JumpCoder: Go Beyond Autoregressive Coder via Online Modification
2401.07870
0
0
📈
Abstract
While existing code large language models (code LLMs) exhibit impressive capabilities in code generation, their autoregressive sequential generation inherently lacks reversibility. This limitation hinders them from timely correcting previous missing statements during coding as humans do, often leading to error propagation and suboptimal performance. We introduce JumpCoder, a novel model-agnostic framework that enables human-like online modification and non-sequential generation to augment code LLMs. The key idea behind JumpCoder is to insert new code into the currently generated code when necessary during generation, which is achieved through an auxiliary infilling model that works in tandem with the code LLM. Since identifying the best infill position beforehand is intractable, we adopt an textit{infill-first, judge-later} strategy, which experiments with filling at the $k$ most critical positions following the generation of each line, and uses an Abstract Syntax Tree (AST) parser alongside the Generation Model Scoring to effectively judge the validity of each potential infill. Extensive experiments using six state-of-the-art code LLMs across multiple and multilingual benchmarks consistently indicate significant improvements over all baselines. Our code is public at https://github.com/Keytoyze/JumpCoder.
Create account to get full access
Overview
- Existing code large language models (code LLMs) struggle with reversibility, meaning they can't easily correct previous mistakes during code generation.
- This limitation leads to error propagation and suboptimal performance.
- The paper introduces JumpCoder, a novel framework that enables human-like online modification and non-sequential generation to enhance code LLMs.
Plain English Explanation
The paper discusses a limitation of existing code large language models (code LLMs): they generate code sequentially, which means they can't easily go back and fix mistakes they made earlier in the process. This can lead to errors building up and the final code being suboptimal.
To address this, the researchers developed a new framework called JumpCoder. The key idea behind JumpCoder is to allow the model to insert new code into the currently generated code when necessary, rather than just generating sequentially. This is achieved through an auxiliary "infilling" model that works alongside the main code LLM.
Since it's difficult to predict the best places to insert new code ahead of time, JumpCoder takes an "infill-first, judge-later" approach. It experiments with inserting code at multiple potential positions, and then uses an code analysis tool (an Abstract Syntax Tree parser) along with the main model's own evaluation to determine the validity of each potential insertion.
Through extensive testing on multiple benchmarks and state-of-the-art code LLMs, the researchers show that JumpCoder significantly improves performance compared to the baseline models.
Technical Explanation
The paper introduces JumpCoder, a novel model-agnostic framework that aims to address the reversibility limitation of existing code large language models (code LLMs). Code LLMs generate code sequentially, which makes it difficult for them to correct previous mistakes, leading to error propagation and suboptimal performance.
The key innovation in JumpCoder is the ability to insert new code into the currently generated code when necessary, rather than just generating sequentially. This is achieved through an auxiliary "infilling" model that works in tandem with the code LLM. Since identifying the best infill position beforehand is intractable, JumpCoder adopts an "infill-first, judge-later" strategy:
- It experiments with filling in the k most critical positions following the generation of each line.
- It then uses an Abstract Syntax Tree (AST) parser alongside the Generation Model Scoring to effectively judge the validity of each potential infill.
The researchers extensively evaluate JumpCoder using six state-of-the-art code LLMs across multiple and multilingual benchmarks. The results consistently show significant improvements over all baselines, demonstrating the effectiveness of the proposed framework.
Critical Analysis
The paper presents a compelling solution to the reversibility limitation of existing code large language models. The "infill-first, judge-later" approach seems to be a clever way to overcome the challenge of predicting the best infill positions in advance.
However, the paper could have discussed the computational and memory overhead introduced by the auxiliary infilling model and the AST parsing step. While the performance gains are significant, the additional complexity may make the framework less practical for certain real-world applications with strict latency or resource constraints.
Additionally, the paper does not explore the impact of the infilling strategy on the coherence and readability of the generated code. Inserting new code at arbitrary positions could potentially disrupt the logical flow and structure of the code, which may be an important consideration for human developers using the generated code.
Further research could investigate ways to optimize the infilling process, such as by incorporating code semantics or context-aware heuristics to predict the most suitable insertion points. Evaluating the generated code's maintainability and readability would also be a valuable addition to the analysis.
Conclusion
The JumpCoder framework proposed in this paper represents a significant advancement in addressing the reversibility limitations of existing code large language models. By enabling human-like online modification and non-sequential generation, JumpCoder has the potential to improve the quality and reliability of code generated by language models, benefiting both developers and the broader software engineering community.
While the paper highlights impressive performance gains, further research is needed to fully understand the practical implications and address potential limitations of the framework. Exploring ways to optimize the infilling process and evaluate the broader impact on code maintainability and readability could lead to even more robust and user-friendly code generation solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Self-Infilling Code Generation
Lin Zheng, Jianbo Yuan, Zhi Zhang, Hongxia Yang, Lingpeng Kong
0
0
This work introduces self-infilling code generation, a general framework that incorporates infilling operations into auto-regressive decoding. Our approach capitalizes on the observation that recent infilling-capable code language models can self-infill: whereas infilling operations aim to fill in the middle based on a predefined prefix and suffix, self-infilling sequentially generates both such surrounding context and the infilled content. We utilize this capability to introduce novel interruption and looping mechanisms in conventional decoding, evolving it into a non-monotonic process. Interruptions allow for postponing the generation of specific code until a definitive suffix is established, enhancing control over the output. Meanwhile, the looping mechanism, which leverages the complementary nature of self-infilling and left-to-right decoding, can iteratively update and synchronize each piece of generation cyclically. Extensive experiments are conducted to demonstrate that our proposed decoding process is effective in enhancing both regularity and quality across several code generation benchmarks.
5/28/2024
💬
AutoCoder: Enhancing Code Large Language Model with textsc{AIEV-Instruct}
Bin Lei, Yuchen Li, Qiuwu Chen
0
0
We introduce AutoCoder, the first Large Language Model to surpass GPT-4 Turbo (April 2024) and GPT-4o in pass@1 on the Human Eval benchmark test ($mathbf{90.9%}$ vs. $mathbf{90.2%}$). In addition, AutoCoder offers a more versatile code interpreter compared to GPT-4 Turbo and GPT-4o. It's code interpreter can install external packages instead of limiting to built-in packages. AutoCoder's training data is a multi-turn dialogue dataset created by a system combining agent interaction and external code execution verification, a method we term textbf{textsc{AIEV-Instruct}} (Instruction Tuning with Agent-Interaction and Execution-Verified). Compared to previous large-scale code dataset generation methods, textsc{AIEV-Instruct} reduces dependence on proprietary large models and provides execution-validated code dataset. The code and the demo video is available in url{https://github.com/bin123apple/AutoCoder}.
5/27/2024
🏋️
SemCoder: Training Code Language Models with Comprehensive Semantics
Yangruibo Ding, Jinjun Peng, Marcus J. Min, Gail Kaiser, Junfeng Yang, Baishakhi Ray
0
0
Code Large Language Models (Code LLMs) have excelled at tasks like code completion but often miss deeper semantics such as execution effects and dynamic states. This paper aims to bridge the gap between Code LLMs' reliance on static text data and the need for thorough semantic understanding for complex tasks like debugging and program repair. We introduce a novel strategy to train Code LLMs with comprehensive semantics, encompassing high-level functional descriptions, local execution effects of individual statements, and overall input/output behavior, thereby linking static code text with dynamic execution states. We begin by collecting PyX, a clean code corpus of fully executable samples with functional descriptions and execution tracing. We propose training Code LLMs to write code and represent and reason about execution behaviors using natural language, mimicking human verbal debugging. This approach led to the development of SemCoder, a Code LLM with only 6.7B parameters, which shows competitive performance with GPT-3.5-turbo on code generation and execution reasoning tasks. SemCoder achieves 81.1% on HumanEval (GPT-3.5-turbo: 76.8%) and 54.5% on CRUXEval-I (GPT-3.5-turbo: 50.3%). We also study the effectiveness of SemCoder's monologue-style execution reasoning compared to concrete scratchpad reasoning, showing that our approach integrates semantics from multiple dimensions more smoothly. Finally, we demonstrate the potential of applying learned semantics to improve Code LLMs' debugging and self-refining capabilities.
6/4/2024
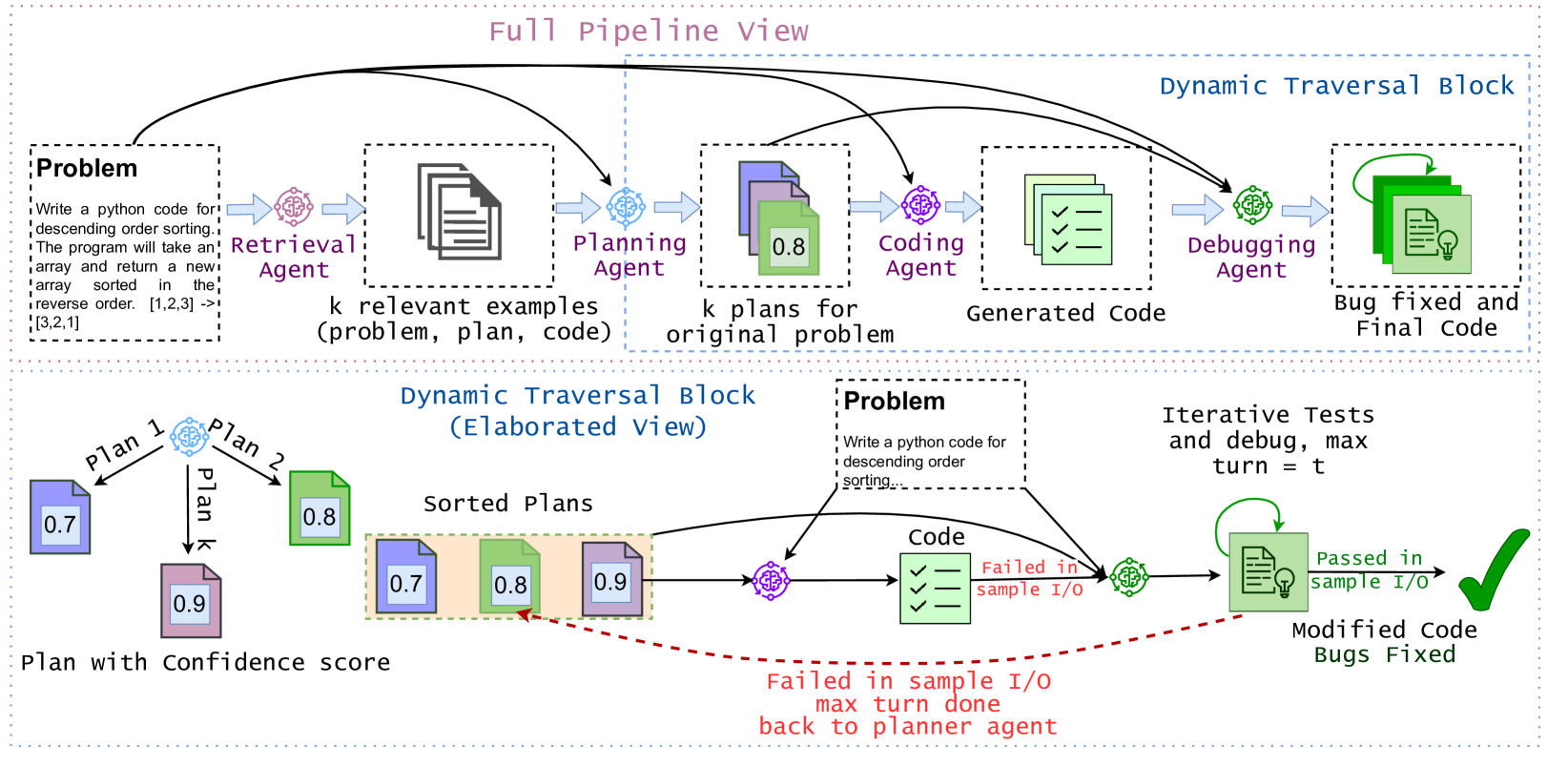
MapCoder: Multi-Agent Code Generation for Competitive Problem Solving
Md. Ashraful Islam, Mohammed Eunus Ali, Md Rizwan Parvez
0
0
Code synthesis, which requires a deep understanding of complex natural language problem descriptions, generation of code instructions for complex algorithms and data structures, and the successful execution of comprehensive unit tests, presents a significant challenge. While large language models (LLMs) demonstrate impressive proficiency in natural language processing, their performance in code generation tasks remains limited. In this paper, we introduce a new approach to code generation tasks leveraging multi-agent prompting that uniquely replicates the full cycle of program synthesis as observed in human developers. Our framework, MapCoder, consists of four LLM agents specifically designed to emulate the stages of this cycle: recalling relevant examples, planning, code generation, and debugging. After conducting thorough experiments, with multiple LLM ablations and analyses across eight challenging competitive problem-solving and program synthesis benchmarks, MapCoder showcases remarkable code generation capabilities, achieving new state-of-the-art results (pass@1) on HumanEval (93.9%), MBPP (83.1%), APPS (22.0%), CodeContests (28.5%), and xCodeEval (45.3%). Moreover, our method consistently delivers superior performance across various programming languages and varying problem difficulties. We open-source our framework at https://github.com/Md-Ashraful-Pramanik/MapCoder.
5/21/2024