Jump to Conclusions: Short-Cutting Transformers With Linear Transformations

0
📉
Sign in to get full access
Overview
- Transformer-based language models create hidden representations at every layer, but only use the final-layer representations for prediction
- This obscures the internal decision-making process and the utility of the intermediate representations
- This paper introduces a simple method to "cast" the hidden representations as final representations, bypassing the transformer computation in-between
- This approach allows for better understanding of the model's internal representations and decision-making
Plain English Explanation
Transformer-based language models, like GPT-2 and BERT, create complex internal representations of the text they process. However, these models only use the final layer of representations to make their predictions, obscuring the insights that could be gained from the intermediate layers.
The researchers in this paper propose a simple way to "map" the hidden representations from the intermediate layers directly to the final prediction, bypassing the full transformer computation. This allows them to better understand how the model is making decisions at each stage of the process, rather than just looking at the final output.
The researchers find that this linear mapping approach is more effective at extracting useful information from the intermediate layers than the common practice of inspecting the hidden representations directly. They also show that in many cases, the model is actually able to predict the final output quite early in the processing, suggesting that the later layers may not be contributing as much new information as one might expect.
Additionally, the researchers demonstrate how this technique can be used to develop more efficient models that can make accurate predictions using fewer computational layers, potentially leading to faster and more resource-efficient language models.
Technical Explanation
The key idea behind this work is to bypass the full transformer computation and instead directly map the hidden representations from the intermediate layers to the final prediction. The researchers achieve this by learning a set of linear transformations that can approximate the model's internal decision-making process.
Specifically, they take the hidden representations from each layer of the transformer and use them to predict the final output of the model, rather than just using the representations from the last layer. This allows them to understand how the model is making decisions at each stage of the processing pipeline, rather than just looking at the final result.
The researchers find that this linear mapping approach significantly outperforms the common practice of inspecting the hidden representations directly, in terms of the ability to accurately predict the final output. They also show that for many language modeling tasks, the model is often able to make accurate predictions quite early in the processing, suggesting that the later layers may not be contributing as much new information as one might expect.
Furthermore, the researchers demonstrate how this technique can be used to develop more efficient models that can make accurate predictions using fewer computational layers, potentially leading to faster and more resource-efficient language models.
Critical Analysis
The researchers acknowledge several caveats and limitations of their approach. First, they note that the linear mapping may not be able to fully capture the complex non-linear transformations happening inside the transformer model. There may be important information being lost or distorted by the linear approximation.
Additionally, the researchers only evaluate their method on language modeling tasks, and it's unclear how well it would generalize to other types of transformer-based models and applications. Further research would be needed to understand the broader applicability of this technique.
Another potential issue is that the learned linear mappings may not be interpretable or generalizable, limiting their usefulness for gaining a deeper understanding of the model's internal representations and decision-making processes. It's possible that more structured approaches could provide more meaningful insights.
Finally, the researchers do not provide a thorough analysis of the computational and memory overhead introduced by their method, which could be an important practical consideration, especially when scaling to larger models.
Overall, this work presents an interesting and potentially useful approach for better understanding the inner workings of transformer-based language models. However, further research is needed to address the limitations and explore the broader applicability of this technique.
Conclusion
This paper introduces a simple method for "casting" the hidden representations of transformer-based language models as final representations, bypassing the full transformer computation. This allows for a better understanding of the model's internal decision-making process and the utility of its intermediate representations.
The researchers find that this linear mapping approach significantly outperforms the common practice of inspecting the hidden representations directly, and it can also be used to develop more efficient language models that make accurate predictions using fewer computational layers.
While the technique has some limitations, it represents an interesting step towards improving the interpretability and efficiency of transformer-based models, which are becoming increasingly important in a wide range of natural language processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Jump to Conclusions: Short-Cutting Transformers With Linear Transformations
Alexander Yom Din, Taelin Karidi, Leshem Choshen, Mor Geva
Transformer-based language models create hidden representations of their inputs at every layer, but only use final-layer representations for prediction. This obscures the internal decision-making process of the model and the utility of its intermediate representations. One way to elucidate this is to cast the hidden representations as final representations, bypassing the transformer computation in-between. In this work, we suggest a simple method for such casting, using linear transformations. This approximation far exceeds the prevailing practice of inspecting hidden representations from all layers, in the space of the final layer. Moreover, in the context of language modeling, our method produces more accurate predictions from hidden layers, across various model scales, architectures, and data distributions. This allows peeking into intermediate representations, showing that GPT-2 and BERT often predict the final output already in early layers. We then demonstrate the practicality of our method to recent early exit strategies, showing that when aiming, for example, at retention of 95% accuracy, our approach saves additional 7.9% layers for GPT-2 and 5.4% layers for BERT. Last, we extend our method to linearly approximate sub-modules, finding that attention is most tolerant to this change. Our code and learned mappings are publicly available at https://github.com/sashayd/mat.
Read more6/21/2024
🔎
25
Your Transformer is Secretly Linear
Anton Razzhigaev, Matvey Mikhalchuk, Elizaveta Goncharova, Nikolai Gerasimenko, Ivan Oseledets, Denis Dimitrov, Andrey Kuznetsov
This paper reveals a novel linear characteristic exclusive to transformer decoders, including models such as GPT, LLaMA, OPT, BLOOM and others. We analyze embedding transformations between sequential layers, uncovering a near-perfect linear relationship (Procrustes similarity score of 0.99). However, linearity decreases when the residual component is removed due to a consistently low output norm of the transformer layer. Our experiments show that removing or linearly approximating some of the most linear blocks of transformers does not affect significantly the loss or model performance. Moreover, in our pretraining experiments on smaller models we introduce a cosine-similarity-based regularization, aimed at reducing layer linearity. This regularization improves performance metrics on benchmarks like Tiny Stories and SuperGLUE and as well successfully decreases the linearity of the models. This study challenges the existing understanding of transformer architectures, suggesting that their operation may be more linear than previously assumed.
Read more5/22/2024
⚙️
0
A Symbolic Framework for Evaluating Mathematical Reasoning and Generalisation with Transformers
Jordan Meadows, Marco Valentino, Damien Teney, Andre Freitas
This paper proposes a methodology for generating and perturbing detailed derivations of equations at scale, aided by a symbolic engine, to evaluate the generalisability of Transformers to out-of-distribution mathematical reasoning problems. Instantiating the framework in the context of sequence classification tasks, we compare the capabilities of GPT-4, GPT-3.5, and a canon of fine-tuned BERT models, exploring the relationship between specific operators and generalisation failure via the perturbation of reasoning aspects such as symmetry and variable surface forms. Surprisingly, our empirical evaluation reveals that the average in-distribution performance of fine-tuned models surpasses GPT-3.5, and rivals GPT-4. However, perturbations to input reasoning can reduce their performance by up to 80 F1 points. Overall, the results suggest that the in-distribution performance of smaller open-source models may potentially rival GPT by incorporating appropriately structured derivation dependencies during training, and highlight a shared weakness between BERT and GPT involving a relative inability to decode indirect references to mathematical entities. We release the full codebase, constructed datasets, and fine-tuned models to encourage future progress in the field.
Read more4/9/2024
0
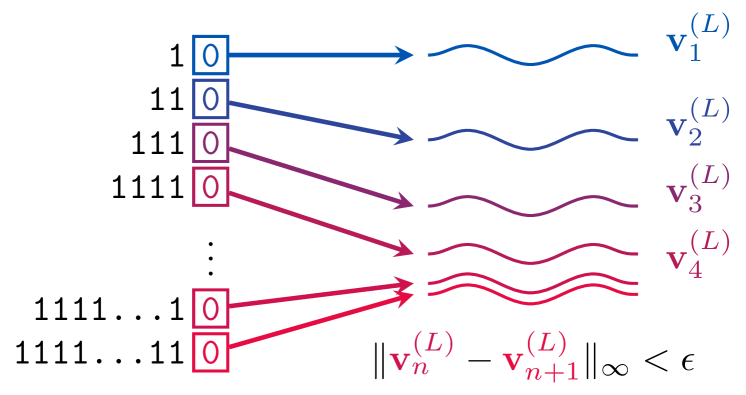
Transformers need glasses! Information over-squashing in language tasks
Federico Barbero, Andrea Banino, Steven Kapturowski, Dharshan Kumaran, Jo~ao G. M. Ara'ujo, Alex Vitvitskyi, Razvan Pascanu, Petar Veliv{c}kovi'c
We study how information propagates in decoder-only Transformers, which are the architectural backbone of most existing frontier large language models (LLMs). We rely on a theoretical signal propagation analysis -- specifically, we analyse the representations of the last token in the final layer of the Transformer, as this is the representation used for next-token prediction. Our analysis reveals a representational collapse phenomenon: we prove that certain distinct sequences of inputs to the Transformer can yield arbitrarily close representations in the final token. This effect is exacerbated by the low-precision floating-point formats frequently used in modern LLMs. As a result, the model is provably unable to respond to these sequences in different ways -- leading to errors in, e.g., tasks involving counting or copying. Further, we show that decoder-only Transformer language models can lose sensitivity to specific tokens in the input, which relates to the well-known phenomenon of over-squashing in graph neural networks. We provide empirical evidence supporting our claims on contemporary LLMs. Our theory also points to simple solutions towards ameliorating these issues.
Read more6/7/2024