Keypoint Aware Masked Image Modelling

0

Sign in to get full access
Overview
- This paper proposes a novel masked image modeling approach called "Keypoint Aware Masked Image Modelling" (KAMIM) that leverages keypoint information to improve the performance of self-supervised learning.
- The key idea is to use keypoint information to guide the masking process and the reconstruction task, leading to better learned representations.
- The paper presents extensive experiments on various vision tasks to demonstrate the effectiveness of KAMIM.
Plain English Explanation
Masked image modeling is a technique used in self-supervised learning, where an AI system is trained to reconstruct parts of an image that have been deliberately hidden or "masked." This helps the system learn useful representations of the data without needing labeled examples.
The Keypoint Aware Masked Image Modelling (KAMIM) approach presented in this paper takes this a step further by incorporating information about key points, or important locations, in the image. The researchers hypothesize that by focusing the masking and reconstruction on these key points, the system can learn even more meaningful representations.
For example, if an image contains a person, the key points might be the location of their eyes, nose, and other facial features. By prioritizing the reconstruction of these areas, the system can better understand the structure and semantics of the image.
The paper demonstrates through extensive experiments that this keypoint-aware approach leads to improved performance on a variety of computer vision tasks, compared to standard masked image modeling techniques. This suggests that incorporating domain-specific knowledge, like the importance of certain image regions, can be a powerful way to enhance self-supervised learning.
Technical Explanation
The KAMIM approach works as follows:
- Keypoint Extraction: The system first identifies the key points in the input image using a pre-trained keypoint detection model.
- Masking Strategy: Instead of randomly masking parts of the image, KAMIM selectively masks regions around the detected keypoints. This ensures that the model focuses on reconstructing the most important parts of the image.
- Reconstruction Task: The model is trained to reconstruct the masked regions, but with a loss function that gives higher weight to the reconstruction of keypoint areas.
The researchers evaluate KAMIM on a range of vision tasks, including image classification, object detection, and instance segmentation. They show that KAMIM consistently outperforms standard masked image modeling approaches, demonstrating the value of incorporating keypoint-aware masking and reconstruction.
Critical Analysis
The paper provides a thorough evaluation of KAMIM, with experiments across multiple datasets and tasks. The results convincingly show the benefits of the keypoint-aware approach compared to baseline methods.
However, the paper does not delve deeply into the limitations or potential issues with KAMIM. For example, it's unclear how the performance of KAMIM would scale to more complex datasets or if the approach is sensitive to the accuracy of the keypoint detection model.
Additionally, the paper does not explore potential trade-offs or practical considerations, such as the computational overhead of the keypoint extraction step or the impact on training time and model size.
It would also be valuable to see more analysis on how KAMIM learns representations differently from standard masked image modeling, and whether the learned representations are more interpretable or transferable to other tasks.
Conclusion
The Keypoint Aware Masked Image Modelling (KAMIM) approach presented in this paper is a promising advancement in self-supervised learning for computer vision. By incorporating keypoint information into the masking and reconstruction process, the system is able to learn more effective representations that lead to improved performance on a variety of downstream tasks.
This work highlights the potential benefits of leveraging domain-specific knowledge to enhance self-supervised learning, and suggests that further research into keypoint-aware and semantically-guided modeling techniques could be a fruitful direction for the field. As AI systems become more capable, incorporating such contextual information may be key to unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Keypoint Aware Masked Image Modelling
Madhava Krishna, A V Subramanyam
SimMIM is a widely used method for pretraining vision transformers using masked image modeling. However, despite its success in fine-tuning performance, it has been shown to perform sub-optimally when used for linear probing. We propose an efficient patch-wise weighting derived from keypoint features which captures the local information and provides better context during SimMIM's reconstruction phase. Our method, KAMIM, improves the top-1 linear probing accuracy from 16.12% to 33.97%, and finetuning accuracy from 76.78% to 77.3% when tested on the ImageNet-1K dataset with a ViT-B when trained for the same number of epochs. We conduct extensive testing on different datasets, keypoint extractors, and model architectures and observe that patch-wise weighting augments linear probing performance for larger pretraining datasets. We also analyze the learned representations of a ViT-B trained using KAMIM and observe that they behave similar to contrastive learning with regard to its behavior, with longer attention distances and homogenous self-attention across layers. Our code is publicly available at https://github.com/madhava20217/KAMIM.
Read more7/22/2024

0
Symmetric masking strategy enhances the performance of Masked Image Modeling
Khanh-Binh Nguyen, Chae Jung Park
Masked Image Modeling (MIM) is a technique in self-supervised learning that focuses on acquiring detailed visual representations from unlabeled images by estimating the missing pixels in randomly masked sections. It has proven to be a powerful tool for the preliminary training of Vision Transformers (ViTs), yielding impressive results across various tasks. Nevertheless, most MIM methods heavily depend on the random masking strategy to formulate the pretext task. This strategy necessitates numerous trials to ascertain the optimal dropping ratio, which can be resource-intensive, requiring the model to be pre-trained for anywhere between 800 to 1600 epochs. Furthermore, this approach may not be suitable for all datasets. In this work, we propose a new masking strategy that effectively helps the model capture global and local features. Based on this masking strategy, SymMIM, our proposed training pipeline for MIM is introduced. SymMIM achieves a new SOTA accuracy of 85.9% on ImageNet using ViT-Large and surpasses previous SOTA across downstream tasks such as image classification, semantic segmentation, object detection, instance segmentation tasks, and so on.
Read more8/26/2024
👀
0
Centroid-centered Modeling for Efficient Vision Transformer Pre-training
Xin Yan, Zuchao Li, Lefei Zhang
Masked Image Modeling (MIM) is a new self-supervised vision pre-training paradigm using a Vision Transformer (ViT). Previous works can be pixel-based or token-based, using original pixels or discrete visual tokens from parametric tokenizer models, respectively. Our proposed centroid-based approach, CCViT, leverages k-means clustering to obtain centroids for image modeling without supervised training of the tokenizer model, which only takes seconds to create. This non-parametric centroid tokenizer only takes seconds to create and is faster for token inference. The centroids can represent both patch pixels and index tokens with the property of local invariance. Specifically, we adopt patch masking and centroid replacing strategies to construct corrupted inputs, and two stacked encoder blocks to predict corrupted patch tokens and reconstruct original patch pixels. Experiments show that our CCViT achieves 84.4% top-1 accuracy on ImageNet-1K classification with ViT-B and 86.0% with ViT-L. We also transfer our pre-trained model to other downstream tasks. Our approach achieves competitive results with recent baselines without external supervision and distillation training from other models.
Read more8/2/2024
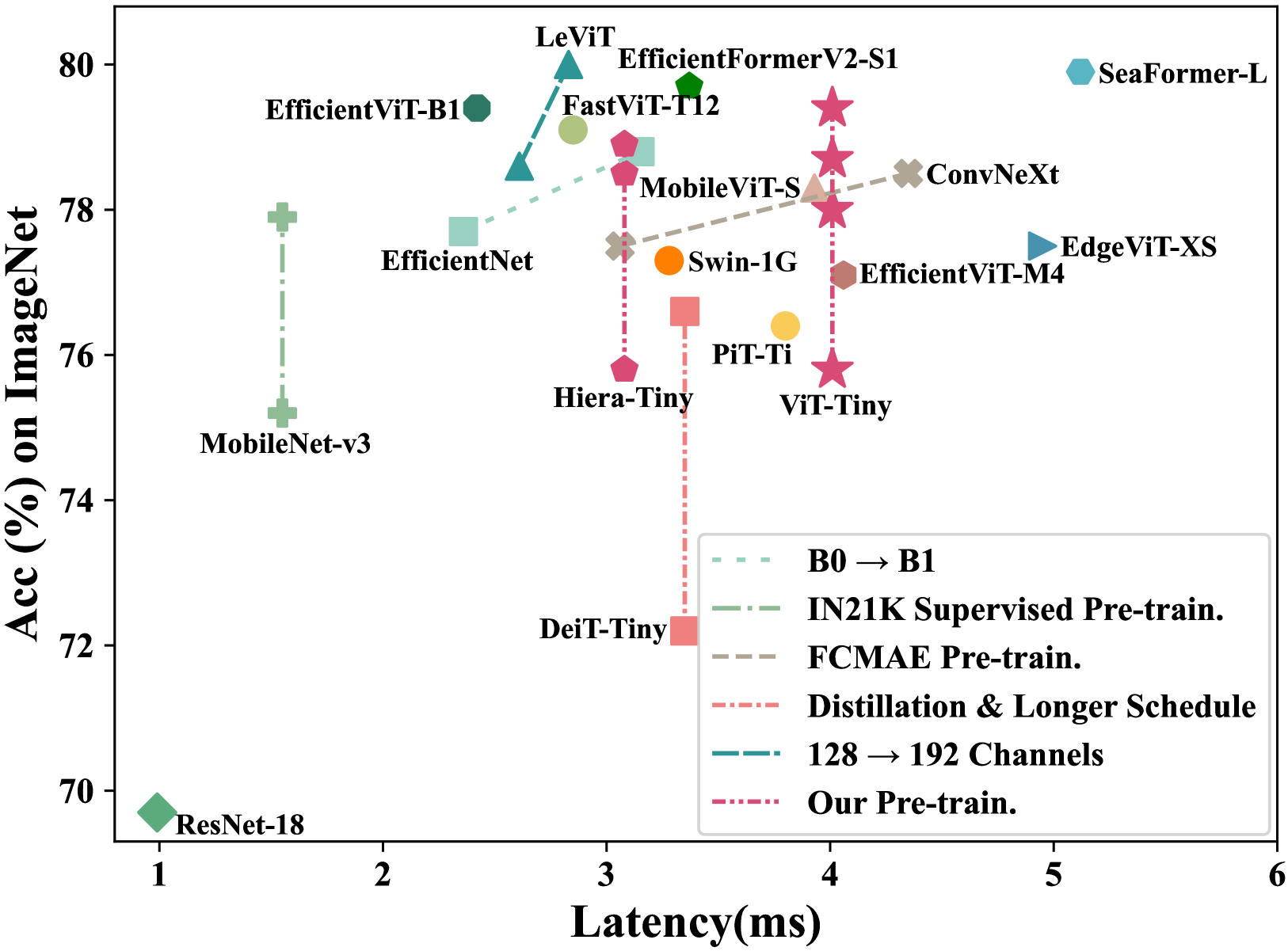
0
Observation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Jin Gao, Shubo Lin, Shaoru Wang, Yutong Kou, Zeming Li, Liang Li, Congxuan Zhang, Xiaoqin Zhang, Yizheng Wang, Weiming Hu
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the textit{extremely simple} lightweight ViTs' fine-tuning performance can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology. We use an observation-analysis-solution flow for our study. We first systematically observe different behaviors among the evaluated pre-training methods with respect to the downstream fine-tuning data scales. Furthermore, we analyze the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory transfer performance on data-insufficient downstream tasks. This finding is naturally a guide to designing our distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments have demonstrated the effectiveness of our approach. Our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design ($5.7M$/$6.5M$) can achieve $79.4%$/$78.9%$ top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K segmentation task ($42.8%$ mIoU) and LaSOT tracking task ($66.1%$ AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
Read more5/28/2024