Tensor Networks for Explainable Machine Learning in Cybersecurity
2401.00867
0
0
Abstract
In this paper we show how tensor networks help in developing explainability of machine learning algorithms. Specifically, we develop an unsupervised clustering algorithm based on Matrix Product States (MPS) and apply it in the context of a real use-case of adversary-generated threat intelligence. Our investigation proves that MPS rival traditional deep learning models such as autoencoders and GANs in terms of performance, while providing much richer model interpretability. Our approach naturally facilitates the extraction of feature-wise probabilities, Von Neumann Entropy, and mutual information, offering a compelling narrative for classification of anomalies and fostering an unprecedented level of transparency and interpretability, something fundamental to understand the rationale behind artificial intelligence decisions.
Create account to get full access
Overview
- This paper explores the use of tensor networks, a type of machine learning model, for explainable cybersecurity applications.
- The researchers propose using Matrix Product States (MPS), a specific type of tensor network, for unsupervised generative modeling of cybersecurity data.
- The goal is to develop machine learning models that can provide interpretable and transparent insights into cybersecurity threats and vulnerabilities.
Plain English Explanation
Tensor networks are a powerful tool for building machine learning models that can be more easily understood by humans. In this paper, the researchers focus on using a particular type of tensor network called a Matrix Product State (MPS) for cybersecurity applications.
The idea behind using MPS for cybersecurity is to create models that can generate realistic cybersecurity data, like network traffic or malware samples, without being trained on real-world data. These generated samples can then be analyzed to uncover patterns and insights that might indicate new types of threats or vulnerabilities.
Importantly, MPS models are much more interpretable than traditional "black box" machine learning models. By examining the structure of the MPS model, researchers and analysts can gain a deeper understanding of the underlying relationships and dependencies in the data. This can lead to more effective Attended Graph Transformers for cybersecurity tasks, such as Explainable Traffic Flow Prediction or Combining Transformers with Natural Language Explanations.
By using interpretable models like MPS, the researchers hope to Advance Ante-hoc Explainable Models and provide cybersecurity experts with better tools for understanding and mitigating complex threats.
Technical Explanation
The researchers propose using Matrix Product States (MPS), a specific type of tensor network, for unsupervised generative modeling of cybersecurity data. MPS models are particularly well-suited for this task because they can capture complex dependencies in high-dimensional data while maintaining interpretability.
The MPS framework involves representing the data as a tensor, which is then decomposed into a product of smaller tensors. This tensor decomposition allows the model to efficiently capture the underlying structure of the data, including any correlations or interactions between different features.
To train the MPS model, the researchers use an unsupervised learning approach, where the model is trained to generate realistic samples of cybersecurity data without any labeled examples. This "Probabilistic Dataset Reconstruction" approach [^1] allows the model to learn the underlying distribution of the data, which can then be used to generate new, synthetic samples for analysis.
The interpretability of the MPS model comes from the fact that the tensor decomposition can be visualized and analyzed to understand the relationships and dependencies captured by the model. This allows cybersecurity experts to gain insights into the data that might not be readily apparent from traditional "black box" machine learning models.
[^1]: Probabilistic Dataset Reconstruction from Interpretable Models
Critical Analysis
The researchers provide a compelling argument for the use of tensor networks, particularly MPS models, in the context of cybersecurity. The ability to generate realistic synthetic data and the inherent interpretability of the MPS framework are significant advantages over traditional machine learning approaches.
However, the paper does not address some potential limitations of the proposed method. For example, the researchers do not discuss the scalability of the MPS approach as the size and complexity of the cybersecurity data increases. Additionally, the paper does not explore the potential biases or limitations that might be introduced by the unsupervised generative modeling approach.
Further research is needed to fully understand the strengths and weaknesses of using MPS models for cybersecurity applications. Comparative studies with other interpretable machine learning techniques, such as Attending Graph Transformers or Combining Transformers with Natural Language Explanations, would be valuable to assess the relative merits of the different approaches.
Conclusion
This paper presents a novel application of tensor networks, specifically Matrix Product States (MPS), for explainable machine learning in cybersecurity. The researchers demonstrate the potential of using MPS for unsupervised generative modeling of cybersecurity data, which can provide valuable insights and Advance Ante-hoc Explainable Models in this critical domain.
The interpretability of the MPS framework is a key advantage, as it allows cybersecurity experts to better understand the underlying patterns and dependencies in the data. This can lead to more effective Explainable Traffic Flow Prediction and other cybersecurity applications.
While further research is needed to address the potential limitations of the approach, this work represents an important step towards developing more transparent and trustworthy machine learning models for cybersecurity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Cons-training tensor networks
Javier Lopez-Piqueres, Jing Chen
0
0
In this study, we introduce a novel family of tensor networks, termed textit{constrained matrix product states} (MPS), designed to incorporate exactly arbitrary discrete linear constraints, including inequalities, into sparse block structures. These tensor networks are particularly tailored for modeling distributions with support strictly over the feasible space, offering benefits such as reducing the search space in optimization problems, alleviating overfitting, improving training efficiency, and decreasing model size. Central to our approach is the concept of a quantum region, an extension of quantum numbers traditionally used in U(1) symmetric tensor networks, adapted to capture any linear constraint, including the unconstrained scenario. We further develop a novel canonical form for these new MPS, which allow for the merging and factorization of tensor blocks according to quantum region fusion rules and permit optimal truncation schemes. Utilizing this canonical form, we apply an unsupervised training strategy to optimize arbitrary objective functions subject to discrete linear constraints. Our method's efficacy is demonstrated by solving the quadratic knapsack problem, achieving superior performance compared to a leading nonlinear integer programming solver. Additionally, we analyze the complexity and scalability of our approach, demonstrating its potential in addressing complex constrained combinatorial optimization problems.
6/7/2024
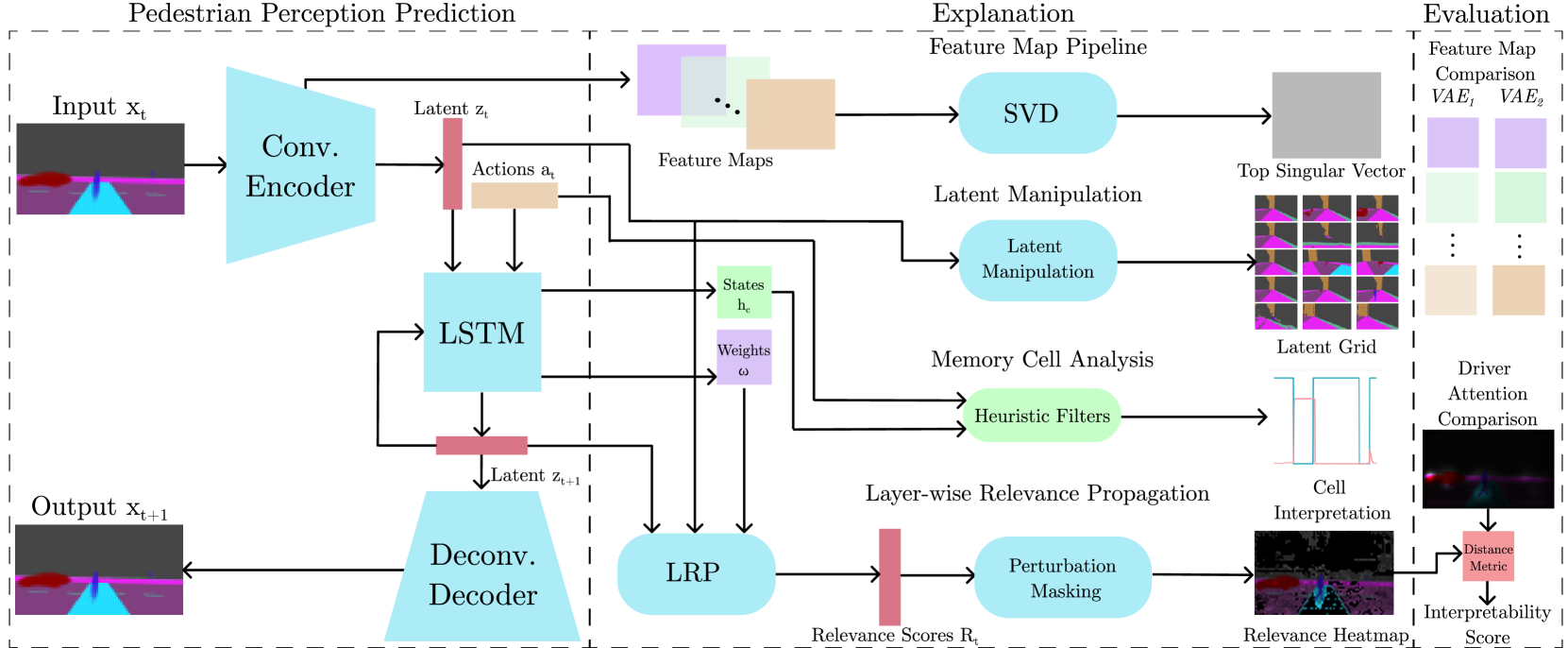
On the Road to Clarity: Exploring Explainable AI for World Models in a Driver Assistance System
Mohamed Roshdi, Julian Petzold, Mostafa Wahby, Hussein Ebrahim, Mladen Berekovic, Heiko Hamann
0
0
In Autonomous Driving (AD) transparency and safety are paramount, as mistakes are costly. However, neural networks used in AD systems are generally considered black boxes. As a countermeasure, we have methods of explainable AI (XAI), such as feature relevance estimation and dimensionality reduction. Coarse graining techniques can also help reduce dimensionality and find interpretable global patterns. A specific coarse graining method is Renormalization Groups from statistical physics. It has previously been applied to Restricted Boltzmann Machines (RBMs) to interpret unsupervised learning. We refine this technique by building a transparent backbone model for convolutional variational autoencoders (VAE) that allows mapping latent values to input features and has performance comparable to trained black box VAEs. Moreover, we propose a custom feature map visualization technique to analyze the internal convolutional layers in the VAE to explain internal causes of poor reconstruction that may lead to dangerous traffic scenarios in AD applications. In a second key contribution, we propose explanation and evaluation techniques for the internal dynamics and feature relevance of prediction networks. We test a long short-term memory (LSTM) network in the computer vision domain to evaluate the predictability and in future applications potentially safety of prediction models. We showcase our methods by analyzing a VAE-LSTM world model that predicts pedestrian perception in an urban traffic situation.
4/29/2024
🤯
New!Unveiling the Unseen: Exploring Whitebox Membership Inference through the Lens of Explainability
Chenxi Li, Abhinav Kumar, Zhen Guo, Jie Hou, Reza Tourani
0
0
The increasing prominence of deep learning applications and reliance on personalized data underscore the urgent need to address privacy vulnerabilities, particularly Membership Inference Attacks (MIAs). Despite numerous MIA studies, significant knowledge gaps persist, particularly regarding the impact of hidden features (in isolation) on attack efficacy and insufficient justification for the root causes of attacks based on raw data features. In this paper, we aim to address these knowledge gaps by first exploring statistical approaches to identify the most informative neurons and quantifying the significance of the hidden activations from the selected neurons on attack accuracy, in isolation and combination. Additionally, we propose an attack-driven explainable framework by integrating the target and attack models to identify the most influential features of raw data that lead to successful membership inference attacks. Our proposed MIA shows an improvement of up to 26% on state-of-the-art MIA.
7/2/2024
🧠
Disentangled Explanations of Neural Network Predictions by Finding Relevant Subspaces
Pattarawat Chormai, Jan Herrmann, Klaus-Robert Muller, Gr'egoire Montavon
0
0
Explainable AI aims to overcome the black-box nature of complex ML models like neural networks by generating explanations for their predictions. Explanations often take the form of a heatmap identifying input features (e.g. pixels) that are relevant to the model's decision. These explanations, however, entangle the potentially multiple factors that enter into the overall complex decision strategy. We propose to disentangle explanations by extracting at some intermediate layer of a neural network, subspaces that capture the multiple and distinct activation patterns (e.g. visual concepts) that are relevant to the prediction. To automatically extract these subspaces, we propose two new analyses, extending principles found in PCA or ICA to explanations. These novel analyses, which we call principal relevant component analysis (PRCA) and disentangled relevant subspace analysis (DRSA), maximize relevance instead of e.g. variance or kurtosis. This allows for a much stronger focus of the analysis on what the ML model actually uses for predicting, ignoring activations or concepts to which the model is invariant. Our approach is general enough to work alongside common attribution techniques such as Shapley Value, Integrated Gradients, or LRP. Our proposed methods show to be practically useful and compare favorably to the state of the art as demonstrated on benchmarks and three use cases.
4/16/2024