Self-Explore to Avoid the Pit: Improving the Reasoning Capabilities of Language Models with Fine-grained Rewards
2404.10346
0
0
Abstract
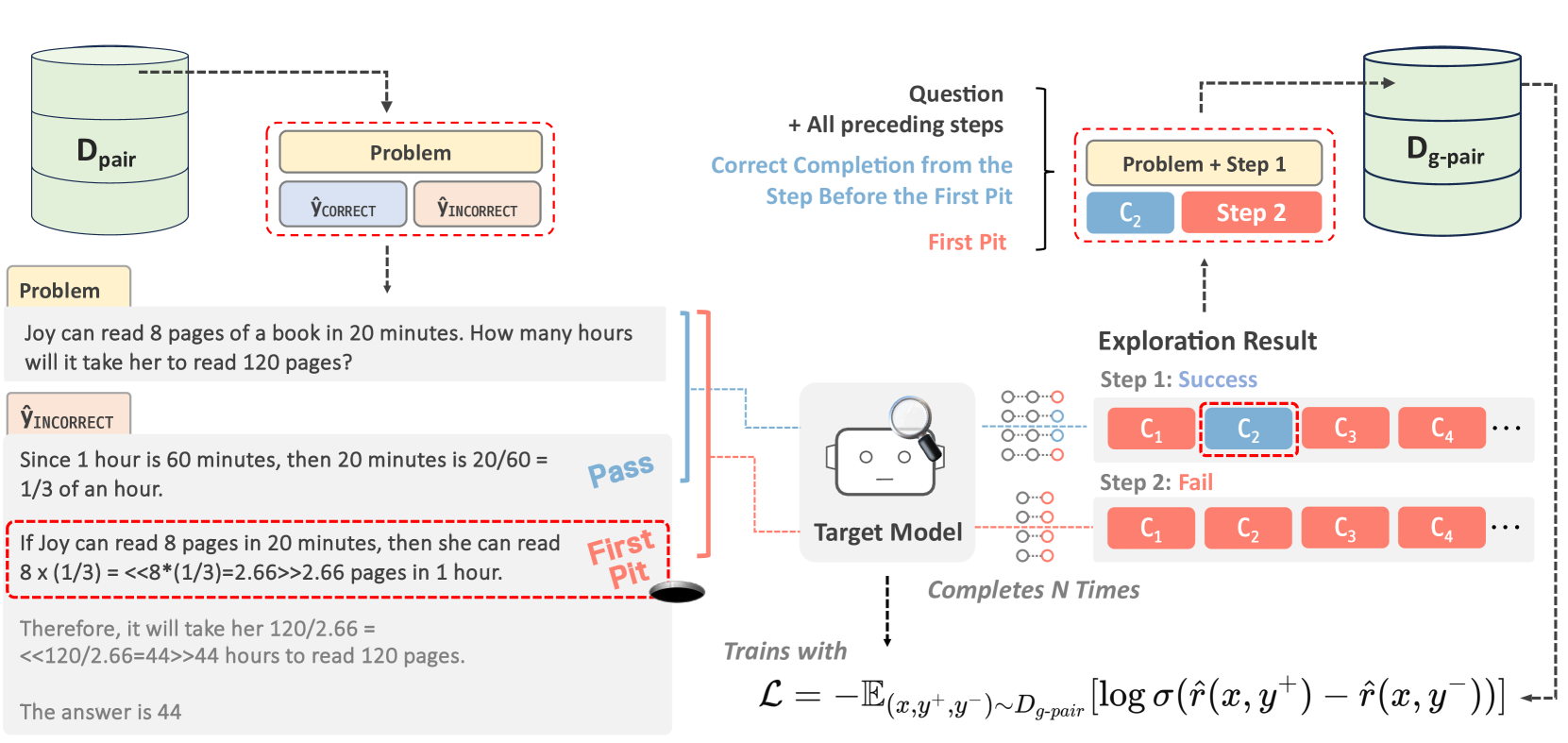
Training on large amounts of rationales (i.e., CoT Fine-tuning) is effective at improving the reasoning capabilities of large language models (LLMs). However, acquiring human-authored rationales or augmenting rationales from proprietary models is costly and not scalable. In this paper, we study the problem of whether LLMs could self-improve their reasoning capabilities. To this end, we propose Self-Explore, where the LLM is tasked to explore the first wrong step (i.e., the first pit) within the rationale and use such signals as fine-grained rewards for further improvement. On the GSM8K and MATH test set, Self-Explore achieves 11.57% and 2.89% improvement on average across three LLMs compared to supervised fine-tuning (SFT). Our code is available at https://github.com/hbin0701/Self-Explore.
Create account to get full access
Overview
- The paper proposes a novel approach to improve the reasoning capabilities of language models using fine-grained rewards.
- The method, called "Self-Explore to Avoid the Pit," encourages the model to explore the reasoning process and learn from its own mistakes.
- The authors demonstrate the effectiveness of this approach on several reasoning tasks, showing that it can lead to significant performance improvements compared to standard fine-tuning.
Plain English Explanation
The paper describes a new way to train language models to become better at reasoning and solving complex problems. The key idea is to give the model more detailed feedback during training, rather than just rewarding it for getting the final answer right.
Imagine you're teaching a child how to solve math problems. Instead of just saying "correct" or "incorrect" at the end, you might walk them through each step of the solution and point out where they went wrong. This helps the child understand the reasoning process and learn from their mistakes.
The researchers applied a similar approach to training language models. They created a system that closely monitors the model's thought process as it tries to solve a problem, and provides detailed feedback at each step. This encourages the model to explore different approaches, learn from its errors, and develop a deeper understanding of the underlying concepts.
By using these fine-grained rewards, the researchers were able to significantly improve the model's performance on a variety of reasoning tasks, such as [link to "can-small-language-models-help-large-language"] and [link to "learning-planning-based-reasoning-by-trajectories-collection"]. The model became better at breaking down complex problems, considering multiple perspectives, and arriving at more logical and well-justified conclusions.
Technical Explanation
The paper introduces a new training approach called "Self-Explore to Avoid the Pit" (SEAP) that aims to improve the reasoning capabilities of language models. The key innovation is the use of fine-grained rewards that provide detailed feedback on the model's reasoning process, rather than just rewarding the final answer.
Specifically, the SEAP approach involves the following steps:
- The model is presented with a reasoning task, such as [link to "llm-reasoners-new-evaluation-library-analysis-step"] or [link to "can-llms-learn-from-previous-mistakes-investigating"].
- As the model generates its response, the training algorithm closely monitors its thought process, tracking the various steps and decisions it makes.
- At each step, the model receives a reward or penalty based on the quality and logic of its reasoning. This encourages the model to explore different approaches and learn from its mistakes.
- The cumulative reward over the entire reasoning process is used to update the model's parameters, reinforcing the successful reasoning strategies and discouraging the unsuccessful ones.
The authors demonstrate the effectiveness of SEAP on several benchmark tasks, showing that it can lead to significant performance improvements compared to standard fine-tuning approaches. The model becomes better at breaking down complex problems, considering multiple perspectives, and arriving at more logical and well-justified conclusions.
Critical Analysis
The paper presents a promising approach to improving the reasoning capabilities of language models, but there are a few potential limitations and areas for further research:
- The fine-grained rewards used in the SEAP approach require a detailed understanding of the reasoning process, which may not be easy to obtain or generalize to all types of tasks. [link to "improving-language-model-reasoning-self-motivated-learning"]
- The paper does not explore the scalability of the SEAP approach to larger, more complex language models. It would be interesting to see how the technique performs as the model size and task difficulty increase. [link to "can-small-language-models-help-large-language"]
- The authors do not provide a clear explanation of how the fine-grained rewards are designed and how they relate to the underlying reasoning processes. More research is needed to understand the connection between the reward structure and the resulting improvements in reasoning.
Overall, the SEAP approach is a valuable contribution to the field of language model training, and the authors have demonstrated its potential to enhance the reasoning capabilities of these models. However, further research is needed to address the limitations and fully explore the broader implications of this technique.
Conclusion
The paper presents a novel approach called "Self-Explore to Avoid the Pit" (SEAP) that aims to improve the reasoning capabilities of language models by using fine-grained rewards to provide detailed feedback on the model's thought process.
The key innovation of the SEAP approach is its emphasis on encouraging the model to explore different reasoning strategies, learn from its mistakes, and develop a deeper understanding of the underlying concepts. By monitoring the model's step-by-step reasoning and providing rewards or penalties at each stage, the training algorithm is able to significantly improve the model's performance on a variety of reasoning tasks.
The authors' findings suggest that this approach holds great promise for enhancing the reasoning capabilities of language models, which is crucial for their effective deployment in real-world applications that require complex problem-solving and decision-making. While the paper identifies some potential limitations and areas for further research, the SEAP method represents an important step forward in the ongoing effort to build more intelligent and capable language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Improving Language Model Reasoning with Self-motivated Learning
Yunlong Feng, Yang Xu, Libo Qin, Yasheng Wang, Wanxiang Che
0
0
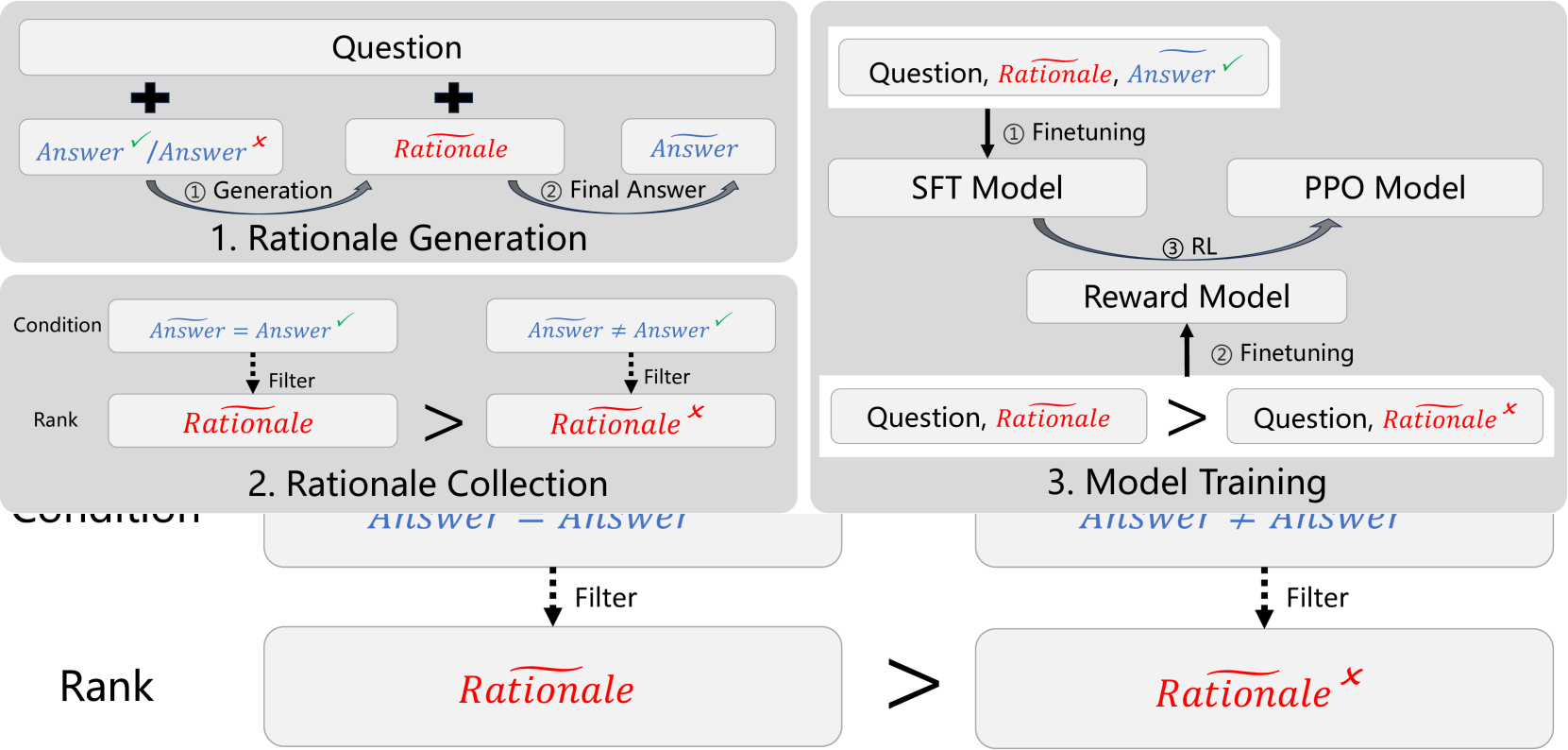
Large-scale high-quality training data is important for improving the performance of models. After trained with data that has rationales (reasoning steps), models gain reasoning capability. However, the dataset with high-quality rationales is relatively scarce due to the high annotation cost. To address this issue, we propose textit{Self-motivated Learning} framework. The framework motivates the model itself to automatically generate rationales on existing datasets. Based on the inherent rank from correctness across multiple rationales, the model learns to generate better rationales, leading to higher reasoning capability. Specifically, we train a reward model with the rank to evaluate the quality of rationales, and improve the performance of reasoning through reinforcement learning. Experiment results of Llama2 7B on multiple reasoning datasets show that our method significantly improves the reasoning ability of models, even outperforming text-davinci-002 in some datasets.
5/1/2024
💬
Optimizing Language Model's Reasoning Abilities with Weak Supervision
Yongqi Tong, Sizhe Wang, Dawei Li, Yifan Wang, Simeng Han, Zi Lin, Chengsong Huang, Jiaxin Huang, Jingbo Shang
0
0
While Large Language Models (LLMs) have demonstrated proficiency in handling complex queries, much of the past work has depended on extensively annotated datasets by human experts. However, this reliance on fully-supervised annotations poses scalability challenges, particularly as models and data requirements grow. To mitigate this, we explore the potential of enhancing LLMs' reasoning abilities with minimal human supervision. In this work, we introduce self-reinforcement, which begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. Then it iteratively improves LLMs by learning from the differences in responses from the SFT and unfinetuned models on unlabeled questions. Our approach provides an efficient approach without relying heavily on extensive human-annotated explanations. However, current reasoning benchmarks typically only include golden-reference answers or rationales. Therefore, we present textsc{PuzzleBen}, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of our dataset is the inclusion of 10,000 unannotated questions, enabling us to explore utilizing fewer supersized data to boost LLMs' inference capabilities. Our experiments underscore the significance of textsc{PuzzleBen}, as well as the effectiveness of our methodology as a promising direction in future endeavors. Our dataset and code will be published soon on texttt{Anonymity Link}.
5/8/2024
Self-Refine Instruction-Tuning for Aligning Reasoning in Language Models
Leonardo Ranaldi, Andr`e Freitas
0
0
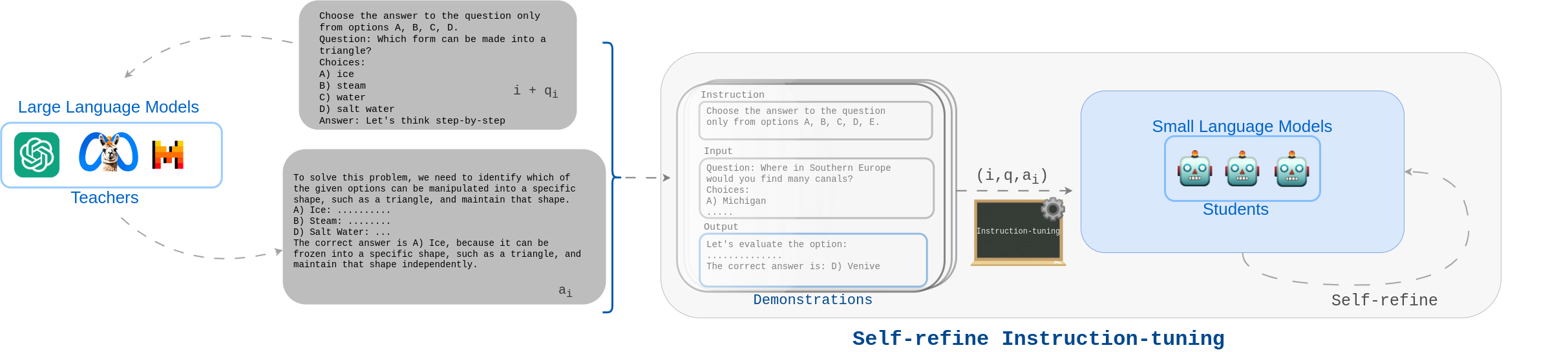
The alignments of reasoning abilities between smaller and larger Language Models are largely conducted via Supervised Fine-Tuning (SFT) using demonstrations generated from robust Large Language Models (LLMs). Although these approaches deliver more performant models, they do not show sufficiently strong generalization ability as the training only relies on the provided demonstrations. In this paper, we propose the Self-refine Instruction-tuning method that elicits Smaller Language Models to self-refine their abilities. Our approach is based on a two-stage process, where reasoning abilities are first transferred between LLMs and Small Language Models (SLMs) via Instruction-tuning on demonstrations provided by LLMs, and then the instructed models Self-refine their abilities through preference optimization strategies. In particular, the second phase operates refinement heuristics based on the Direct Preference Optimization algorithm, where the SLMs are elicited to deliver a series of reasoning paths by automatically sampling the generated responses and providing rewards using ground truths from the LLMs. Results obtained on commonsense and math reasoning tasks show that this approach significantly outperforms Instruction-tuning in both in-domain and out-domain scenarios, aligning the reasoning abilities of Smaller and Larger Language Models.
5/2/2024
🌀
New!ReFT: Reasoning with Reinforced Fine-Tuning
Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, Hang Li
0
0
One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question. To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs on-line reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question and the rewards are naturally derived from the ground-truth answers. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
6/28/2024