Centroid-centered Modeling for Efficient Vision Transformer Pre-training

0
👀
Sign in to get full access
Overview
- Masked Image Modeling (MIM) is a new self-supervised vision pre-training approach using Vision Transformers (ViT)
- Previous methods use either pixel-based or token-based modeling
- The proposed CCViT takes a centroid-based approach, using k-means clustering to obtain centroids for image modeling without supervised tokenizer training
- The non-parametric centroid tokenizer is fast to create and perform token inference
Plain English Explanation
Masked Image Modeling (MIM) is a new way of pre-training computer vision models using Vision Transformers (ViT). Previous methods have either worked directly with the original pixel values or used discrete visual tokens from a separate tokenizer model.
The CCViT approach proposed in this paper takes a different approach. It uses k-means clustering to identify centroids, or average points, that can represent different parts of the image. This centroid-based tokenization can be done quickly without needing to train a separate tokenizer model.
The model is then trained to predict these centroid tokens when parts of the image are masked out, and to reconstruct the original pixel values. This allows the model to learn a rich representation of the image content in a self-supervised way, without needing labeled data.
The key advantages of this approach are that the tokenization is fast and simple, and the resulting model achieves competitive performance on image classification and other computer vision tasks compared to more complex methods.
Technical Explanation
The CCViT model uses a k-means clustering algorithm to obtain a set of centroids, or average points, that can represent different visual elements in the image. This non-parametric centroid tokenizer can be created quickly, in contrast to training a separate tokenizer model.
During training, the model uses a patch masking strategy, where random patches of the input image are hidden. The model is then trained to predict the centroid tokens corresponding to the masked patches, as well as reconstruct the original pixel values in those patches.
The model architecture consists of two stacked encoder blocks. The first block takes the masked input and predicts the centroid tokens, while the second block uses those predicted tokens to reconstruct the original pixel values.
Experiments show that this CCViT approach achieves competitive performance on the ImageNet-1K image classification benchmark, reaching 84.4% top-1 accuracy with the ViT-B model and 86.0% with the larger ViT-L model. The pre-trained model also transfers well to other downstream computer vision tasks.
Critical Analysis
The CCViT approach provides a simple and efficient alternative to previous masked image modeling methods. By using a non-parametric centroid tokenizer, it avoids the complexity and computational cost of training a separate tokenizer model.
However, the paper does not provide a detailed analysis of the properties and limitations of the centroid-based tokenization. It would be helpful to understand how the chosen number of centroids affects the representational power and performance of the model, and how robust the centroids are to variations in the input data.
Additionally, the paper focuses primarily on evaluating the model's performance on classification tasks. It would be interesting to see how the CCViT model performs on other computer vision tasks, such as object detection or segmentation, to better understand its broader applicability.
Conclusion
The Masked Image Modeling (MIM) approach with the CCViT model provides a novel and efficient way to pre-train computer vision models using self-supervised learning. By leveraging a fast, non-parametric centroid tokenizer, the model can learn rich representations of image content without the need for expensive labeled data or complex tokenizer training.
The competitive performance of the CCViT model on image classification and other tasks suggests that this approach could be a valuable tool for developing powerful computer vision models in a more scalable and cost-effective manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Centroid-centered Modeling for Efficient Vision Transformer Pre-training
Xin Yan, Zuchao Li, Lefei Zhang
Masked Image Modeling (MIM) is a new self-supervised vision pre-training paradigm using a Vision Transformer (ViT). Previous works can be pixel-based or token-based, using original pixels or discrete visual tokens from parametric tokenizer models, respectively. Our proposed centroid-based approach, CCViT, leverages k-means clustering to obtain centroids for image modeling without supervised training of the tokenizer model, which only takes seconds to create. This non-parametric centroid tokenizer only takes seconds to create and is faster for token inference. The centroids can represent both patch pixels and index tokens with the property of local invariance. Specifically, we adopt patch masking and centroid replacing strategies to construct corrupted inputs, and two stacked encoder blocks to predict corrupted patch tokens and reconstruct original patch pixels. Experiments show that our CCViT achieves 84.4% top-1 accuracy on ImageNet-1K classification with ViT-B and 86.0% with ViT-L. We also transfer our pre-trained model to other downstream tasks. Our approach achieves competitive results with recent baselines without external supervision and distillation training from other models.
Read more8/2/2024
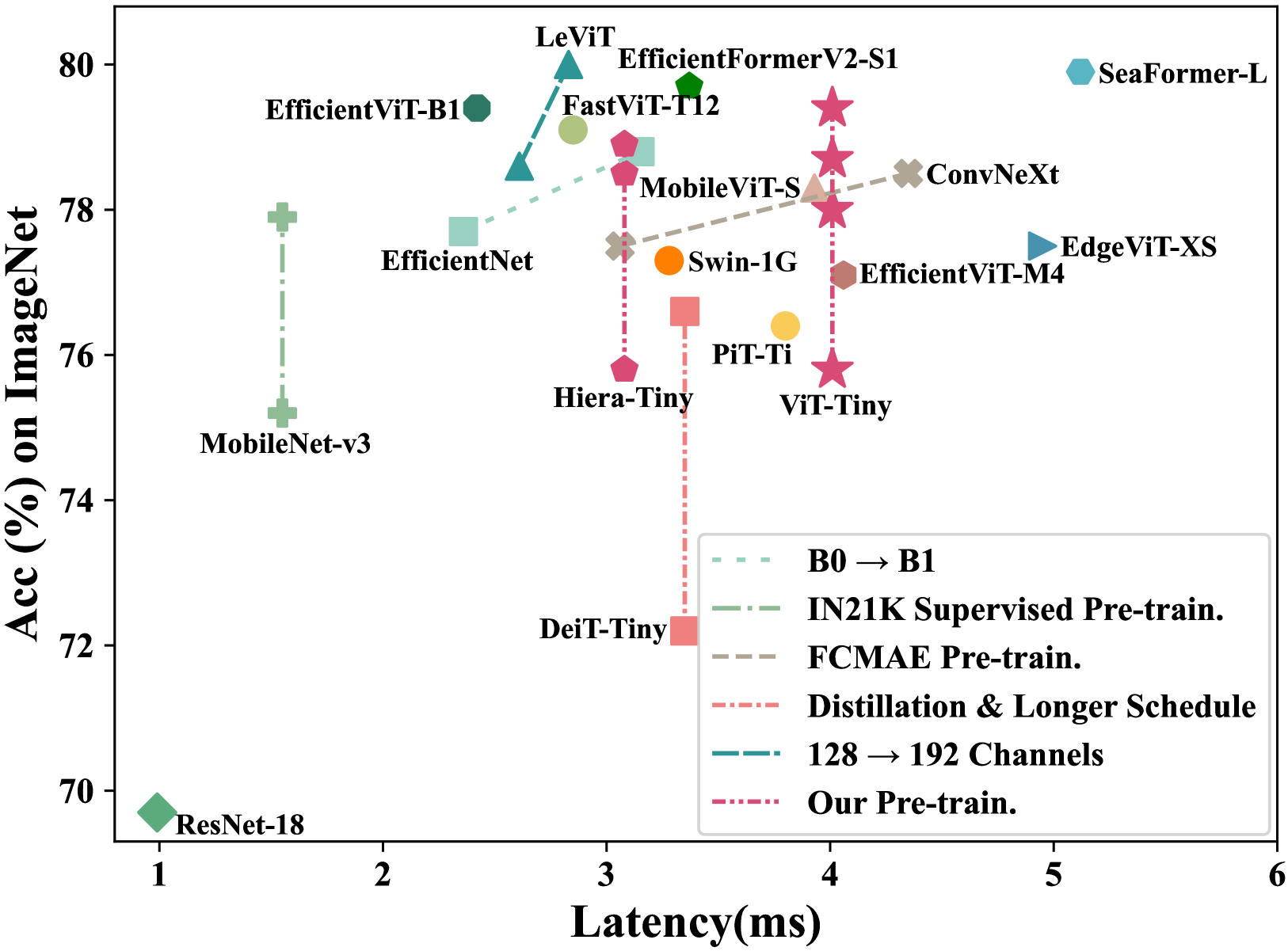
0
Observation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Jin Gao, Shubo Lin, Shaoru Wang, Yutong Kou, Zeming Li, Liang Li, Congxuan Zhang, Xiaoqin Zhang, Yizheng Wang, Weiming Hu
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the textit{extremely simple} lightweight ViTs' fine-tuning performance can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology. We use an observation-analysis-solution flow for our study. We first systematically observe different behaviors among the evaluated pre-training methods with respect to the downstream fine-tuning data scales. Furthermore, we analyze the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory transfer performance on data-insufficient downstream tasks. This finding is naturally a guide to designing our distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments have demonstrated the effectiveness of our approach. Our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design ($5.7M$/$6.5M$) can achieve $79.4%$/$78.9%$ top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K segmentation task ($42.8%$ mIoU) and LaSOT tracking task ($66.1%$ AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
Read more5/28/2024

0
Symmetric masking strategy enhances the performance of Masked Image Modeling
Khanh-Binh Nguyen, Chae Jung Park
Masked Image Modeling (MIM) is a technique in self-supervised learning that focuses on acquiring detailed visual representations from unlabeled images by estimating the missing pixels in randomly masked sections. It has proven to be a powerful tool for the preliminary training of Vision Transformers (ViTs), yielding impressive results across various tasks. Nevertheless, most MIM methods heavily depend on the random masking strategy to formulate the pretext task. This strategy necessitates numerous trials to ascertain the optimal dropping ratio, which can be resource-intensive, requiring the model to be pre-trained for anywhere between 800 to 1600 epochs. Furthermore, this approach may not be suitable for all datasets. In this work, we propose a new masking strategy that effectively helps the model capture global and local features. Based on this masking strategy, SymMIM, our proposed training pipeline for MIM is introduced. SymMIM achieves a new SOTA accuracy of 85.9% on ImageNet using ViT-Large and surpasses previous SOTA across downstream tasks such as image classification, semantic segmentation, object detection, instance segmentation tasks, and so on.
Read more8/26/2024

0
MIMIR: Masked Image Modeling for Mutual Information-based Adversarial Robustness
Xiaoyun Xu, Shujian Yu, Zhuoran Liu, Stjepan Picek
Vision Transformers (ViTs) achieve excellent performance in various tasks, but they are also vulnerable to adversarial attacks. Building robust ViTs is highly dependent on dedicated Adversarial Training (AT) strategies. However, current ViTs' adversarial training only employs well-established training approaches from convolutional neural network (CNN) training, where pre-training provides the basis for AT fine-tuning with the additional help of tailored data augmentations. In this paper, we take a closer look at the adversarial robustness of ViTs by providing a novel theoretical Mutual Information (MI) analysis in its autoencoder-based self-supervised pre-training. Specifically, we show that MI between the adversarial example and its latent representation in ViT-based autoencoders should be constrained by utilizing the MI bounds. Based on this finding, we propose a masked autoencoder-based pre-training method, MIMIR, that employs an MI penalty to facilitate the adversarial training of ViTs. Extensive experiments show that MIMIR outperforms state-of-the-art adversarially trained ViTs on benchmark datasets with higher natural and robust accuracy, indicating that ViTs can substantially benefit from exploiting MI. In addition, we consider two adaptive attacks by assuming that the adversary is aware of the MIMIR design, which further verifies the provided robustness.
Read more8/19/2024