Teaching with Uncertainty: Unleashing the Potential of Knowledge Distillation in Object Detection
2406.06999
0
0

Abstract
Knowledge distillation (KD) is a widely adopted and effective method for compressing models in object detection tasks. Particularly, feature-based distillation methods have shown remarkable performance. Existing approaches often ignore the uncertainty in the teacher model's knowledge, which stems from data noise and imperfect training. This limits the student model's ability to learn latent knowledge, as it may overly rely on the teacher's imperfect guidance. In this paper, we propose a novel feature-based distillation paradigm with knowledge uncertainty for object detection, termed Uncertainty Estimation-Discriminative Knowledge Extraction-Knowledge Transfer (UET), which can seamlessly integrate with existing distillation methods. By leveraging the Monte Carlo dropout technique, we introduce knowledge uncertainty into the training process of the student model, facilitating deeper exploration of latent knowledge. Our method performs effectively during the KD process without requiring intricate structures or extensive computational resources. Extensive experiments validate the effectiveness of our proposed approach across various distillation strategies, detectors, and backbone architectures. Specifically, following our proposed paradigm, the existing FGD method achieves state-of-the-art (SoTA) performance, with ResNet50-based GFL achieving 44.1% mAP on the COCO dataset, surpassing the baselines by 3.9%.
Create account to get full access
Related works
Knowledge Distillation in Object Detection
Knowledge distillation is a popular technique in machine learning where a smaller, more efficient model (the "student") is trained to mimic the behavior of a larger, more complex model (the "teacher"). This approach has been applied to object detection tasks, where the student model learns to make accurate object predictions by distilling knowledge from a more accurate teacher model.
Several research papers have explored different ways to apply knowledge distillation to object detection. For example, CrossKD: Cross-Head Knowledge Distillation for Object Detection proposes a method for distilling knowledge across different detection heads within the same model. Task Integration Distillation for Object Detectors investigates combining knowledge distillation with multi-task learning to improve object detection performance.
Robust Knowledge Distillation
Researchers have also explored techniques to make knowledge distillation more robust and effective. Robust Feature Knowledge Distillation for Enhanced Performance of Lightweight Object Detectors focuses on distilling robust feature representations from a teacher model to improve the performance of a smaller student model. Robust Knowledge Distillation Based on Feature Variance against Adversarial Attacks proposes a method to make knowledge distillation more resilient to adversarial attacks.
Label Revision for Knowledge Distillation
Another area of research is improving knowledge distillation by revising the training labels used for the student model. Improving Knowledge Distillation via Label Revision and Data Augmentation explores techniques for revising the training labels to better match the teacher model's predictions, leading to more effective knowledge transfer.
These related works demonstrate the continued interest and progress in applying knowledge distillation to object detection tasks, with researchers exploring various strategies to improve the effectiveness and robustness of this technique.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CrossKD: Cross-Head Knowledge Distillation for Object Detection
Jiabao Wang, Yuming Chen, Zhaohui Zheng, Xiang Li, Ming-Ming Cheng, Qibin Hou
0
0
Knowledge Distillation (KD) has been validated as an effective model compression technique for learning compact object detectors. Existing state-of-the-art KD methods for object detection are mostly based on feature imitation. In this paper, we present a general and effective prediction mimicking distillation scheme, called CrossKD, which delivers the intermediate features of the student's detection head to the teacher's detection head. The resulting cross-head predictions are then forced to mimic the teacher's predictions. This manner relieves the student's head from receiving contradictory supervision signals from the annotations and the teacher's predictions, greatly improving the student's detection performance. Moreover, as mimicking the teacher's predictions is the target of KD, CrossKD offers more task-oriented information in contrast with feature imitation. On MS COCO, with only prediction mimicking losses applied, our CrossKD boosts the average precision of GFL ResNet-50 with 1x training schedule from 40.2 to 43.7, outperforming all existing KD methods. In addition, our method also works well when distilling detectors with heterogeneous backbones. Code is available at https://github.com/jbwang1997/CrossKD.
4/16/2024
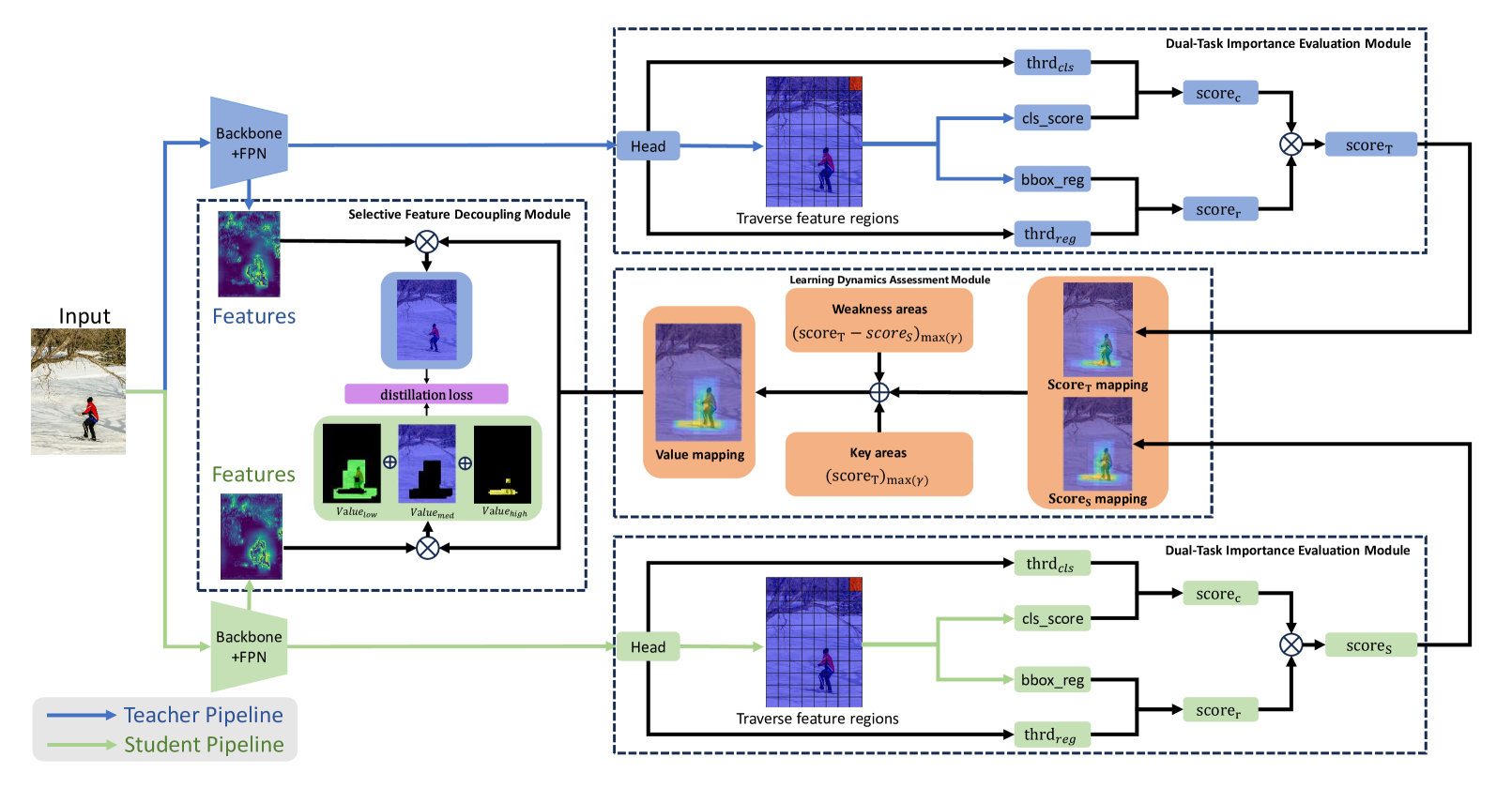
Task Integration Distillation for Object Detectors
Hai Su, ZhenWen Jian, Songsen Yu
0
0
Knowledge distillation is a widely adopted technique for model lightening. However, the performance of most knowledge distillation methods in the domain of object detection is not satisfactory. Typically, knowledge distillation approaches consider only the classification task among the two sub-tasks of an object detector, largely overlooking the regression task. This oversight leads to a partial understanding of the object detector's comprehensive task, resulting in skewed estimations and potentially adverse effects. Therefore, we propose a knowledge distillation method that addresses both the classification and regression tasks, incorporating a task significance strategy. By evaluating the importance of features based on the output of the detector's two sub-tasks, our approach ensures a balanced consideration of both classification and regression tasks in object detection. Drawing inspiration from real-world teaching processes and the definition of learning condition, we introduce a method that focuses on both key and weak areas. By assessing the value of features for knowledge distillation based on their importance differences, we accurately capture the current model's learning situation. This method effectively prevents the issue of biased predictions about the model's learning reality caused by an incomplete utilization of the detector's outputs.
4/3/2024
✨
Robust feature knowledge distillation for enhanced performance of lightweight crack segmentation models
Zhaohui Chen, Elyas Asadi Shamsabadi, Sheng Jiang, Luming Shen, Daniel Dias-da-Costa
0
0
Vision-based crack detection faces deployment challenges due to the size of robust models and edge device limitations. These can be addressed with lightweight models trained with knowledge distillation (KD). However, state-of-the-art (SOTA) KD methods compromise anti-noise robustness. This paper develops Robust Feature Knowledge Distillation (RFKD), a framework to improve robustness while retaining the precision of light models for crack segmentation. RFKD distils knowledge from a teacher model's logit layers and intermediate feature maps while leveraging mixed clean and noisy images to transfer robust patterns to the student model, improving its precision, generalisation, and anti-noise performance. To validate the proposed RFKD, a lightweight crack segmentation model, PoolingCrack Tiny (PCT), with only 0.5 M parameters, is also designed and used as the student to run the framework. The results show a significant enhancement in noisy images, with RFKD reaching a 62% enhanced mean Dice score (mDS) compared to SOTA KD methods.
4/10/2024

Robust Knowledge Distillation Based on Feature Variance Against Backdoored Teacher Model
Jinyin Chen, Xiaoming Zhao, Haibin Zheng, Xiao Li, Sheng Xiang, Haifeng Guo
0
0
Benefiting from well-trained deep neural networks (DNNs), model compression have captured special attention for computing resource limited equipment, especially edge devices. Knowledge distillation (KD) is one of the widely used compression techniques for edge deployment, by obtaining a lightweight student model from a well-trained teacher model released on public platforms. However, it has been empirically noticed that the backdoor in the teacher model will be transferred to the student model during the process of KD. Although numerous KD methods have been proposed, most of them focus on the distillation of a high-performing student model without robustness consideration. Besides, some research adopts KD techniques as effective backdoor mitigation tools, but they fail to perform model compression at the same time. Consequently, it is still an open problem to well achieve two objectives of robust KD, i.e., student model's performance and backdoor mitigation. To address these issues, we propose RobustKD, a robust knowledge distillation that compresses the model while mitigating backdoor based on feature variance. Specifically, RobustKD distinguishes the previous works in three key aspects: (1) effectiveness: by distilling the feature map of the teacher model after detoxification, the main task performance of the student model is comparable to that of the teacher model; (2) robustness: by reducing the characteristic variance between the teacher model and the student model, it mitigates the backdoor of the student model under backdoored teacher model scenario; (3) generic: RobustKD still has good performance in the face of multiple data models (e.g., WRN 28-4, Pyramid-200) and diverse DNNs (e.g., ResNet50, MobileNet).
6/6/2024