Text-to-Song: Towards Controllable Music Generation Incorporating Vocals and Accompaniment
2404.09313
0
0

Abstract
A song is a combination of singing voice and accompaniment. However, existing works focus on singing voice synthesis and music generation independently. Little attention was paid to explore song synthesis. In this work, we propose a novel task called text-to-song synthesis which incorporating both vocals and accompaniments generation. We develop Melodist, a two-stage text-to-song method that consists of singing voice synthesis (SVS) and vocal-to-accompaniment (V2A) synthesis. Melodist leverages tri-tower contrastive pretraining to learn more effective text representation for controllable V2A synthesis. A Chinese song dataset mined from a music website is built up to alleviate data scarcity for our research. The evaluation results on our dataset demonstrate that Melodist can synthesize songs with comparable quality and style consistency. Audio samples can be found in https://text2songMelodist.github.io/Sample/.
Create account to get full access
Overview
- This paper presents a novel approach to generating music with vocals and accompaniment, called "Text-to-Song", which aims to provide more control over the music generation process.
- The researchers developed a system that can generate complete songs, including both vocal melodies and instrumental accompaniment, based on input text.
- The system allows for fine-grained control over various aspects of the generated music, such as genre, mood, and lyrical content.
Plain English Explanation
The researchers have developed a way to automatically generate complete songs, including both the sung vocals and the instrumental accompaniment, based on written text. This is an important advancement because it gives users more control over the music that is generated, compared to previous systems that could only generate one component (like just the vocals or just the accompaniment).
With this new "Text-to-Song" system, users can provide input text that describes the type of song they want, such as the genre, mood, or lyrical content. The system then generates a full song that matches those specifications. This allows for more creativity and personalization in the music generation process.
For example, a user could provide text that describes a melancholic, folk-style song about loss. The Text-to-Song system would then generate an entire song - with sung vocals and guitar, piano, or other accompaniment - that fits that description. This gives musicians, composers, and even casual users much more flexibility and control over the music creation process.
Technical Explanation
The key innovation in this paper is the development of a system that can generate both the vocal melody and instrumental accompaniment for a song, based on input text. Previous music generation systems have typically focused on generating only one component, such as Content-based Controls for Music Generation using Large Language Modeling which generated accompaniment, or Tango 2: Aligning Diffusion-based Text-to-Audio Generation which generated vocals.
The researchers' "Text-to-Song" system uses a combination of language modeling and music generation techniques to produce complete songs. It takes in textual descriptions as input and outputs both a sung vocal melody and an instrumental accompaniment that match the provided text. This allows for fine-grained control over the generated music, including aspects like genre, mood, and lyrical content.
The system architecture includes several key components:
- A text encoder that maps the input text to a latent representation
- A vocal melody generator that produces the sung vocals based on the text encoding
- An accompaniment generator that produces the instrumental backing track
- A module that aligns and combines the vocals and accompaniment
Through experiments, the researchers demonstrated that their Text-to-Song system can generate coherent and realistic-sounding songs that match the provided textual descriptions. This represents an important step towards more controllable and expressive music generation.
Critical Analysis
One limitation of the research is that it was only evaluated on a relatively small dataset of song-text pairs. While the results are promising, further testing on larger and more diverse datasets would be needed to fully assess the system's capabilities and generalization.
Additionally, the paper does not provide much detail on the actual quality or creative expressiveness of the generated songs. While the system can produce complete songs, the paper does not delve into how musically compelling or artistically meaningful the output is. More subjective evaluation by human listeners would help to better understand the system's creative potential.
Furthermore, the researchers acknowledge that their system currently lacks the ability to explicitly model higher-level musical structure and form. Incorporating such structural considerations could lead to even more coherent and musically satisfying song generation.
Despite these limitations, the Text-to-Song system represents an important advance in music generation research, providing users with greater control and creative agency over the music creation process. Further refinement and expansion of this line of work could lead to exciting new possibilities for AI-assisted music composition and production.
Conclusion
This paper presents a novel "Text-to-Song" system that can generate complete songs, including both sung vocals and instrumental accompaniment, based on input text. This advance in music generation technology provides users with enhanced control over the creative process, allowing them to specify desired genre, mood, and lyrical content.
The researchers' approach combines language modeling and music generation techniques to produce coherent and realistic-sounding songs. While the system has some limitations in terms of dataset size and creative expressiveness, it represents an important step forward in the field of controllable and expressive music generation.
Further development of this technology could lead to new tools and applications for musicians, composers, and even casual users, empowering them to explore and create music in more personalized and artistically meaningful ways. As AI systems become increasingly capable of generating high-quality artistic content, research like this will be crucial in ensuring that the creative process remains under human control and direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
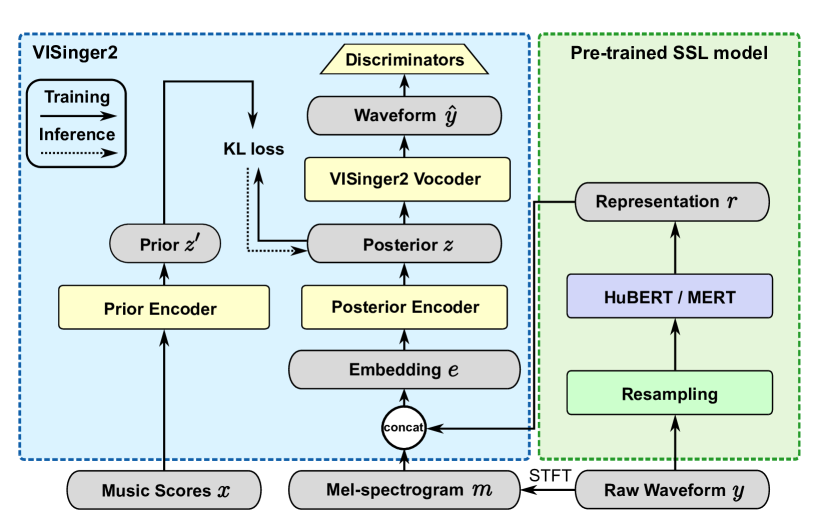
VISinger2+: End-to-End Singing Voice Synthesis Augmented by Self-Supervised Learning Representation
Yifeng Yu, Jiatong Shi, Yuning Wu, Shinji Watanabe
0
0
Singing Voice Synthesis (SVS) has witnessed significant advancements with the advent of deep learning techniques. However, a significant challenge in SVS is the scarcity of labeled singing voice data, which limits the effectiveness of supervised learning methods. In response to this challenge, this paper introduces a novel approach to enhance the quality of SVS by leveraging unlabeled data from pre-trained self-supervised learning models. Building upon the existing VISinger2 framework, this study integrates additional spectral feature information into the system to enhance its performance. The integration aims to harness the rich acoustic features from the pre-trained models, thereby enriching the synthesis and yielding a more natural and expressive singing voice. Experimental results in various corpora demonstrate the efficacy of this approach in improving the overall quality of synthesized singing voices in both objective and subjective metrics.
6/14/2024

MeLFusion: Synthesizing Music from Image and Language Cues using Diffusion Models
Sanjoy Chowdhury, Sayan Nag, K J Joseph, Balaji Vasan Srinivasan, Dinesh Manocha
0
0
Music is a universal language that can communicate emotions and feelings. It forms an essential part of the whole spectrum of creative media, ranging from movies to social media posts. Machine learning models that can synthesize music are predominantly conditioned on textual descriptions of it. Inspired by how musicians compose music not just from a movie script, but also through visualizations, we propose MeLFusion, a model that can effectively use cues from a textual description and the corresponding image to synthesize music. MeLFusion is a text-to-music diffusion model with a novel visual synapse, which effectively infuses the semantics from the visual modality into the generated music. To facilitate research in this area, we introduce a new dataset MeLBench, and propose a new evaluation metric IMSM. Our exhaustive experimental evaluation suggests that adding visual information to the music synthesis pipeline significantly improves the quality of generated music, measured both objectively and subjectively, with a relative gain of up to 67.98% on the FAD score. We hope that our work will gather attention to this pragmatic, yet relatively under-explored research area.
6/10/2024

MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance
Semin Kim, Myeonghun Jeong, Hyeonseung Lee, Minchan Kim, Byoung Jin Choi, Nam Soo Kim
0
0
In this paper, we propose MakeSinger, a semi-supervised training method for singing voice synthesis (SVS) via classifier-free diffusion guidance. The challenge in SVS lies in the costly process of gathering aligned sets of text, pitch, and audio data. MakeSinger enables the training of the diffusion-based SVS model from any speech and singing voice data regardless of its labeling, thereby enhancing the quality of generated voices with large amount of unlabeled data. At inference, our novel dual guiding mechanism gives text and pitch guidance on the reverse diffusion step by estimating the score of masked input. Experimental results show that the model trained in a semi-supervised manner outperforms other baselines trained only on the labeled data in terms of pronunciation, pitch accuracy and overall quality. Furthermore, we demonstrate that by adding Text-to-Speech (TTS) data in training, the model can synthesize the singing voices of TTS speakers even without their singing voices.
6/11/2024

Instruct-MusicGen: Unlocking Text-to-Music Editing for Music Language Models via Instruction Tuning
Yixiao Zhang, Yukara Ikemiya, Woosung Choi, Naoki Murata, Marco A. Mart'inez-Ram'irez, Liwei Lin, Gus Xia, Wei-Hsiang Liao, Yuki Mitsufuji, Simon Dixon
0
0
Recent advances in text-to-music editing, which employ text queries to modify music (e.g. by changing its style or adjusting instrumental components), present unique challenges and opportunities for AI-assisted music creation. Previous approaches in this domain have been constrained by the necessity to train specific editing models from scratch, which is both resource-intensive and inefficient; other research uses large language models to predict edited music, resulting in imprecise audio reconstruction. To Combine the strengths and address these limitations, we introduce Instruct-MusicGen, a novel approach that finetunes a pretrained MusicGen model to efficiently follow editing instructions such as adding, removing, or separating stems. Our approach involves a modification of the original MusicGen architecture by incorporating a text fusion module and an audio fusion module, which allow the model to process instruction texts and audio inputs concurrently and yield the desired edited music. Remarkably, Instruct-MusicGen only introduces 8% new parameters to the original MusicGen model and only trains for 5K steps, yet it achieves superior performance across all tasks compared to existing baselines, and demonstrates performance comparable to the models trained for specific tasks. This advancement not only enhances the efficiency of text-to-music editing but also broadens the applicability of music language models in dynamic music production environments.
5/30/2024