Kernel Density Matrices for Probabilistic Deep Learning

0
🤿
Sign in to get full access
Overview
- Introduces a new approach called "kernel density matrices" for representing joint probability distributions of continuous and discrete random variables
- Extends the concept of density matrices from quantum mechanics to a reproducing kernel Hilbert space
- Enables differentiable models for density estimation, inference, and sampling, and integration into deep neural networks
- Demonstrates versatility in various machine learning tasks like image classification, conditional generative modeling, and learning with label proportions
Plain English Explanation
This paper presents a novel technique called "kernel density matrices" that provides a simpler yet effective way to model the joint probability distributions of different types of random variables, including continuous and discrete ones. The idea is inspired by the concept of density matrices in quantum mechanics, which is the most general way to describe the state of a quantum system.
The key innovation is that the authors extended this idea of density matrices to a more general mathematical framework called a reproducing kernel Hilbert space. This allows them to construct differentiable models for tasks like density estimation, inference, and sampling, and seamlessly integrate these models into end-to-end deep neural networks.
By having this versatile representation of probability distributions, the framework enables a differentiable, compositional, and reversible inference procedure that can be applied to a wide range of machine learning problems, such as image classification, generative modeling, and learning with uncertain labels.
The paper demonstrates the broad applicability of this framework through two concrete examples: an image classification model that can be transformed into a conditional generative model, and a model for learning with label proportions that can handle uncertainty in the training data.
Technical Explanation
The core idea of the paper is to extend the concept of density matrices, which are widely used in quantum mechanics to describe the state of a quantum system, to a more general mathematical framework called a reproducing kernel Hilbert space (RKHS). This allows the authors to construct differentiable models for density estimation, inference, and sampling, and seamlessly integrate these models into end-to-end deep neural networks.
By representing probability distributions as kernel density matrices, the framework enables a differentiable, compositional, and reversible inference procedure that can be applied to a wide range of machine learning tasks, including density estimation, discriminative learning, and generative modeling.
The authors demonstrate the versatility of their framework through two examples:
-
An image classification model that can be naturally transformed into a conditional generative model, allowing for tasks like image synthesis conditioned on class labels.
-
A model for learning with label proportions, which can deal with uncertainty in the training labels by modeling the distribution of labels for each sample, rather than relying on precise label assignments.
The paper provides a detailed technical description of the framework, including the mathematical formulation, the optimization procedure, and the integration with deep neural networks. The authors also release an open-source library implementation of the framework, making it accessible for further research and applications.
Critical Analysis
The paper presents a compelling and theoretically grounded approach to probabilistic deep learning, with the potential to have a significant impact on the field. However, a few caveats and areas for further research are worth noting:
-
The authors mention that the framework can handle both continuous and discrete random variables, but the paper focuses primarily on examples with continuous variables. It would be valuable to see more extensive evaluation and demonstration of the framework's capabilities with discrete variables, such as in natural language processing tasks.
-
While the framework is designed to be differentiable and composable, the practical implications of this in terms of scalability and computational efficiency are not fully explored. Larger-scale experiments and comparisons to existing probabilistic deep learning methods would help assess the real-world applicability of the approach.
-
The paper does not delve deeply into the theoretical properties of kernel density matrices, such as their expressiveness, convergence guarantees, or connections to other probabilistic modeling techniques. A more thorough analysis of the theoretical foundations could strengthen the overall contribution of the work.
-
The examples provided, while illustrative, do not fully capture the breadth of potential applications. Exploring the framework's performance on a wider range of machine learning tasks, including those with complex dependencies or structured outputs, could further demonstrate its versatility.
[Despite these limitations, the work presents a promising step towards more flexible and powerful probabilistic deep learning models, with potential applications in areas like explainable AI, generative modeling, and learning from uncertain or incomplete data.](https://aimodels.fyi/papers/arxiv/exponential-concentration-quantum-kernel-methods)
Conclusion
This paper introduces a novel approach called "kernel density matrices" that provides a simpler yet effective way to represent joint probability distributions of continuous and discrete random variables. By extending the concept of density matrices from quantum mechanics to a reproducing kernel Hilbert space, the authors enable the construction of differentiable models for density estimation, inference, and sampling, and their seamless integration into end-to-end deep neural networks.
The versatility of the framework is demonstrated through two examples: an image classification model that can be transformed into a conditional generative model, and a model for learning with label proportions that can handle uncertainty in the training data. While the paper presents some limitations and areas for further research, the work offers a promising step towards more flexible and powerful probabilistic deep learning models, with potential applications in a wide range of machine learning tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Kernel Density Matrices for Probabilistic Deep Learning
Fabio A. Gonz'alez, Ra'ul Ramos-Poll'an, Joseph A. Gallego-Mejia
This paper introduces a novel approach to probabilistic deep learning, kernel density matrices, which provide a simpler yet effective mechanism for representing joint probability distributions of both continuous and discrete random variables. In quantum mechanics, a density matrix is the most general way to describe the state of a quantum system. This work extends the concept of density matrices by allowing them to be defined in a reproducing kernel Hilbert space. This abstraction allows the construction of differentiable models for density estimation, inference, and sampling, and enables their integration into end-to-end deep neural models. In doing so, we provide a versatile representation of marginal and joint probability distributions that allows us to develop a differentiable, compositional, and reversible inference procedure that covers a wide range of machine learning tasks, including density estimation, discriminative learning, and generative modeling. The broad applicability of the framework is illustrated by two examples: an image classification model that can be naturally transformed into a conditional generative model, and a model for learning with label proportions that demonstrates the framework's ability to deal with uncertainty in the training samples. The framework is implemented as a library and is available at: https://github.com/fagonzalezo/kdm.
Read more5/1/2024
🏷️
0
Learning with Density Matrices and Random Features
Fabio A. Gonz'alez, Alejandro Gallego, Santiago Toledo-Cort'es, Vladimir Vargas-Calder'on
A density matrix describes the statistical state of a quantum system. It is a powerful formalism to represent both the quantum and classical uncertainty of quantum systems and to express different statistical operations such as measurement, system combination and expectations as linear algebra operations. This paper explores how density matrices can be used as a building block for machine learning models exploiting their ability to straightforwardly combine linear algebra and probability. One of the main results of the paper is to show that density matrices coupled with random Fourier features could approximate arbitrary probability distributions over $mathbb{R}^n$. Based on this finding the paper builds different models for density estimation, classification and regression. These models are differentiable, so it is possible to integrate them with other differentiable components, such as deep learning architectures and to learn their parameters using gradient-based optimization. In addition, the paper presents optimization-less training strategies based on estimation and model averaging. The models are evaluated in benchmark tasks and the results are reported and discussed.
Read more5/1/2024
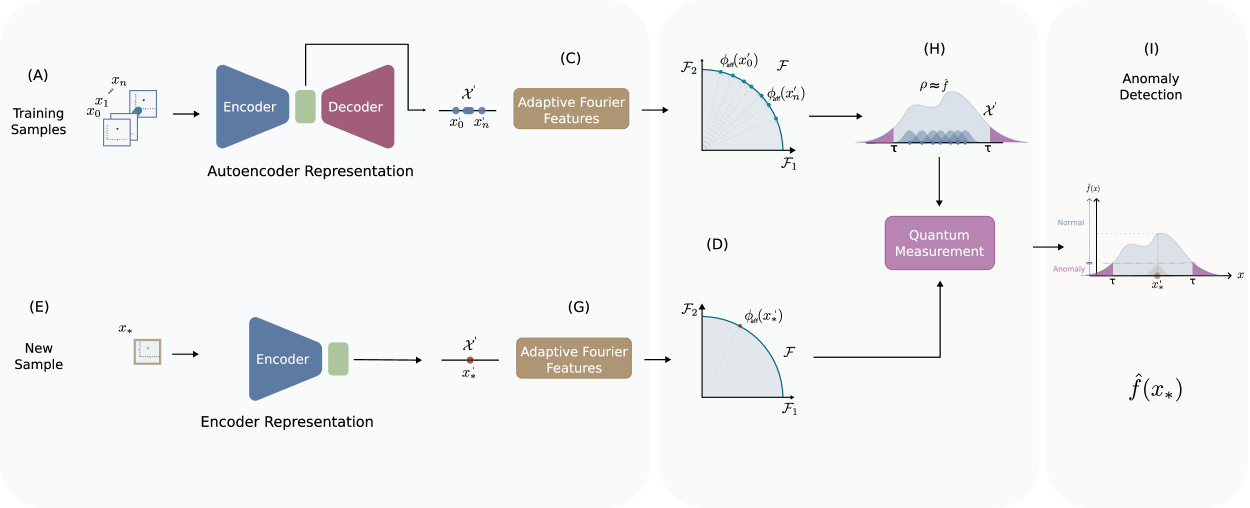
0
Latent Anomaly Detection Through Density Matrices
Joseph Gallego-Mejia, Oscar Bustos-Brinez, Fabio A. Gonz'alez
This paper introduces a novel anomaly detection framework that combines the robust statistical principles of density-estimation-based anomaly detection methods with the representation-learning capabilities of deep learning models. The method originated from this framework is presented in two different versions: a shallow approach employing a density-estimation model based on adaptive Fourier features and density matrices, and a deep approach that integrates an autoencoder to learn a low-dimensional representation of the data. By estimating the density of new samples, both methods are able to find normality scores. The methods can be seamlessly integrated into an end-to-end architecture and optimized using gradient-based optimization techniques. To evaluate their performance, extensive experiments were conducted on various benchmark datasets. The results demonstrate that both versions of the method can achieve comparable or superior performance when compared to other state-of-the-art methods. Notably, the shallow approach performs better on datasets with fewer dimensions, while the autoencoder-based approach shows improved performance on datasets with higher dimensions.
Read more8/15/2024
📊
0
Generative Learning of Continuous Data by Tensor Networks
Alex Meiburg, Jing Chen, Jacob Miller, Raphaelle Tihon, Guillaume Rabusseau, Alejandro Perdomo-Ortiz
Beyond their origin in modeling many-body quantum systems, tensor networks have emerged as a promising class of models for solving machine learning problems, notably in unsupervised generative learning. While possessing many desirable features arising from their quantum-inspired nature, tensor network generative models have previously been largely restricted to binary or categorical data, limiting their utility in real-world modeling problems. We overcome this by introducing a new family of tensor network generative models for continuous data, which are capable of learning from distributions containing continuous random variables. We develop our method in the setting of matrix product states, first deriving a universal expressivity theorem proving the ability of this model family to approximate any reasonably smooth probability density function with arbitrary precision. We then benchmark the performance of this model on several synthetic and real-world datasets, finding that the model learns and generalizes well on distributions of continuous and discrete variables. We develop methods for modeling different data domains, and introduce a trainable compression layer which is found to increase model performance given limited memory or computational resources. Overall, our methods give important theoretical and empirical evidence of the efficacy of quantum-inspired methods for the rapidly growing field of generative learning.
Read more7/26/2024