Self-Infilling Code Generation
2311.17972
0
0
🛸
Abstract
This work introduces self-infilling code generation, a general framework that incorporates infilling operations into auto-regressive decoding. Our approach capitalizes on the observation that recent infilling-capable code language models can self-infill: whereas infilling operations aim to fill in the middle based on a predefined prefix and suffix, self-infilling sequentially generates both such surrounding context and the infilled content. We utilize this capability to introduce novel interruption and looping mechanisms in conventional decoding, evolving it into a non-monotonic process. Interruptions allow for postponing the generation of specific code until a definitive suffix is established, enhancing control over the output. Meanwhile, the looping mechanism, which leverages the complementary nature of self-infilling and left-to-right decoding, can iteratively update and synchronize each piece of generation cyclically. Extensive experiments are conducted to demonstrate that our proposed decoding process is effective in enhancing both regularity and quality across several code generation benchmarks.
Create account to get full access
Overview
- This paper introduces a new framework called "self-infilling code generation" that enhances traditional auto-regressive code generation models.
- The key insight is that recent language models can "self-infill" - they can generate both the context around a missing section and the content to fill that section.
- The paper leverages this capability to develop novel "interruption" and "looping" mechanisms that make the code generation process more flexible and controllable.
- Experiments show this approach can improve the regularity and quality of generated code across multiple benchmarks.
Plain English Explanation
The paper describes a new way to generate computer code using machine learning models. Traditional code generation models work by predicting the next word or line of code one piece at a time, in a linear left-to-right fashion.
However, the researchers noticed that some of the latest language models for code like the ones described in these papers have an interesting capability - they can "self-infill". This means they can not only generate the missing middle part of a piece of code, but also the surrounding context (the code before and after the missing part).
The researchers decided to build on this "self-infilling" ability to create a more flexible code generation process. They introduced two new mechanisms:
-
Interruptions: This allows the model to postpone generating certain parts of the code until it has a better idea of how the full code should look. This gives the model more control over the final output.
-
Looping: This allows the model to go back and update/synchronize different parts of the generated code in an iterative, cyclical way. The model can leverage the strengths of both the self-infilling and the traditional left-to-right generation approaches.
Through extensive testing, the researchers found that this new self-infilling code generation framework could produce code that is more regular and higher quality compared to standard methods. It seems to be a promising direction for improving automated code generation.
Technical Explanation
The core innovation of this work is the integration of "infilling" capabilities into traditional auto-regressive code generation. Recent language models like this one have demonstrated the ability to "self-infill" - they can generate both the context around a missing section and the content to fill that section.
The researchers leverage this self-infilling capability to introduce novel "interruption" and "looping" mechanisms into the code generation process. Interruptions allow the model to postpone generating specific code fragments until a more definitive surrounding context is established, enhancing control over the output. The looping mechanism, which combines self-infilling and left-to-right decoding, enables iterative updating and synchronization of the generated code.
Extensive experiments are conducted on several code generation benchmarks. The results demonstrate that the proposed self-infilling decoding process is effective in improving both the regularity and quality of the generated code compared to standard auto-regressive approaches.
Critical Analysis
The paper provides a thorough technical explanation of the self-infilling code generation framework and its underlying mechanisms. The experimental results are promising, showing improvements in code quality and regularity across multiple benchmarks.
However, the paper does not extensively discuss potential limitations or caveats of the approach. For example, it's unclear how the model would perform on more complex, real-world code generation tasks, or how it would scale to larger codebases. Additionally, the paper does not address potential issues with the reliability and safety of the generated code.
Further research could explore the robustness of the self-infilling framework, its performance on a wider range of code generation tasks, and ways to enhance the verification of the generated outputs. Ultimately, while this work represents an interesting advance in code generation, more work is needed to fully understand its practical implications and limitations.
Conclusion
This paper introduces a novel "self-infilling code generation" framework that enhances traditional auto-regressive code generation by leveraging the ability of recent language models to "self-infill" - generating both the context and content of missing code segments.
The key innovations are the introduction of "interruption" and "looping" mechanisms that provide more flexibility and control over the code generation process. Experiments show this approach can improve the regularity and quality of generated code across multiple benchmarks, suggesting it is a promising direction for advancing automated code generation capabilities.
While the technical details and results are promising, the paper does not extensively address potential limitations or areas for further research. Nonetheless, this work represents an interesting step forward in enhancing the reliability and capabilities of code generation models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
JumpCoder: Go Beyond Autoregressive Coder via Online Modification
Mouxiang Chen, Hao Tian, Zhongxin Liu, Xiaoxue Ren, Jianling Sun
0
0
While existing code large language models (code LLMs) exhibit impressive capabilities in code generation, their autoregressive sequential generation inherently lacks reversibility. This limitation hinders them from timely correcting previous missing statements during coding as humans do, often leading to error propagation and suboptimal performance. We introduce JumpCoder, a novel model-agnostic framework that enables human-like online modification and non-sequential generation to augment code LLMs. The key idea behind JumpCoder is to insert new code into the currently generated code when necessary during generation, which is achieved through an auxiliary infilling model that works in tandem with the code LLM. Since identifying the best infill position beforehand is intractable, we adopt an textit{infill-first, judge-later} strategy, which experiments with filling at the $k$ most critical positions following the generation of each line, and uses an Abstract Syntax Tree (AST) parser alongside the Generation Model Scoring to effectively judge the validity of each potential infill. Extensive experiments using six state-of-the-art code LLMs across multiple and multilingual benchmarks consistently indicate significant improvements over all baselines. Our code is public at https://github.com/Keytoyze/JumpCoder.
6/6/2024
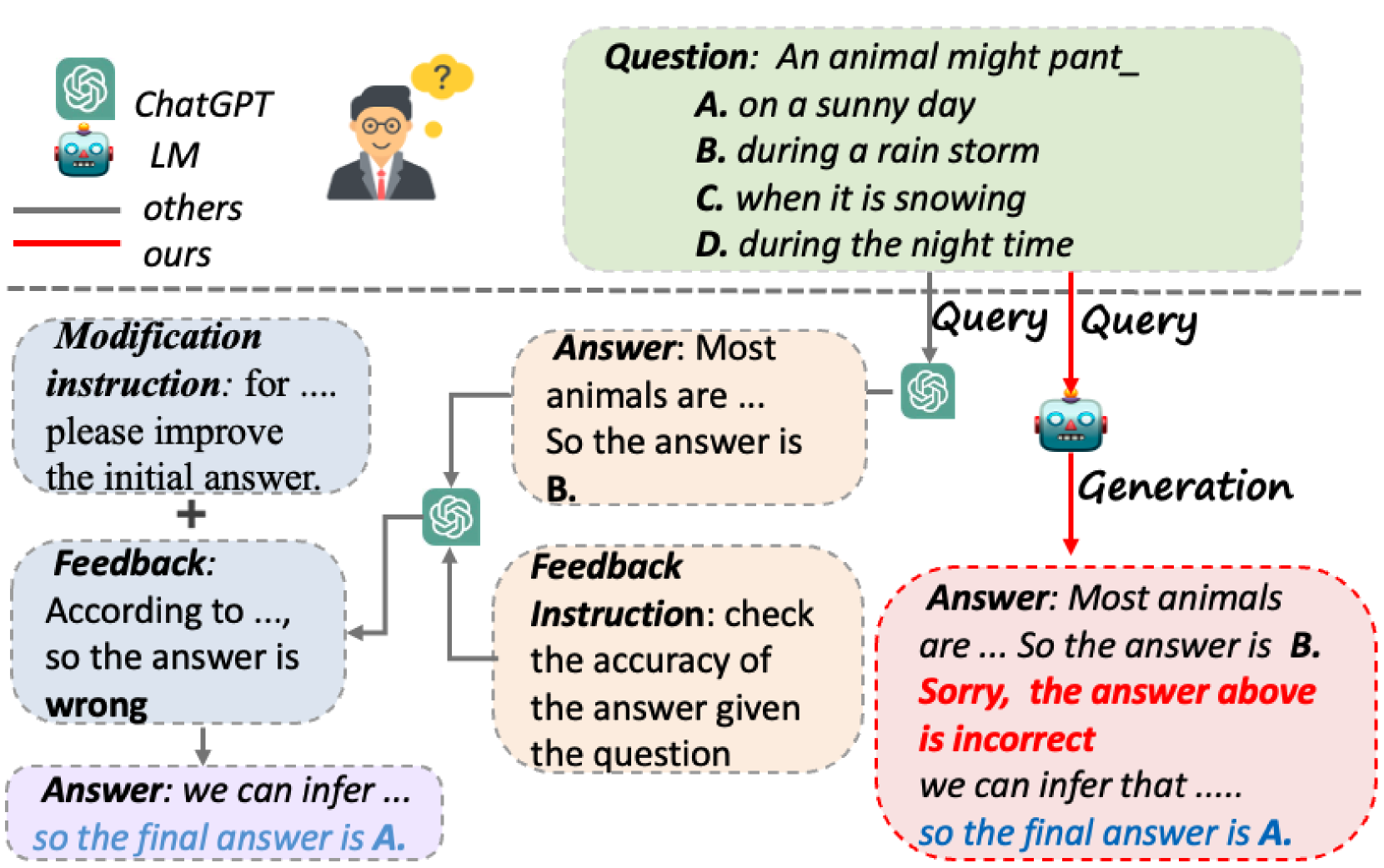
Small Language Model Can Self-correct
Haixia Han, Jiaqing Liang, Jie Shi, Qianyu He, Yanghua Xiao
0
0
Generative Language Models (LMs) such as ChatGPT have exhibited remarkable performance across various downstream tasks. Nevertheless, one of their most prominent drawbacks is generating inaccurate or false information with a confident tone. Previous studies have devised sophisticated pipelines and prompts to induce large LMs to exhibit the capability for self-correction. However, large LMs are explicitly prompted to verify and modify its answers separately rather than completing all steps spontaneously like humans. Moreover, these complex prompts are extremely challenging for small LMs to follow. In this paper, we introduce the underline{I}ntrinsic underline{S}elf-underline{C}orrection (ISC) in generative language models, aiming to correct the initial output of LMs in a self-triggered manner, even for those small LMs with 6 billion parameters. Specifically, we devise a pipeline for constructing self-correction data and propose Partial Answer Masking (PAM), aiming to endow the model with the capability for intrinsic self-correction through fine-tuning. We conduct experiments using LMs with parameters sizes ranging from 6 billion to 13 billion in two tasks, including commonsense reasoning and factual knowledge reasoning. Our experiments demonstrate that the outputs generated using ISC outperform those generated without self-correction. We believe that the output quality of even small LMs can be further improved by empowering them with the ability to intrinsic self-correct.
5/14/2024

Training LLMs to Better Self-Debug and Explain Code
Nan Jiang, Xiaopeng Li, Shiqi Wang, Qiang Zhou, Soneya Binta Hossain, Baishakhi Ray, Varun Kumar, Xiaofei Ma, Anoop Deoras
0
0
In the domain of code generation, self-debugging is crucial. It allows LLMs to refine their generated code based on execution feedback. This is particularly important because generating correct solutions in one attempt proves challenging for complex tasks. Prior works on self-debugging mostly focus on prompting methods by providing LLMs with few-shot examples, which work poorly on small open-sourced LLMs. In this work, we propose a training framework that significantly improves self-debugging capability of LLMs. Intuitively, we observe that a chain of explanations on the wrong code followed by code refinement helps LLMs better analyze the wrong code and do refinement. We thus propose an automated pipeline to collect a high-quality dataset for code explanation and refinement by generating a number of explanations and refinement trajectories and filtering via execution verification. We perform supervised fine-tuning (SFT) and further reinforcement learning (RL) on both success and failure trajectories with a novel reward design considering code explanation and refinement quality. SFT improves the pass@1 by up to 15.92% and pass@10 by 9.30% over four benchmarks. RL training brings additional up to 3.54% improvement on pass@1 and 2.55% improvement on pass@10. The trained LLMs show iterative refinement ability, and can keep refining code continuously. Lastly, our human evaluation shows that the LLMs trained with our framework generate more useful code explanations and help developers better understand bugs in source code.
5/30/2024
🏷️
Generation-driven Contrastive Self-training for Zero-shot Text Classification with Instruction-following LLM
Ruohong Zhang, Yau-Shian Wang, Yiming Yang
0
0
The remarkable performance of large language models (LLMs) in zero-shot language understanding has garnered significant attention. However, employing LLMs for large-scale inference or domain-specific fine-tuning requires immense computational resources due to their substantial model size. To overcome these limitations, we introduce a novel method, namely GenCo, which leverages the strong generative power of LLMs to assist in training a smaller and more adaptable language model. In our method, an LLM plays an important role in the self-training loop of a smaller model in two important ways. Firstly, the LLM is used to augment each input instance with a variety of possible continuations, enriching its semantic context for better understanding. Secondly, it helps crafting additional high-quality training pairs, by rewriting input texts conditioned on predicted labels. This ensures the generated texts are highly relevant to the predicted labels, alleviating the prediction error during pseudo-labeling, while reducing the dependency on large volumes of unlabeled text. In our experiments, GenCo outperforms previous state-of-the-art methods when only limited ($<5%$ of original) in-domain text data is available. Notably, our approach surpasses the performance of Alpaca-7B with human prompts, highlighting the potential of leveraging LLM for self-training.
4/16/2024