. However, these techniques can be very costly and inflexible in practice, as they often require training or are restricted to specific types of architectures. To address this, we introduce GRIFFIN, a novel training-free MoE that selects unique FF experts at the sequence level for efficient generation across a plethora of LLMs with different non-ReLU activation functions. This is possible due to a critical observation that many trained LLMs naturally produce highly structured FF activation patterns within a sequence, which we call flocking. Despite our method's simplicity, we show with 50% of the FF parameters, GRIFFIN maintains the original model's performance with little to no degradation on a variety of classification and generation tasks, all while improving latency (e.g. 1.25$times$ speed-up in Llama 2 13B on an NVIDIA L40). Code is available at https://github.com/hdong920/GRIFFIN.
Create account to get full access
Overview
- Proposes a "Prompt-prompted Mixture of Experts" approach to efficiently generate content using large language models (LLMs)
- Leverages prompt engineering and a mixture of expert networks to improve the quality and speed of LLM generation
- Demonstrates improved performance compared to standard LLM generation on various benchmarks
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive capabilities in generating human-like text. However, running these models can be computationally expensive and slow. The researchers behind this paper wanted to find a way to make LLM generation more efficient.
Their solution is a "Prompt-prompted Mixture of Experts" approach. The key idea is to use a set of specialized expert networks, each trained on a different task, and then have the user provide a prompt that selects the most relevant expert(s) for the desired output. This allows the system to focus its computational resources on the specific task at hand, rather than having to process the entire breadth of knowledge in a single large model.
Imagine you're trying to write a research paper. Instead of using a single, general-purpose writing assistant, this approach would let you choose different experts - one for structuring your arguments, another for finding relevant citations, a third for polishing your prose. By customizing the experts to your specific needs, the system can generate high-quality text much more efficiently.
The researchers show that their Prompt-prompted Mixture of Experts outperforms standard LLM generation on a variety of benchmarks, producing better results in less time. This suggests the approach could be a promising way to make large language models more practical and accessible for real-world applications.
Technical Explanation
The paper proposes a "Prompt-prompted Mixture of Experts" (PP-MoE) architecture for efficient LLM generation. The key components are:
-
Mixture of Experts (MoE): The model consists of a set of expert networks, each specialized for a different task or domain. An expert gating network selects the most relevant experts for a given input.
-
Prompt-Prompted Selection: Rather than relying on the gating network alone, the user provides a prompt that directly influences which experts are selected. This allows the user to tailor the model's behavior to their specific needs.
-
Efficient Inference: By only activating the relevant expert networks, PP-MoE can generate high-quality output much more efficiently than a standard LLM. The researchers demonstrate significant improvements in generation speed and quality across various benchmarks.
The paper also analyzes the "feedforward activation sparsity" of PP-MoE, showing that it results in more efficient use of the model's parameters compared to a traditional LLM.
Critical Analysis
The Prompt-prompted Mixture of Experts approach shows promising results, but there are a few potential limitations and areas for further research:
-
Expert Network Training: The paper does not provide details on how the individual expert networks are trained. Ensuring each expert is well-optimized for its specialized task will be crucial for the overall performance of the system.
-
Scalability: While the authors demonstrate improvements on various benchmarks, it's unclear how the PP-MoE approach would scale to larger, more complex language modeling tasks. Integrating this approach with massive LLMs like GPT-3 or GPT-4 would be an important next step.
-
Prompt Engineering: The quality of the user-provided prompts will be a critical factor in determining the performance of the system. Developing robust prompt engineering techniques will be essential for real-world deployment.
-
Interpretability: The paper does not address the interpretability or explainability of the expert selection process. Understanding why certain experts are chosen for a given input could be important for building trust and ensuring the system behaves as expected.
Overall, the Prompt-prompted Mixture of Experts is a promising approach that could make large language models more efficient and practical for a wide range of applications. However, further research is needed to address the potential limitations and ensure the approach can be scaled and deployed effectively.
Conclusion
The Prompt-prompted Mixture of Experts (PP-MoE) is an innovative approach to improving the efficiency of large language model generation. By leveraging a set of specialized expert networks and allowing users to guide the expert selection process through prompts, the system can produce high-quality output much more quickly than standard LLMs.
The technical details and benchmarking results presented in the paper suggest PP-MoE could be a valuable tool for making LLMs more practical and accessible for real-world applications, from content creation to task-oriented dialogue systems. While there are some potential limitations that require further investigation, the core ideas behind this approach are exciting and could have a significant impact on the field of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLaMA-MoE: Building Mixture-of-Experts from LLaMA with Continual Pre-training
Tong Zhu, Xiaoye Qu, Daize Dong, Jiacheng Ruan, Jingqi Tong, Conghui He, Yu Cheng
0
0
Mixture-of-Experts (MoE) has gained increasing popularity as a promising framework for scaling up large language models (LLMs). However, training MoE from scratch in a large-scale setting still suffers from data-hungry and instability problems. Motivated by this limit, we investigate building MoE models from existing dense large language models. Specifically, based on the well-known LLaMA-2 7B model, we obtain an MoE model by: (1) Expert Construction, which partitions the parameters of original Feed-Forward Networks (FFNs) into multiple experts; (2) Continual Pre-training, which further trains the transformed MoE model and additional gate networks. In this paper, we comprehensively explore different methods for expert construction and various data sampling strategies for continual pre-training. After these stages, our LLaMA-MoE models could maintain language abilities and route the input tokens to specific experts with part of the parameters activated. Empirically, by training 200B tokens, LLaMA-MoE-3.5B models significantly outperform dense models that contain similar activation parameters. The source codes and models are available at https://github.com/pjlab-sys4nlp/llama-moe .
6/26/2024

Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, Hongsheng Li
0
0
A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
5/31/2024

Intuition-aware Mixture-of-Rank-1-Experts for Parameter Efficient Finetuning
Yijiang Liu, Rongyu Zhang, Huanrui Yang, Kurt Keutzer, Yuan Du, Li Du, Shanghang Zhang
0
0
Large Language Models (LLMs) have demonstrated significant potential in performing multiple tasks in multimedia applications, ranging from content generation to interactive entertainment, and artistic creation. However, the diversity of downstream tasks in multitask scenarios presents substantial adaptation challenges for LLMs. While traditional methods often succumb to knowledge confusion on their monolithic dense models, Mixture-of-Experts (MoE) has been emerged as a promising solution with its sparse architecture for effective task decoupling. Inspired by the principles of human cognitive neuroscience, we design a novel framework texttt{Intuition-MoR1E} that leverages the inherent semantic clustering of instances to mimic the human brain to deal with multitask, offering implicit guidance to router for optimized feature allocation. Moreover, we introduce cutting-edge Rank-1 Experts formulation designed to manage a spectrum of intuitions, demonstrating enhanced parameter efficiency and effectiveness in multitask LLM finetuning. Extensive experiments demonstrate that Intuition-MoR1E achieves superior efficiency and 2.15% overall accuracy improvement across 14 public datasets against other state-of-the-art baselines.
4/16/2024

Filtered not Mixed: Stochastic Filtering-Based Online Gating for Mixture of Large Language Models
Raeid Saqur, Anastasis Kratsios, Florian Krach, Yannick Limmer, Jacob-Junqi Tian, John Willes, Blanka Horvath, Frank Rudzicz
0
0
We propose MoE-F -- a formalised mechanism for combining $N$ pre-trained expert Large Language Models (LLMs) in online time-series prediction tasks by adaptively forecasting the best weighting of LLM predictions at every time step. Our mechanism leverages the conditional information in each expert's running performance to forecast the best combination of LLMs for predicting the time series in its next step. Diverging from static (learned) Mixture of Experts (MoE) methods, MoE-F employs time-adaptive stochastic filtering techniques to combine experts. By framing the expert selection problem as a finite state-space, continuous-time Hidden Markov model (HMM), we can leverage the Wohman-Shiryaev filter. Our approach first constructs $N$ parallel filters corresponding to each of the $N$ individual LLMs. Each filter proposes its best combination of LLMs, given the information that they have access to. Subsequently, the $N$ filter outputs are aggregated to optimize a lower bound for the loss of the aggregated LLMs, which can be optimized in closed-form, thus generating our ensemble predictor. Our contributions here are: (I) the MoE-F algorithm -- deployable as a plug-and-play filtering harness, (II) theoretical optimality guarantees of the proposed filtering-based gating algorithm, and (III) empirical evaluation and ablative results using state of the art foundational and MoE LLMs on a real-world Financial Market Movement task where MoE-F attains a remarkable 17% absolute and 48.5% relative F1 measure improvement over the next best performing individual LLM expert.
6/6/2024