Knowledge Distillation via Query Selection for Detection Transformer

0
🔎
Sign in to get full access
Overview
- This article does not have any content and is just a blank HTML template.
Plain English Explanation
There is no text or content provided in this document, so there is nothing to summarize in plain English.
Technical Explanation
Since there is no technical content in the provided document, there is nothing to explain from a technical perspective.
Critical Analysis
Without any research paper or technical content to analyze, there are no caveats, limitations, or areas for further research that can be discussed. Similarly, there are no aspects of the research that can be challenged or questioned.
Conclusion
Since this document does not contain any information or research to summarize, there are no main takeaways or potential implications that can be provided in a conclusion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Knowledge Distillation via Query Selection for Detection Transformer
Yi Liu, Luting Wang, Zongheng Tang, Yue Liao, Yifan Sun, Lijun Zhang, Si Liu
Transformers have revolutionized the object detection landscape by introducing DETRs, acclaimed for their simplicity and efficacy. Despite their advantages, the substantial size of these models poses significant challenges for practical deployment, particularly in resource-constrained environments. This paper addresses the challenge of compressing DETR by leveraging knowledge distillation, a technique that holds promise for maintaining model performance while reducing size. A critical aspect of DETRs' performance is their reliance on queries to interpret object representations accurately. Traditional distillation methods often focus exclusively on positive queries, identified through bipartite matching, neglecting the rich information present in hard-negative queries. Our visual analysis indicates that hard-negative queries, focusing on foreground elements, are crucial for enhancing distillation outcomes. To this end, we introduce a novel Group Query Selection strategy, which diverges from traditional query selection in DETR distillation by segmenting queries based on their Generalized Intersection over Union (GIoU) with ground truth objects, thereby uncovering valuable hard-negative queries for distillation. Furthermore, we present the Knowledge Distillation via Query Selection for DETR (QSKD) framework, which incorporates Attention-Guided Feature Distillation (AGFD) and Local Alignment Prediction Distillation (LAPD). These components optimize the distillation process by focusing on the most informative aspects of the teacher model's intermediate features and output. Our comprehensive experimental evaluation of the MS-COCO dataset demonstrates the effectiveness of our approach, significantly improving average precision (AP) across various DETR architectures without incurring substantial computational costs. Specifically, the AP of Conditional DETR ResNet-18 increased from 35.8 to 39.9.
Read more9/11/2024

0
Teaching with Uncertainty: Unleashing the Potential of Knowledge Distillation in Object Detection
Junfei Yi, Jianxu Mao, Tengfei Liu, Mingjie Li, Hanyu Gu, Hui Zhang, Xiaojun Chang, Yaonan Wang
Knowledge distillation (KD) is a widely adopted and effective method for compressing models in object detection tasks. Particularly, feature-based distillation methods have shown remarkable performance. Existing approaches often ignore the uncertainty in the teacher model's knowledge, which stems from data noise and imperfect training. This limits the student model's ability to learn latent knowledge, as it may overly rely on the teacher's imperfect guidance. In this paper, we propose a novel feature-based distillation paradigm with knowledge uncertainty for object detection, termed Uncertainty Estimation-Discriminative Knowledge Extraction-Knowledge Transfer (UET), which can seamlessly integrate with existing distillation methods. By leveraging the Monte Carlo dropout technique, we introduce knowledge uncertainty into the training process of the student model, facilitating deeper exploration of latent knowledge. Our method performs effectively during the KD process without requiring intricate structures or extensive computational resources. Extensive experiments validate the effectiveness of our proposed approach across various distillation strategies, detectors, and backbone architectures. Specifically, following our proposed paradigm, the existing FGD method achieves state-of-the-art (SoTA) performance, with ResNet50-based GFL achieving 44.1% mAP on the COCO dataset, surpassing the baselines by 3.9%.
Read more6/12/2024
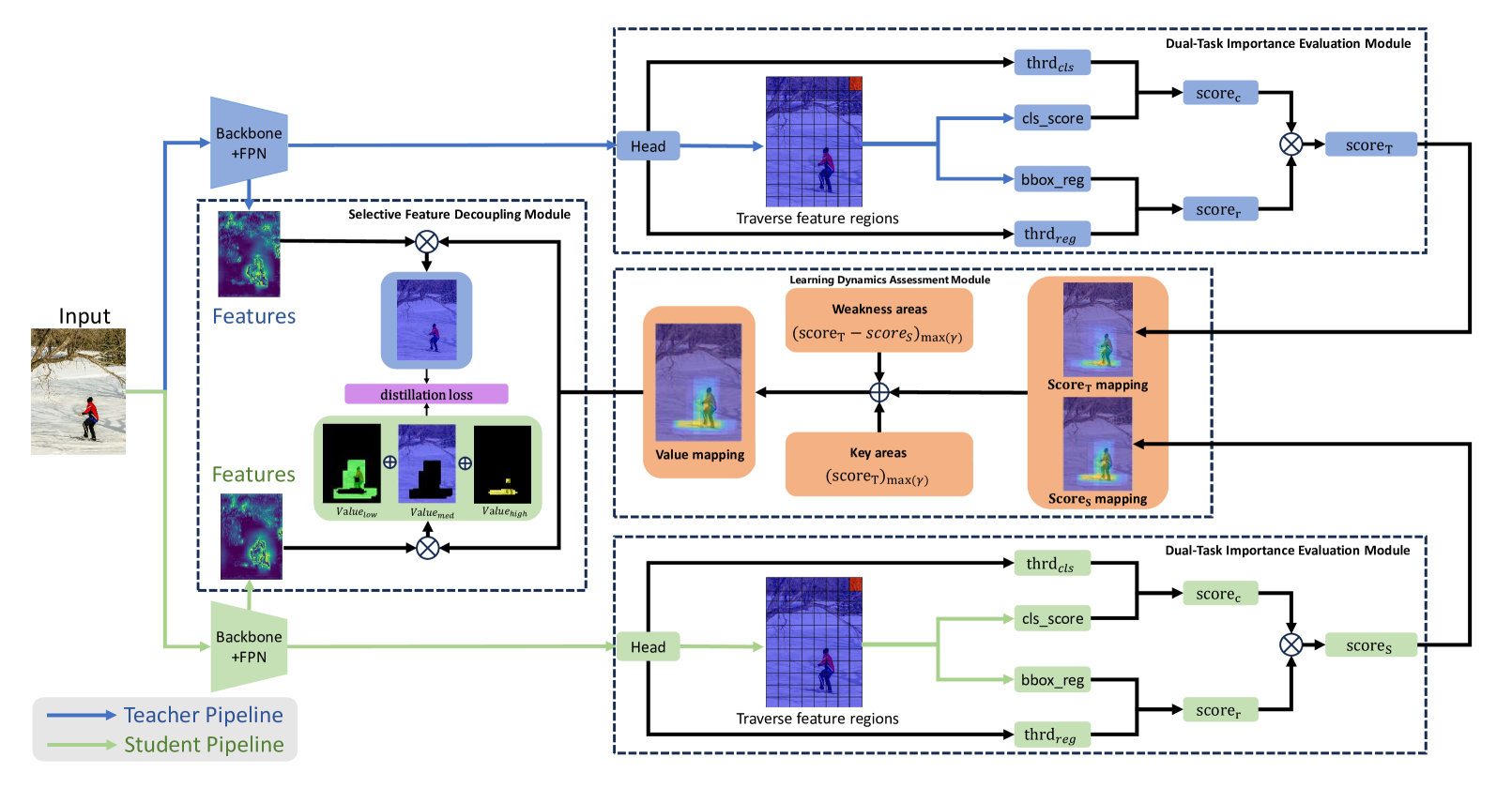
0
Task Integration Distillation for Object Detectors
Hai Su, ZhenWen Jian, Songsen Yu
Knowledge distillation is a widely adopted technique for model lightening. However, the performance of most knowledge distillation methods in the domain of object detection is not satisfactory. Typically, knowledge distillation approaches consider only the classification task among the two sub-tasks of an object detector, largely overlooking the regression task. This oversight leads to a partial understanding of the object detector's comprehensive task, resulting in skewed estimations and potentially adverse effects. Therefore, we propose a knowledge distillation method that addresses both the classification and regression tasks, incorporating a task significance strategy. By evaluating the importance of features based on the output of the detector's two sub-tasks, our approach ensures a balanced consideration of both classification and regression tasks in object detection. Drawing inspiration from real-world teaching processes and the definition of learning condition, we introduce a method that focuses on both key and weak areas. By assessing the value of features for knowledge distillation based on their importance differences, we accurately capture the current model's learning situation. This method effectively prevents the issue of biased predictions about the model's learning reality caused by an incomplete utilization of the detector's outputs.
Read more4/3/2024

0
Domain-invariant Progressive Knowledge Distillation for UAV-based Object Detection
Liang Yao, Fan Liu, Chuanyi Zhang, Zhiquan Ou, Ting Wu
Knowledge distillation (KD) is an effective method for compressing models in object detection tasks. Due to limited computational capability, UAV-based object detection (UAV-OD) widely adopt the KD technique to obtain lightweight detectors. Existing methods often overlook the significant differences in feature space caused by the large gap in scale between the teacher and student models. This limitation hampers the efficiency of knowledge transfer during the distillation process. Furthermore, the complex backgrounds in UAV images make it challenging for the student model to efficiently learn the object features. In this paper, we propose a novel knowledge distillation framework for UAV-OD. Specifically, a progressive distillation approach is designed to alleviate the feature gap between teacher and student models. Then a new feature alignment method is provided to extract object-related features for enhancing student model's knowledge reception efficiency. Finally, extensive experiments are conducted to validate the effectiveness of our proposed approach. The results demonstrate that our proposed method achieves state-of-the-art (SoTA) performance in two UAV-OD datasets.
Read more8/22/2024