Just Ask One More Time! Self-Agreement Improves Reasoning of Language Models in (Almost) All Scenarios
2311.08154
0
0
💬
Abstract
Although chain-of-thought (CoT) prompting combined with language models has achieved encouraging results on complex reasoning tasks, the naive greedy decoding used in CoT prompting usually causes the repetitiveness and local optimality. To address this shortcoming, ensemble-optimization tries to obtain multiple reasoning paths to get the final answer assembly. However, current ensemble-optimization methods either simply employ rule-based post-processing such as textit{self-consistency}, or train an additional model based on several task-related human annotations to select the best one among multiple reasoning paths, yet fail to generalize to realistic settings where the type of input questions is unknown or the answer format of reasoning paths is unknown. To avoid their limitations, we propose textbf{Self-Agreement}, a generalizable ensemble-optimization method applying in almost all scenarios where the type of input questions and the answer format of reasoning paths may be known or unknown. Self-agreement firstly samples from language model's decoder to generate a textit{diverse} set of reasoning paths, and subsequently prompts the language model textit{one more time} to determine the optimal answer by selecting the most textit{agreed} answer among the sampled reasoning paths. Self-agreement simultaneously achieves remarkable performance on six public reasoning benchmarks and superior generalization capabilities.
Create account to get full access
Overview
- Chain-of-thought (CoT) prompting combined with language models has achieved promising results on complex reasoning tasks, but the greedy decoding used in CoT prompting often leads to repetitiveness and local optimality.
- Ensemble-optimization methods aim to obtain multiple reasoning paths to assemble the final answer, but current approaches have limitations in generalizing to realistic settings where the input question type or answer format is unknown.
- To address these limitations, the paper proposes a new method called Self-Agreement that can be applied in various scenarios.
Plain English Explanation
Chain-of-thought (CoT) prompting is a technique that combines language models with a step-by-step reasoning process to tackle complex problems. While this approach has shown promising results, the way it generates the final answer (called "greedy decoding") can sometimes lead to repetitive or suboptimal solutions.
To address this, researchers have tried "ensemble-optimization" methods, which generate multiple potential reasoning paths and then select the best one. However, these current approaches have limitations - they either use simple rule-based post-processing, or require additional training on task-specific human annotations, which may not generalize well to real-world scenarios where the input questions or answer formats are unpredictable.
The new Self-Agreement method proposed in this paper aims to overcome these limitations. It first generates a diverse set of potential reasoning paths by sampling from the language model's decoder. Then, it prompts the model one more time to determine the optimal answer by selecting the "most agreed-upon" path among the sampled options. This allows the model to self-evaluate and choose the best reasoning without being limited by the type of input or output format.
The researchers show that Self-Agreement can achieve strong performance across a variety of public reasoning benchmarks, while also demonstrating superior generalization capabilities compared to previous methods.
Technical Explanation
The paper proposes a new ensemble-optimization method called Self-Agreement to address the limitations of current approaches in chain-of-thought (CoT) prompting.
The key elements of Self-Agreement are:
- Diverse Path Sampling: The method first samples a set of diverse reasoning paths from the language model's decoder, rather than relying on a single greedy output.
- Self-Evaluation: The model is then prompted one more time to evaluate the sampled paths and select the "most agreed-upon" answer, without relying on any additional task-specific training or annotations.
This allows Self-Agreement to be applied in a wide range of scenarios, even when the input question type or answer format is unknown, unlike previous ensemble-optimization methods that have certain limitations in this regard.
The researchers evaluate Self-Agreement on six public reasoning benchmarks and demonstrate that it can achieve remarkable performance while also exhibiting superior generalization capabilities compared to prior approaches.
Critical Analysis
The Self-Agreement method represents an interesting and promising direction for improving the reasoning capabilities of large language models. By generating a diverse set of potential reasoning paths and then having the model self-evaluate to select the best one, the approach aims to overcome the limitations of greedy decoding and task-specific training.
However, the paper does not extensively explore the potential drawbacks or limitations of the Self-Agreement method. For example, it is unclear how the method would perform on more complex or open-ended reasoning tasks, or how sensitive it is to the quality and diversity of the initial set of sampled paths.
Additionally, the Self-Agreement approach relies on prompting the language model multiple times, which could potentially increase the computational cost and latency of the reasoning process. It would be valuable to investigate the trade-offs between performance and efficiency in future research.
Self-Agreement also does not address the potential biases or limitations of the underlying language model, which could still influence the quality of the reasoning paths and the final selected answer.
Overall, the Self-Agreement method represents an important step forward in enhancing the reasoning capabilities of large language models, but further research is needed to fully understand its strengths, weaknesses, and potential real-world applications.
Conclusion
The paper proposes a novel ensemble-optimization method called Self-Agreement to address the limitations of current approaches in chain-of-thought (CoT) prompting. Self-Agreement generates a diverse set of reasoning paths and then has the language model self-evaluate to select the most "agreed-upon" answer, without relying on task-specific training or annotations.
This method demonstrates strong performance on a variety of public reasoning benchmarks and shows superior generalization capabilities compared to previous ensemble-optimization techniques. The Self-Agreement approach represents an important step forward in enhancing the reasoning abilities of large language models, which could have significant implications for a wide range of AI applications that require complex problem-solving and decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Self-Polish: Enhance Reasoning in Large Language Models via Problem Refinement
Zhiheng Xi, Senjie Jin, Yuhao Zhou, Rui Zheng, Songyang Gao, Tao Gui, Qi Zhang, Xuanjing Huang
0
0
To enhance the multi-step reasoning capabilities of large language models, researchers have extensively explored prompting methods, notably the Chain-of-Thought (CoT) method which explicitly elicits human-like rationales. However, they have inadvertently overlooked the potential of enhancing model reasoning performance by formulating higher-quality problems. In this work, we start from the problem side and propose Self-Polish (SP), a novel method that facilitates the model's reasoning by guiding it to progressively refine the given problems to be more comprehensible and solvable. We also explore several automatic prompting varients and propose the Self-Polish prompt bank for the community. SP is orthogonal to all other prompting methods of answer/reasoning side like CoT, allowing for seamless integration with state-of-the-art techniques for further improvement. Thorough experiments show that the proposed method attains notable and consistent effectiveness on five reasoning benchmarks across different models. Furthermore, our method also showcases impressive performance on robustness evaluation. Codes and prompts are available at https://github.com/WooooDyy/Self-Polish.
4/19/2024
💬
Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models
Zhangyue Yin, Qiushi Sun, Qipeng Guo, Zhiyuan Zeng, Xiaonan Li, Tianxiang Sun, Cheng Chang, Qinyuan Cheng, Ding Wang, Xiaofeng Mou, Xipeng Qiu, XuanJing Huang
0
0
Recent advancements in Chain-of-Thought prompting have facilitated significant breakthroughs for Large Language Models (LLMs) in complex reasoning tasks. Current research enhances the reasoning performance of LLMs by sampling multiple reasoning chains and ensembling based on the answer frequency. However, this approach fails in scenarios where the correct answers are in the minority. We identify this as a primary factor constraining the reasoning capabilities of LLMs, a limitation that cannot be resolved solely based on the predicted answers. To address this shortcoming, we introduce a hierarchical reasoning aggregation framework AoR (Aggregation of Reasoning), which selects answers based on the evaluation of reasoning chains. Additionally, AoR incorporates dynamic sampling, adjusting the number of reasoning chains in accordance with the complexity of the task. Experimental results on a series of complex reasoning tasks show that AoR outperforms prominent ensemble methods. Further analysis reveals that AoR not only adapts various LLMs but also achieves a superior performance ceiling when compared to current methods.
5/22/2024
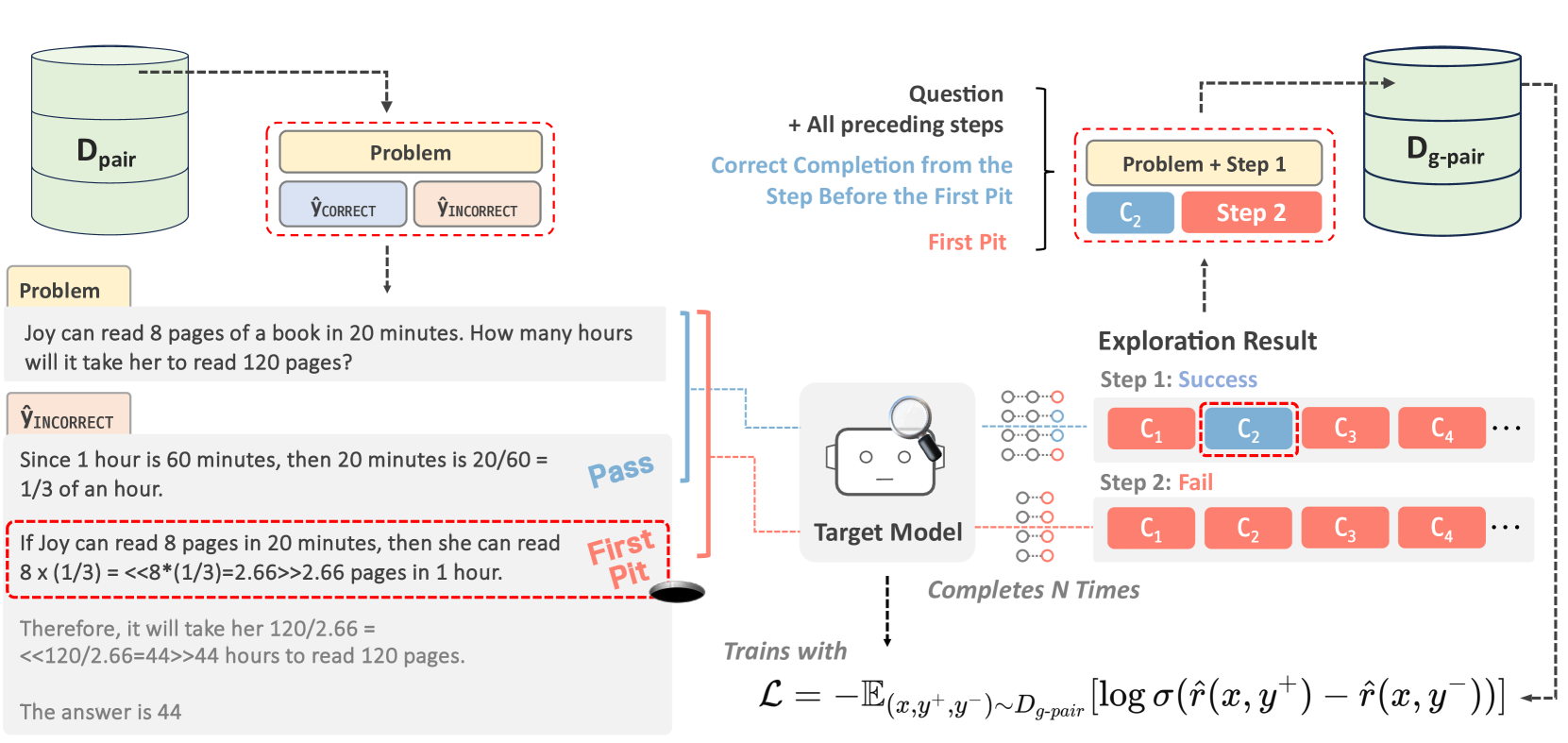
Self-Explore to Avoid the Pit: Improving the Reasoning Capabilities of Language Models with Fine-grained Rewards
Hyeonbin Hwang, Doyoung Kim, Seungone Kim, Seonghyeon Ye, Minjoon Seo
0
0
Training on large amounts of rationales (i.e., CoT Fine-tuning) is effective at improving the reasoning capabilities of large language models (LLMs). However, acquiring human-authored rationales or augmenting rationales from proprietary models is costly and not scalable. In this paper, we study the problem of whether LLMs could self-improve their reasoning capabilities. To this end, we propose Self-Explore, where the LLM is tasked to explore the first wrong step (i.e., the first pit) within the rationale and use such signals as fine-grained rewards for further improvement. On the GSM8K and MATH test set, Self-Explore achieves 11.57% and 2.89% improvement on average across three LLMs compared to supervised fine-tuning (SFT). Our code is available at https://github.com/hbin0701/Self-Explore.
5/17/2024
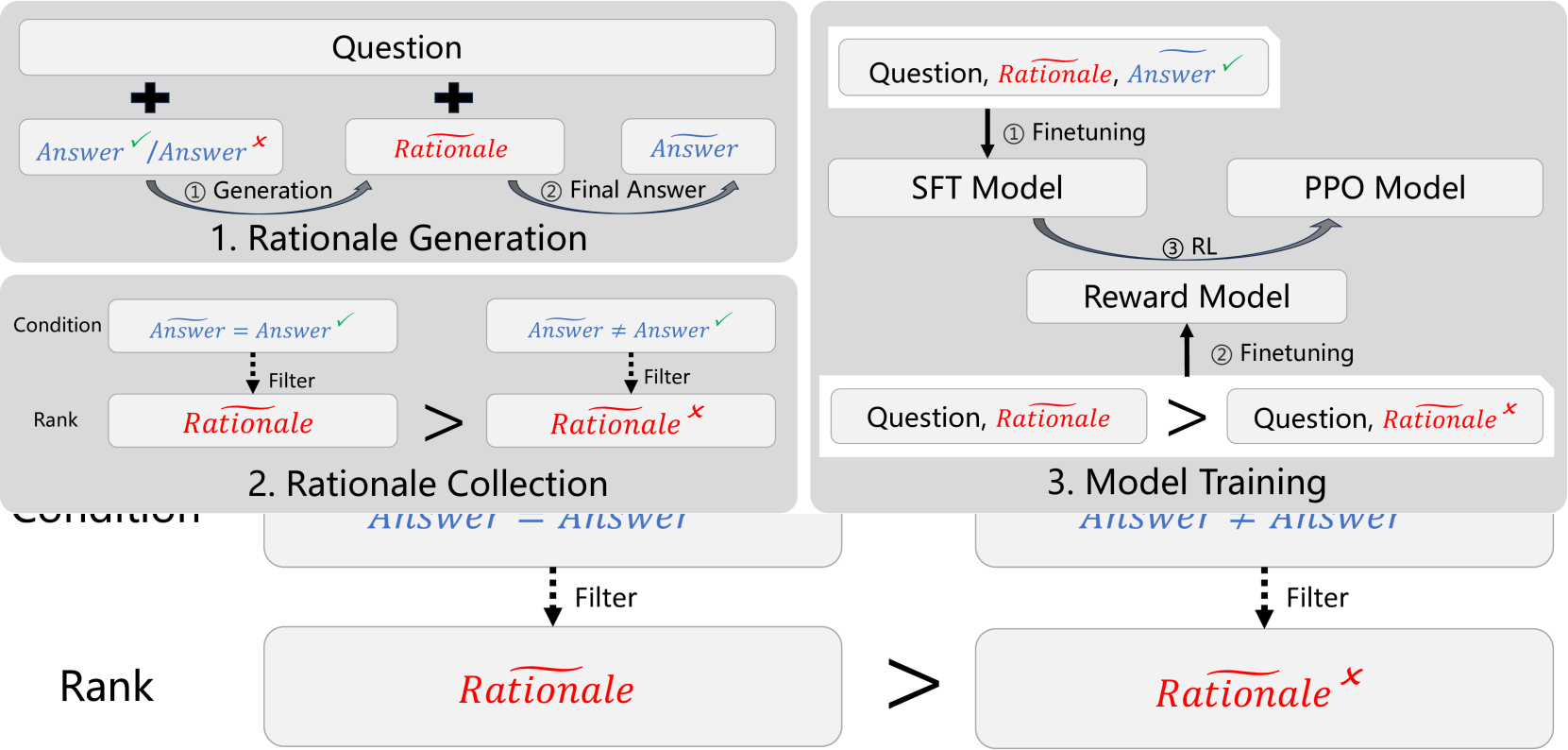
Improving Language Model Reasoning with Self-motivated Learning
Yunlong Feng, Yang Xu, Libo Qin, Yasheng Wang, Wanxiang Che
0
0
Large-scale high-quality training data is important for improving the performance of models. After trained with data that has rationales (reasoning steps), models gain reasoning capability. However, the dataset with high-quality rationales is relatively scarce due to the high annotation cost. To address this issue, we propose textit{Self-motivated Learning} framework. The framework motivates the model itself to automatically generate rationales on existing datasets. Based on the inherent rank from correctness across multiple rationales, the model learns to generate better rationales, leading to higher reasoning capability. Specifically, we train a reward model with the rank to evaluate the quality of rationales, and improve the performance of reasoning through reinforcement learning. Experiment results of Llama2 7B on multiple reasoning datasets show that our method significantly improves the reasoning ability of models, even outperforming text-davinci-002 in some datasets.
5/1/2024