Towards Evaluating and Building Versatile Large Language Models for Medicine

0

Sign in to get full access
Overview
- This research paper focuses on evaluating and building versatile large language models for medical applications.
- The researchers aim to develop language models that can effectively handle a wide range of medical tasks, from clinical note generation to question answering.
- They propose a comprehensive benchmarking system to assess the capabilities of these models across multiple medical domains.
Plain English Explanation
The paper is about creating and testing large language models that can be used in the medical field. Large language models are powerful AI systems that can understand and generate human-like text. The researchers want to develop language models that can handle a variety of medical tasks, such as generating clinical notes or answering medical questions.
To do this, the researchers have created a comprehensive benchmarking system that can test the capabilities of these language models across different medical domains. This will help them identify the strengths and weaknesses of the models and guide the development of more versatile and effective medical language models.
Technical Explanation
The paper proposes a framework for evaluating and building large language models for medical applications, known as MedBench. MedBench is a comprehensive, standardized, and reliable benchmarking system that assesses the performance of language models on a wide range of medical tasks, including clinical note generation, question answering, and medical entity recognition.
The researchers use ClinicalBERT, a large language model pre-trained on clinical text, as a baseline and evaluate its performance on the MedBench tasks. They also explore techniques for further fine-tuning and adapting ClinicalBERT to improve its medical language understanding and generation capabilities.
The results of their experiments demonstrate the potential of large language models for medical applications, but also highlight the need for more specialized and versatile models that can handle the complexity and diversity of medical domains.
Critical Analysis
The researchers acknowledge several limitations of their work, including the relatively narrow scope of the MedBench tasks and the potential biases in the training data used for the language models. They also note that further research is needed to develop more robust and generalizable medical language models that can handle the nuances and uncertainties inherent in medical practice.
Additionally, while the benchmarking system proposed in the paper is comprehensive, there may be concerns about the representativeness and validity of the tasks and datasets used. It would be important to validate the MedBench framework with a wider range of medical professionals and stakeholders to ensure that it captures the true needs and challenges of the medical community.
Conclusion
This research paper presents a significant step towards building versatile large language models for medical applications. By developing a comprehensive benchmarking system and exploring techniques for fine-tuning and adapting language models for medical tasks, the researchers have laid the groundwork for the development of more effective and reliable medical AI systems.
The insights and methodologies outlined in this paper could have far-reaching implications for the field of medical AI, potentially leading to the creation of language models that can assist healthcare professionals in a wide range of tasks, from clinical documentation to patient education and decision support.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Evaluating and Building Versatile Large Language Models for Medicine
Chaoyi Wu, Pengcheng Qiu, Jinxin Liu, Hongfei Gu, Na Li, Ya Zhang, Yanfeng Wang, Weidi Xie
In this study, we present MedS-Bench, a comprehensive benchmark designed to evaluate the performance of large language models (LLMs) in clinical contexts. Unlike existing benchmarks that focus on multiple-choice question answering, MedS-Bench spans 11 high-level clinical tasks, including clinical report summarization, treatment recommendations, diagnosis, named entity recognition, and medical concept explanation, among others. We evaluated six leading LLMs, e.g., MEDITRON, Mistral, InternLM 2, Llama 3, GPT-4, and Claude-3.5 using few-shot prompting, and found that even the most sophisticated models struggle with these complex tasks. To address these limitations, we developed MedS-Ins, a large-scale instruction tuning dataset for medicine. MedS-Ins comprises 58 medically oriented language corpora, totaling 13.5 million samples across 122 tasks. To demonstrate the dataset's utility, we conducted a proof-of-concept experiment by performing instruction tuning on a lightweight, open-source medical language model. The resulting model, MMedIns-Llama 3, significantly outperformed existing models across nearly all clinical tasks. To promote further advancements in the application of LLMs to clinical challenges, we have made the MedS-Ins dataset fully accessible and invite the research community to contribute to its expansion.Additionally, we have launched a dynamic leaderboard for MedS-Bench, which we plan to regularly update the test set to track progress and enhance the adaptation of general LLMs to the medical domain. Leaderboard: https://henrychur.github.io/MedS-Bench/. Github: https://github.com/MAGIC-AI4Med/MedS-Ins.
Read more9/6/2024
💬
0
MedBench: A Comprehensive, Standardized, and Reliable Benchmarking System for Evaluating Chinese Medical Large Language Models
Mianxin Liu, Jinru Ding, Jie Xu, Weiguo Hu, Xiaoyang Li, Lifeng Zhu, Zhian Bai, Xiaoming Shi, Benyou Wang, Haitao Song, Pengfei Liu, Xiaofan Zhang, Shanshan Wang, Kang Li, Haofen Wang, Tong Ruan, Xuanjing Huang, Xin Sun, Shaoting Zhang
Ensuring the general efficacy and goodness for human beings from medical large language models (LLM) before real-world deployment is crucial. However, a widely accepted and accessible evaluation process for medical LLM, especially in the Chinese context, remains to be established. In this work, we introduce MedBench, a comprehensive, standardized, and reliable benchmarking system for Chinese medical LLM. First, MedBench assembles the currently largest evaluation dataset (300,901 questions) to cover 43 clinical specialties and performs multi-facet evaluation on medical LLM. Second, MedBench provides a standardized and fully automatic cloud-based evaluation infrastructure, with physical separations for question and ground truth. Third, MedBench implements dynamic evaluation mechanisms to prevent shortcut learning and answer remembering. Applying MedBench to popular general and medical LLMs, we observe unbiased, reproducible evaluation results largely aligning with medical professionals' perspectives. This study establishes a significant foundation for preparing the practical applications of Chinese medical LLMs. MedBench is publicly accessible at https://medbench.opencompass.org.cn.
Read more7/17/2024
0
CliBench: Multifaceted Evaluation of Large Language Models in Clinical Decisions on Diagnoses, Procedures, Lab Tests Orders and Prescriptions
Mingyu Derek Ma, Chenchen Ye, Yu Yan, Xiaoxuan Wang, Peipei Ping, Timothy S Chang, Wei Wang
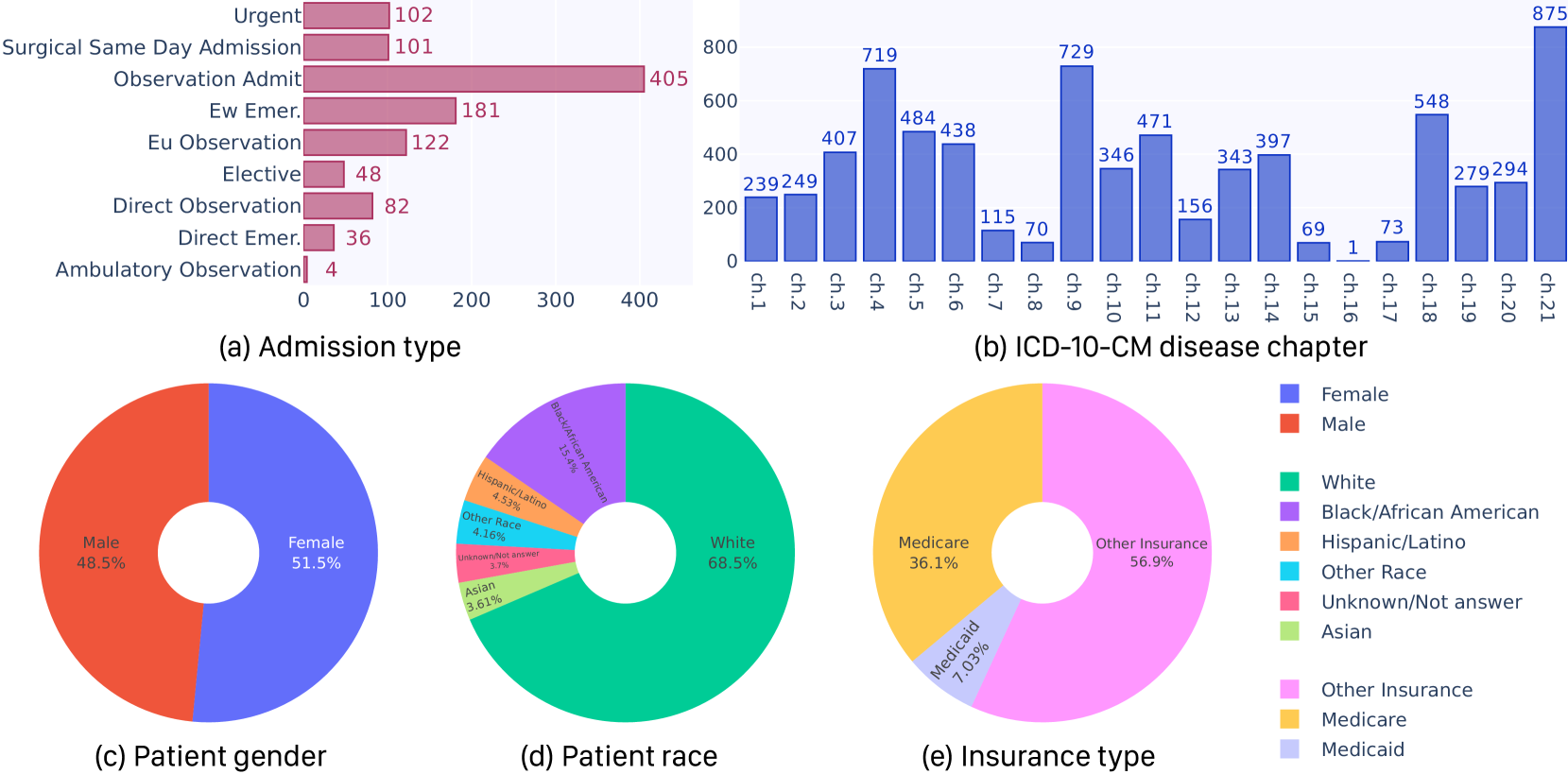
The integration of Artificial Intelligence (AI), especially Large Language Models (LLMs), into the clinical diagnosis process offers significant potential to improve the efficiency and accessibility of medical care. While LLMs have shown some promise in the medical domain, their application in clinical diagnosis remains underexplored, especially in real-world clinical practice, where highly sophisticated, patient-specific decisions need to be made. Current evaluations of LLMs in this field are often narrow in scope, focusing on specific diseases or specialties and employing simplified diagnostic tasks. To bridge this gap, we introduce CliBench, a novel benchmark developed from the MIMIC IV dataset, offering a comprehensive and realistic assessment of LLMs' capabilities in clinical diagnosis. This benchmark not only covers diagnoses from a diverse range of medical cases across various specialties but also incorporates tasks of clinical significance: treatment procedure identification, lab test ordering and medication prescriptions. Supported by structured output ontologies, CliBench enables a precise and multi-granular evaluation, offering an in-depth understanding of LLM's capability on diverse clinical tasks of desired granularity. We conduct a zero-shot evaluation of leading LLMs to assess their proficiency in clinical decision-making. Our preliminary results shed light on the potential and limitations of current LLMs in clinical settings, providing valuable insights for future advancements in LLM-powered healthcare.
Read more6/17/2024
0
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Anshul Thakur, Lei Clifton, David A. Clifton
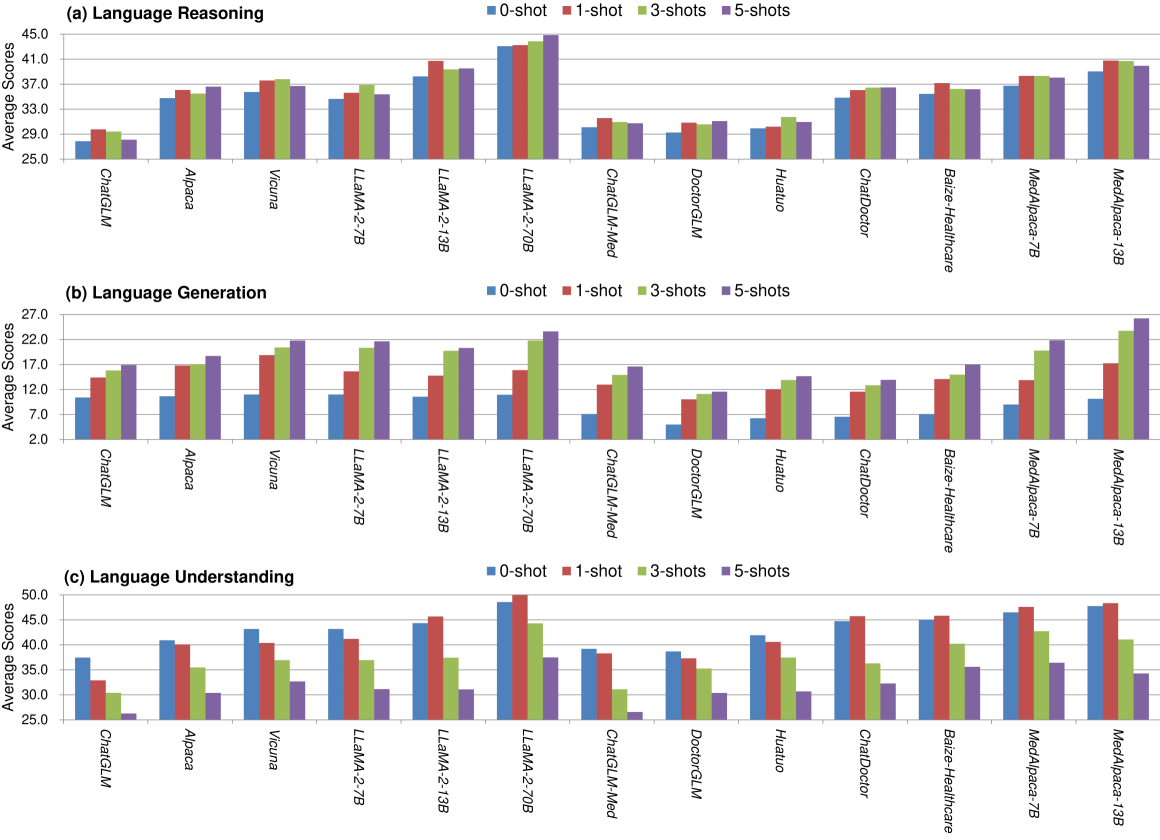
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and complex clinical tasks that are close to real-world practice, i.e., referral QA, treatment recommendation, hospitalization (long document) summarization, patient education, pharmacology QA and drug interaction for emerging drugs. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs.
Read more6/27/2024