Knowledge Graph Tuning: Real-time Large Language Model Personalization based on Human Feedback

0
Sign in to get full access
Overview
- This paper presents a novel approach called "Knowledge Graph Tuning" (KGT) that enables real-time personalization of large language models based on human feedback.
- The key idea is to leverage a knowledge graph to guide the adaptation of the language model, allowing it to better align with the user's preferences and requirements.
- The paper demonstrates the effectiveness of KGT through experiments on a range of language understanding tasks, showing significant performance improvements compared to standard fine-tuning approaches.
Plain English Explanation
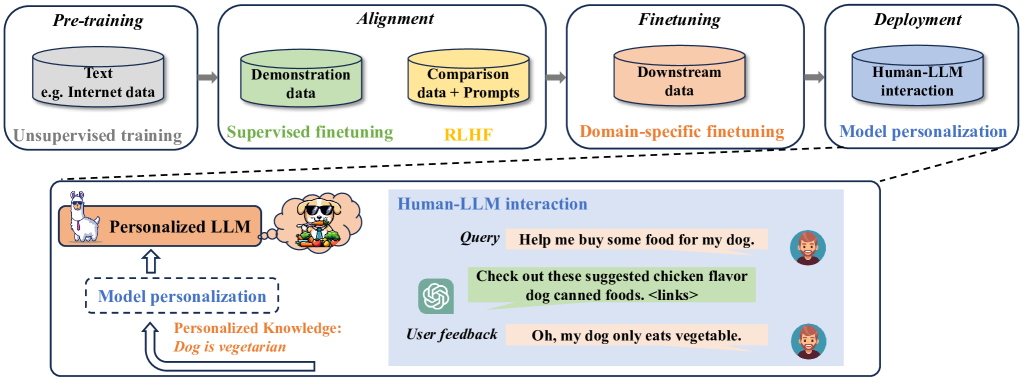
The paper introduces a new technique called "Knowledge Graph Tuning" (KGT) that can customize large language models to individual users in real-time. Large language models, like GPT-3, are powerful AI systems that can generate human-like text, answer questions, and perform various language-related tasks. However, these models are typically trained on a broad set of data and may not always align with a user's specific needs or preferences.
The KGT approach solves this problem by using a knowledge graph to guide the adaptation of the language model. A knowledge graph is a structured representation of information, like a database, that can capture relationships between different concepts. By incorporating this knowledge graph into the language model's training process, the researchers were able to personalize the model's behavior to better match the user's requirements.
For example, if a user is interested in history, the knowledge graph could help the language model provide more relevant and accurate information when answering questions or generating text related to historical topics. This personalization happens in real-time, without the need to retrain the entire language model from scratch.
The researchers demonstrated the effectiveness of KGT through various experiments, showing that it can significantly improve the model's performance on a range of language understanding tasks compared to standard fine-tuning approaches. This suggests that KGT could be a valuable tool for companies or individuals who need to tailor large language models to their specific needs.
Technical Explanation
The paper introduces a novel approach called "Knowledge Graph Tuning" (KGT) that enables real-time personalization of large language models based on human feedback. The key idea is to leverage a knowledge graph to guide the adaptation of the language model, allowing it to better align with the user's preferences and requirements.
The KGT framework consists of three main components: a knowledge graph, a language model, and a tuning module. The knowledge graph represents structured information about relevant concepts and their relationships. The language model, such as GPT-3, is the base model that is being personalized. The tuning module is responsible for updating the language model's parameters based on user feedback and the knowledge graph.
During the tuning process, the language model generates responses to user inputs, which are then evaluated by the user. The user's feedback, along with the knowledge graph, is used by the tuning module to adjust the language model's parameters in real-time. This allows the model to adapt its behavior to better align with the user's preferences and requirements.
The researchers evaluate the effectiveness of KGT on a range of language understanding tasks, including question answering, text generation, and intent classification. The results demonstrate that KGT can significantly outperform standard fine-tuning approaches, suggesting that it is a promising technique for personalizing large language models to individual users.
Critical Analysis
The paper presents a compelling approach to personalize large language models in real-time using a knowledge graph. The key strength of the KGT framework is its ability to leverage structured knowledge to guide the model's adaptation, which sets it apart from traditional fine-tuning methods.
One potential limitation of the approach is the reliance on a pre-existing knowledge graph. The quality and coverage of the knowledge graph can significantly impact the performance of the personalized language model. The paper does not provide much detail on how the knowledge graph was constructed or how it can be maintained and updated over time.
Additionally, the paper does not address potential privacy concerns or ethical considerations associated with real-time personalization of language models. As these models become more widely adopted, it will be important to consider the implications of such personalization techniques, particularly around data privacy and the potential for biases or unfair outcomes.
Further research could explore ways to automatically construct or expand knowledge graphs from user interactions, reducing the reliance on pre-existing knowledge sources. Investigations into the long-term stability and robustness of the personalized language models would also be valuable.
Conclusion
The "Knowledge Graph Tuning" (KGT) approach presented in this paper offers a promising solution for real-time personalization of large language models. By leveraging a knowledge graph to guide the adaptation of the language model, KGT can significantly improve performance on a range of language understanding tasks compared to standard fine-tuning methods.
The potential implications of this work are far-reaching, as it could enable the development of highly customized language models that better align with individual user needs and preferences. This could have significant benefits in a wide variety of applications, from personal assistants and chatbots to specialized language-based tools and services.
As the field of large language models continues to evolve, techniques like KGT will likely play an increasingly important role in ensuring these powerful AI systems can be effectively and responsibly tailored to the diverse needs of users. Further research and development in this area could lead to even more advanced personalization capabilities and unlock new possibilities for human-AI interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Knowledge Graph Tuning: Real-time Large Language Model Personalization based on Human Feedback
Jingwei Sun, Zhixu Du, Yiran Chen
Large language models (LLMs) have demonstrated remarkable proficiency in a range of natural language processing tasks. Once deployed, LLMs encounter users with personalized factual knowledge, and such personalized knowledge is consistently reflected through users' interactions with the LLMs. To enhance user experience, real-time model personalization is essential, allowing LLMs to adapt user-specific knowledge based on user feedback during human-LLM interactions. Existing methods mostly require back-propagation to finetune the model parameters, which incurs high computational and memory costs. In addition, these methods suffer from low interpretability, which will cause unforeseen impacts on model performance during long-term use, where the user's personalized knowledge is accumulated extensively.To address these challenges, we propose Knowledge Graph Tuning (KGT), a novel approach that leverages knowledge graphs (KGs) to personalize LLMs. KGT extracts personalized factual knowledge triples from users' queries and feedback and optimizes KGs without modifying the LLM parameters. Our method improves computational and memory efficiency by avoiding back-propagation and ensures interpretability by making the KG adjustments comprehensible to humans.Experiments with state-of-the-art LLMs, including GPT-2, Llama2, and Llama3, show that KGT significantly improves personalization performance while reducing latency and GPU memory costs. Ultimately, KGT offers a promising solution of effective, efficient, and interpretable real-time LLM personalization during user interactions with the LLMs.
Read more5/31/2024
0
KnowGPT: Knowledge Graph based Prompting for Large Language Models
Qinggang Zhang, Junnan Dong, Hao Chen, Daochen Zha, Zailiang Yu, Xiao Huang
Large Language Models (LLMs) have demonstrated remarkable capabilities in many real-world applications. Nonetheless, LLMs are often criticized for their tendency to produce hallucinations, wherein the models fabricate incorrect statements on tasks beyond their knowledge and perception. To alleviate this issue, researchers have explored leveraging the factual knowledge in knowledge graphs (KGs) to ground the LLM's responses in established facts and principles. However, most state-of-the-art LLMs are closed-source, making it challenging to develop a prompting framework that can efficiently and effectively integrate KGs into LLMs with hard prompts only. Generally, existing KG-enhanced LLMs usually suffer from three critical issues, including huge search space, high API costs, and laborious prompt engineering, that impede their widespread application in practice. To this end, we introduce a novel Knowledge Graph based PrompTing framework, namely KnowGPT, to enhance LLMs with domain knowledge. KnowGPT contains a knowledge extraction module to extract the most informative knowledge from KGs, and a context-aware prompt construction module to automatically convert extracted knowledge into effective prompts. Experiments on three benchmarks demonstrate that KnowGPT significantly outperforms all competitors. Notably, KnowGPT achieves a 92.6% accuracy on OpenbookQA leaderboard, comparable to human-level performance.
Read more6/5/2024
0
Prompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
Wenyu Huang, Guancheng Zhou, Mirella Lapata, Pavlos Vougiouklis, Sebastien Montella, Jeff Z. Pan
Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.
Read more5/13/2024

0
Knowledge Graph-Enhanced Large Language Models via Path Selection
Haochen Liu, Song Wang, Yaochen Zhu, Yushun Dong, Jundong Li
Large Language Models (LLMs) have shown unprecedented performance in various real-world applications. However, they are known to generate factually inaccurate outputs, a.k.a. the hallucination problem. In recent years, incorporating external knowledge extracted from Knowledge Graphs (KGs) has become a promising strategy to improve the factual accuracy of LLM-generated outputs. Nevertheless, most existing explorations rely on LLMs themselves to perform KG knowledge extraction, which is highly inflexible as LLMs can only provide binary judgment on whether a certain knowledge (e.g., a knowledge path in KG) should be used. In addition, LLMs tend to pick only knowledge with direct semantic relationship with the input text, while potentially useful knowledge with indirect semantics can be ignored. In this work, we propose a principled framework KELP with three stages to handle the above problems. Specifically, KELP is able to achieve finer granularity of flexible knowledge extraction by generating scores for knowledge paths with input texts via latent semantic matching. Meanwhile, knowledge paths with indirect semantic relationships with the input text can also be considered via trained encoding between the selected paths in KG and the input text. Experiments on real-world datasets validate the effectiveness of KELP.
Read more6/21/2024