Improving Language Model Reasoning with Self-motivated Learning
2404.07017
0
0
Abstract
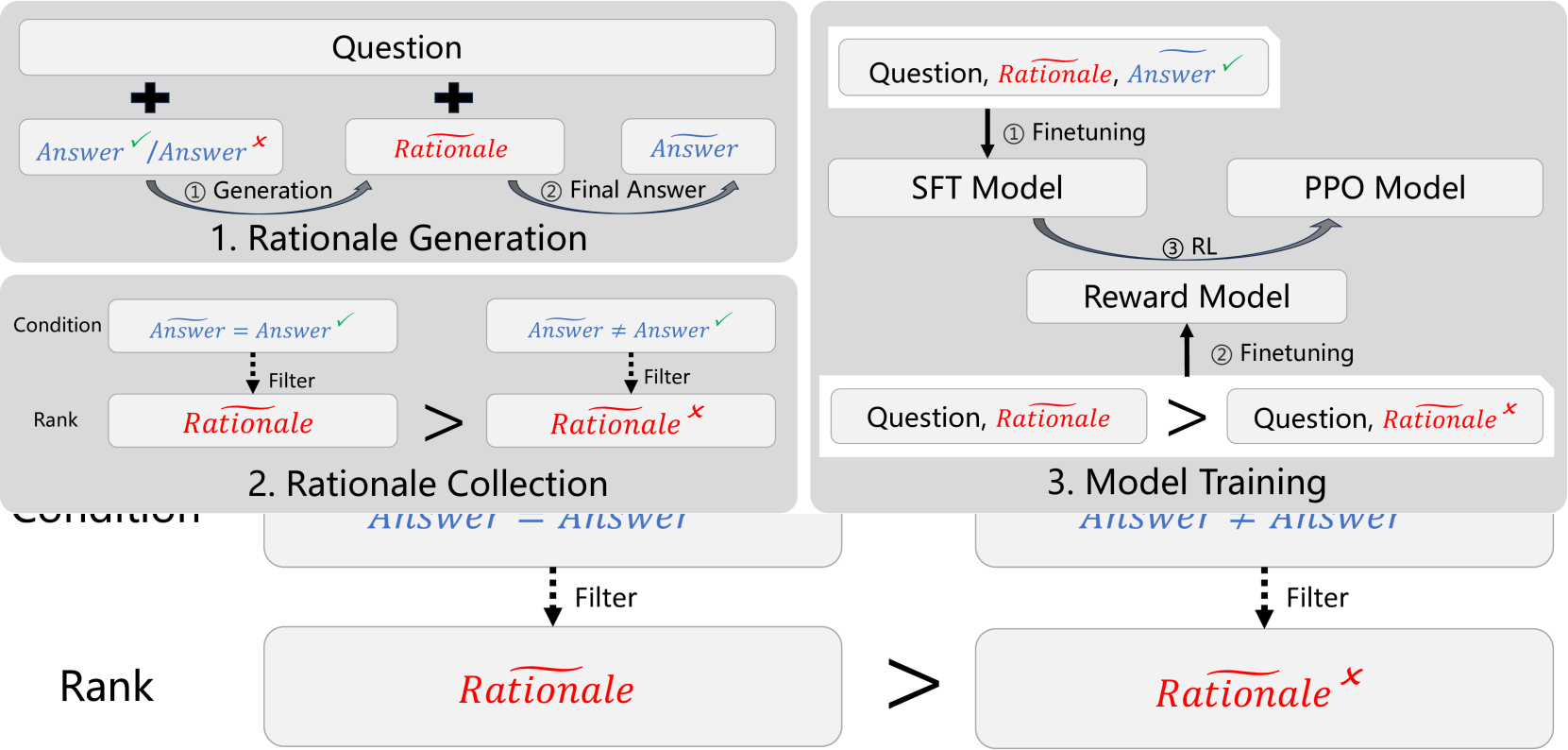
Large-scale high-quality training data is important for improving the performance of models. After trained with data that has rationales (reasoning steps), models gain reasoning capability. However, the dataset with high-quality rationales is relatively scarce due to the high annotation cost. To address this issue, we propose textit{Self-motivated Learning} framework. The framework motivates the model itself to automatically generate rationales on existing datasets. Based on the inherent rank from correctness across multiple rationales, the model learns to generate better rationales, leading to higher reasoning capability. Specifically, we train a reward model with the rank to evaluate the quality of rationales, and improve the performance of reasoning through reinforcement learning. Experiment results of Llama2 7B on multiple reasoning datasets show that our method significantly improves the reasoning ability of models, even outperforming text-davinci-002 in some datasets.
Create account to get full access
Overview
- This paper introduces a novel approach called "self-motivated learning" to improve the reasoning capabilities of language models.
- The key idea is to train the language model to generate its own training data through a self-supervised process, which helps the model learn more effective reasoning strategies.
- The authors demonstrate that this approach leads to significant performance improvements on reasoning-focused benchmarks compared to standard language model training.
Plain English Explanation
The paper describes a new way to train language models, which are AI systems that can understand and generate human language. Traditionally, language models are trained on large datasets of existing text, which helps them learn patterns and rules of language. However, this approach doesn't always lead to strong reasoning abilities.
The researchers in this paper tried a different approach. Instead of just training the language model on existing text, they trained it to generate its own training data through a process called "self-motivated learning." The idea is that by learning to create its own training examples, the language model can discover more effective strategies for reasoning and problem-solving.
For example, if the language model is asked to solve a complex logic puzzle, it might generate its own practice puzzles and try to solve them. This self-generated practice helps the model develop better reasoning skills that it can then apply to new problems.
The researchers found that language models trained with this self-motivated approach performed significantly better on tests that measure reasoning ability, compared to models trained in the traditional way. This suggests that this novel training method could be a promising way to build AI systems with more robust and flexible reasoning capabilities.
Technical Explanation
The core of the "self-motivated learning" approach is a two-stage training process. In the first stage, the language model is trained on a standard dataset of text, just like a traditional language model.
In the second stage, the model is trained to generate its own training data through a self-supervised process. Specifically, the model is given a "task specification" (e.g., a description of a logic puzzle), and it must generate a "task instance" (e.g., a specific puzzle) that satisfies the specification. The model is then trained to solve the self-generated task instance.
By iterating through this generate-and-solve cycle, the language model learns to reason about and solve increasingly complex problems, which in turn helps it develop more robust reasoning capabilities.
The authors evaluate their approach on a variety of reasoning-focused benchmarks, including tasks that test logical, mathematical, and commonsense reasoning. They show that language models trained with self-motivated learning significantly outperform models trained in the traditional way, demonstrating the effectiveness of this novel training paradigm.
Critical Analysis
The authors acknowledge several limitations of their work. First, the self-motivated learning process can be computationally intensive, as the model must generate and solve its own training data. This could make the approach challenging to scale to very large language models.
Additionally, the paper does not explore the transferability of the reasoning skills learned through self-motivated learning. It's unclear whether the improved reasoning abilities would generalize to a wide range of tasks, or if they are more narrowly focused on the specific types of problems used during training.
Another potential concern is the stability and reliability of the self-motivated learning process. If the model generates low-quality or inconsistent training data, this could lead to suboptimal learning and generalization. The authors do not provide a detailed analysis of the characteristics of the self-generated training data.
Despite these limitations, the self-motivated learning approach represents an exciting and promising direction for improving the reasoning capabilities of language models. Further research is needed to address the scalability and generalization challenges, but this work demonstrates the potential of using self-supervised techniques to develop more capable and versatile AI systems.
Conclusion
This paper introduces a novel "self-motivated learning" approach for training language models to reason more effectively. By having the model generate its own training data and learn to solve the problems it creates, the researchers were able to significantly improve the model's performance on a variety of reasoning-focused benchmarks.
While the approach has some limitations in terms of scalability and the transferability of the learned skills, it represents an exciting step forward in the development of language models with stronger reasoning abilities. As AI systems become more integrated into our daily lives, the ability to reason about complex problems in a flexible and robust manner will be increasingly important. The insights from this paper could help pave the way for the next generation of language models that can better understand and interact with the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Self-Explore to Avoid the Pit: Improving the Reasoning Capabilities of Language Models with Fine-grained Rewards
Hyeonbin Hwang, Doyoung Kim, Seungone Kim, Seonghyeon Ye, Minjoon Seo
0
0
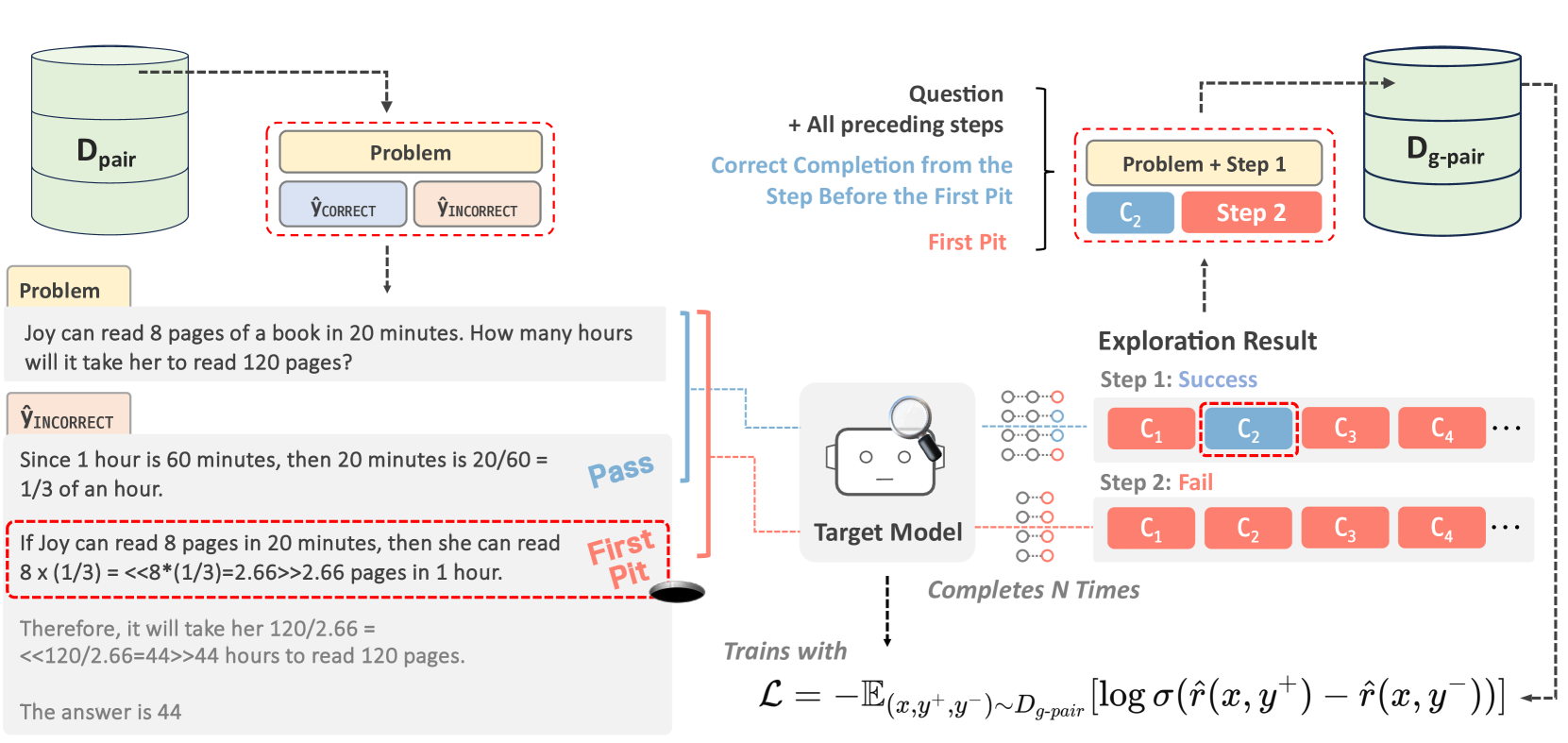
Training on large amounts of rationales (i.e., CoT Fine-tuning) is effective at improving the reasoning capabilities of large language models (LLMs). However, acquiring human-authored rationales or augmenting rationales from proprietary models is costly and not scalable. In this paper, we study the problem of whether LLMs could self-improve their reasoning capabilities. To this end, we propose Self-Explore, where the LLM is tasked to explore the first wrong step (i.e., the first pit) within the rationale and use such signals as fine-grained rewards for further improvement. On the GSM8K and MATH test set, Self-Explore achieves 11.57% and 2.89% improvement on average across three LLMs compared to supervised fine-tuning (SFT). Our code is available at https://github.com/hbin0701/Self-Explore.
5/17/2024
💬
Optimizing Language Model's Reasoning Abilities with Weak Supervision
Yongqi Tong, Sizhe Wang, Dawei Li, Yifan Wang, Simeng Han, Zi Lin, Chengsong Huang, Jiaxin Huang, Jingbo Shang
0
0
While Large Language Models (LLMs) have demonstrated proficiency in handling complex queries, much of the past work has depended on extensively annotated datasets by human experts. However, this reliance on fully-supervised annotations poses scalability challenges, particularly as models and data requirements grow. To mitigate this, we explore the potential of enhancing LLMs' reasoning abilities with minimal human supervision. In this work, we introduce self-reinforcement, which begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. Then it iteratively improves LLMs by learning from the differences in responses from the SFT and unfinetuned models on unlabeled questions. Our approach provides an efficient approach without relying heavily on extensive human-annotated explanations. However, current reasoning benchmarks typically only include golden-reference answers or rationales. Therefore, we present textsc{PuzzleBen}, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of our dataset is the inclusion of 10,000 unannotated questions, enabling us to explore utilizing fewer supersized data to boost LLMs' inference capabilities. Our experiments underscore the significance of textsc{PuzzleBen}, as well as the effectiveness of our methodology as a promising direction in future endeavors. Our dataset and code will be published soon on texttt{Anonymity Link}.
5/8/2024
🏋️
Tailoring Self-Rationalizers with Multi-Reward Distillation
Sahana Ramnath, Brihi Joshi, Skyler Hallinan, Ximing Lu, Liunian Harold Li, Aaron Chan, Jack Hessel, Yejin Choi, Xiang Ren
0
0
Large language models (LMs) are capable of generating free-text rationales to aid question answering. However, prior work 1) suggests that useful self-rationalization is emergent only at significant scales (e.g., 175B parameter GPT-3); and 2) focuses largely on downstream performance, ignoring the semantics of the rationales themselves, e.g., are they faithful, true, and helpful for humans? In this work, we enable small-scale LMs (approx. 200x smaller than GPT-3) to generate rationales that not only improve downstream task performance, but are also more plausible, consistent, and diverse, assessed both by automatic and human evaluation. Our method, MaRio (Multi-rewArd RatIOnalization), is a multi-reward conditioned self-rationalization algorithm that optimizes multiple distinct properties like plausibility, diversity and consistency. Results on five difficult question-answering datasets StrategyQA, QuaRel, OpenBookQA, NumerSense and QASC show that not only does MaRio improve task accuracy, but it also improves the self-rationalization quality of small LMs across the aforementioned axes better than a supervised fine-tuning (SFT) baseline. Extensive human evaluations confirm that MaRio rationales are preferred vs. SFT rationales, as well as qualitative improvements in plausibility and consistency.
5/24/2024
SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales
Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, Jing Gao
0
0
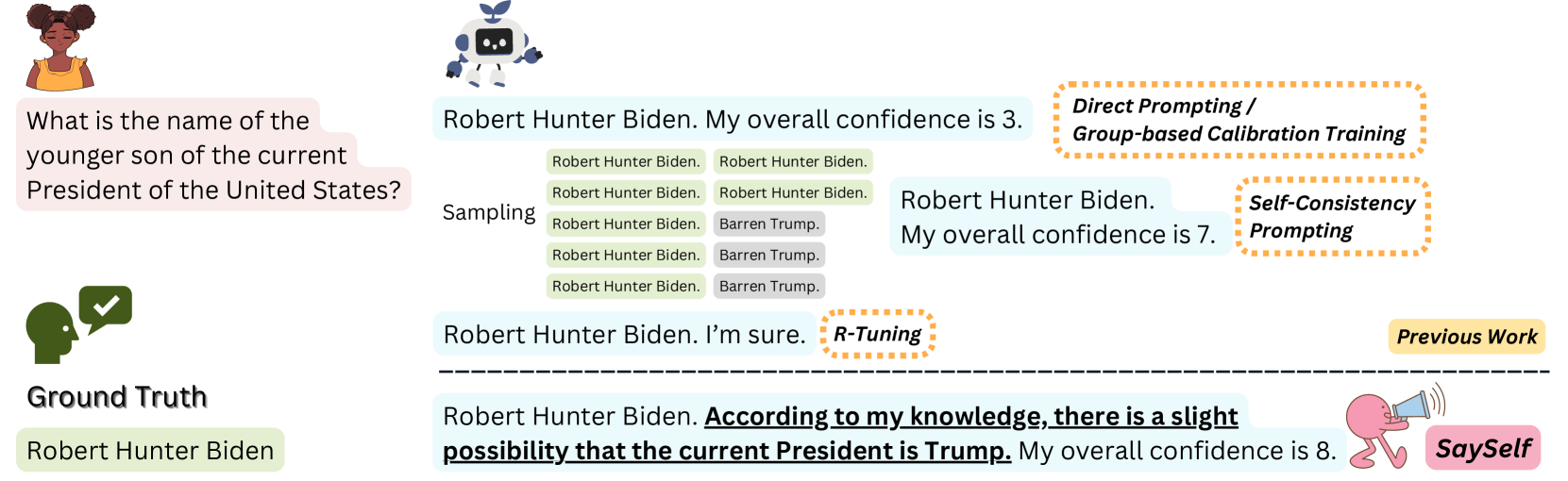
Large language models (LLMs) often generate inaccurate or fabricated information and generally fail to indicate their confidence, which limits their broader applications. Previous work elicits confidence from LLMs by direct or self-consistency prompting, or constructing specific datasets for supervised finetuning. The prompting-based approaches have inferior performance, and the training-based approaches are limited to binary or inaccurate group-level confidence estimates. In this work, we present the advanced SaySelf, a training framework that teaches LLMs to express more accurate fine-grained confidence estimates. In addition, beyond the confidence scores, SaySelf initiates the process of directing LLMs to produce self-reflective rationales that clearly identify gaps in their parametric knowledge and explain their uncertainty. This is achieved by using an LLM to automatically summarize the uncertainties in specific knowledge via natural language. The summarization is based on the analysis of the inconsistency in multiple sampled reasoning chains, and the resulting data is utilized for supervised fine-tuning. Moreover, we utilize reinforcement learning with a meticulously crafted reward function to calibrate the confidence estimates, motivating LLMs to deliver accurate, high-confidence predictions and to penalize overconfidence in erroneous outputs. Experimental results in both in-distribution and out-of-distribution datasets demonstrate the effectiveness of SaySelf in reducing the confidence calibration error and maintaining the task performance. We show that the generated self-reflective rationales are reasonable and can further contribute to the calibration. The code is made public at https://github.com/xu1868/SaySelf.
6/6/2024