Knowledge Transfer for Cross-Domain Reinforcement Learning: A Systematic Review
2404.17687
0
0

Abstract
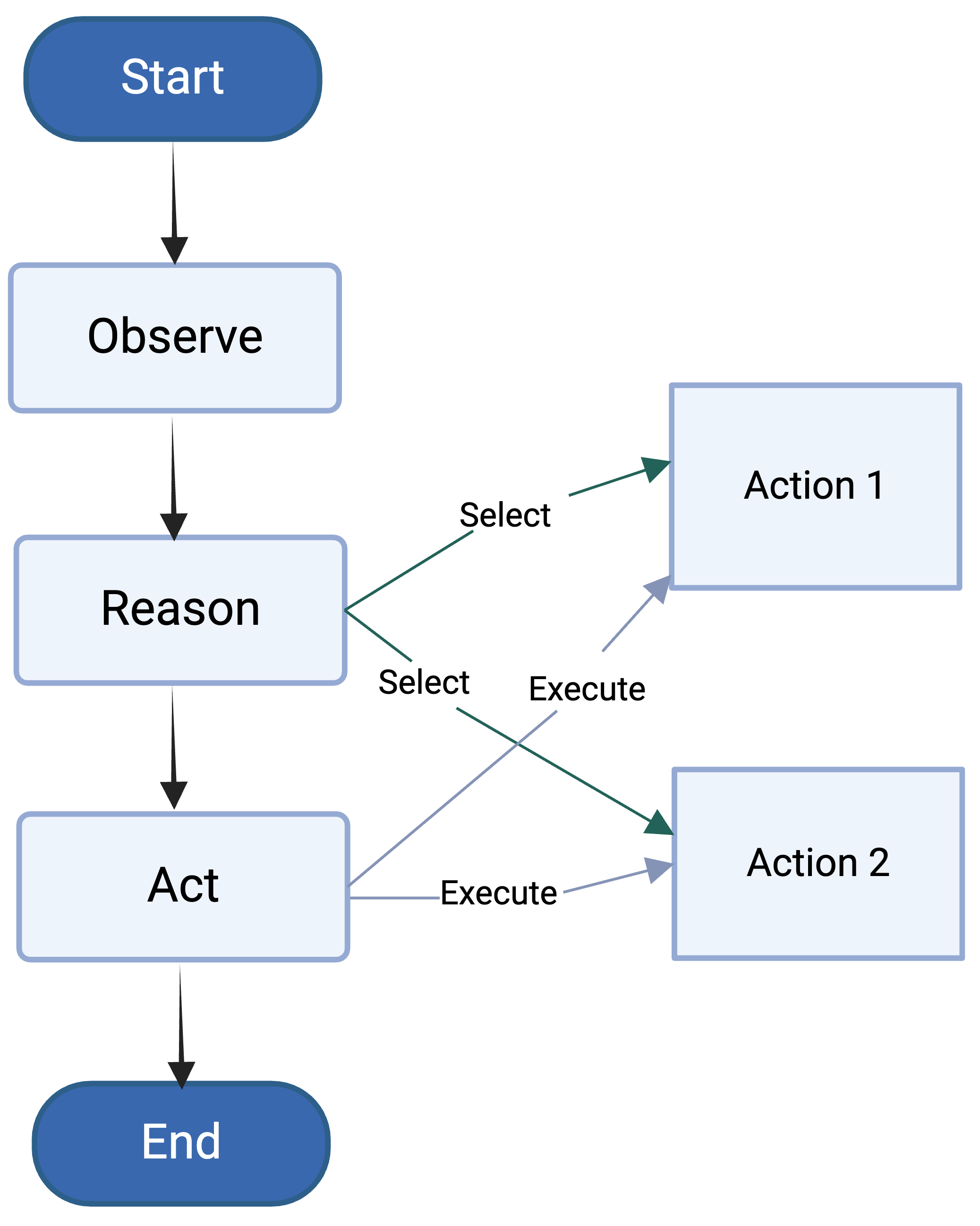
Reinforcement Learning (RL) provides a framework in which agents can be trained, via trial and error, to solve complex decision-making problems. Learning with little supervision causes RL methods to require large amounts of data, which renders them too expensive for many applications (e.g. robotics). By reusing knowledge from a different task, knowledge transfer methods present an alternative to reduce the training time in RL. Given how severe data scarcity can be, there has been a growing interest for methods capable of transferring knowledge across different domains (i.e. problems with different representation) due to the flexibility they offer. This review presents a unifying analysis of methods focused on transferring knowledge across different domains. Through a taxonomy based on a transfer-approach categorization, and a characterization of works based on their data-assumption requirements, the objectives of this article are to 1) provide a comprehensive and systematic revision of knowledge transfer methods for the cross-domain RL setting, 2) categorize and characterize these methods to provide an analysis based on relevant features such as their transfer approach and data requirements, and 3) discuss the main challenges regarding cross-domain knowledge transfer, as well as ideas of future directions worth exploring to address these problems.
Create account to get full access
Overview
- Reinforcement Learning
- Transfer Learning
- Imitation Learning
- Cross Domain
- Review
Plain English Explanation
This paper provides a comprehensive review of research on knowledge transfer for cross-domain reinforcement learning. The key idea is to enable reinforcement learning algorithms to learn effectively in new environments or domains, by leveraging knowledge gained from previous experiences in related domains.
This is an important challenge, as reinforcement learning can be highly dependent on the specific environment it is trained in. By transferring knowledge across domains, reinforcement learning agents can potentially learn faster and perform better in unfamiliar settings. The review covers various techniques for achieving this, such as meta-learning, skill discovery, and cross-domain recommendation.
By summarizing the state-of-the-art research in this area, the paper provides a valuable resource for researchers and practitioners interested in advancing the field of cross-domain reinforcement learning.
Technical Explanation
The paper presents a comprehensive review of the literature on knowledge transfer for cross-domain reinforcement learning. The authors analyze a wide range of techniques and approaches, including:
- Transfer Learning: Methods that enable the transfer of knowledge or skills learned in one domain to improve performance in a different, but related, domain.
- Imitation Learning: Strategies that allow an agent to learn by observing and imitating the behavior of experts or other agents.
- Meta-Learning: Techniques that enable an agent to learn how to learn, allowing it to quickly adapt to new environments or tasks.
- Skill Discovery: Algorithms that can identify and transfer useful skills or behaviors from one domain to another.
The review covers both theoretical and empirical studies, highlighting the key insights, challenges, and future research directions in this field. The authors discuss the various problem formulations, evaluation methodologies, and the performance of different transfer learning approaches across a variety of domains, such as robotics, game-playing, and natural language processing.
Critical Analysis
The review provides a thorough and well-structured overview of the current state of research in cross-domain reinforcement learning. The authors have done an excellent job of synthesizing a vast body of literature and identifying the key themes, techniques, and open problems in this field.
One potential limitation of the review is that it focuses primarily on the technical aspects of the research, with less emphasis on the broader implications and real-world applications of these techniques. It would be interesting to see the authors discuss the societal impact and potential ethical considerations of widespread adoption of cross-domain reinforcement learning, such as issues around transparency, fairness, and safety.
Additionally, the review could have delved deeper into the practical challenges and limitations of implementing these techniques in real-world scenarios. For example, the paper could have discussed the difficulties of achieving successful knowledge transfer in the presence of significant domain shifts, or the computational and data requirements of some of the more complex meta-learning approaches.
Overall, this review is a valuable resource for researchers and practitioners working in the field of reinforcement learning and transfer learning. It provides a comprehensive and well-organized summary of the current state of the art, and serves as a solid foundation for further exploration and innovation in this rapidly evolving area of study.
Conclusion
This systematic review provides a comprehensive overview of the current state of research on knowledge transfer for cross-domain reinforcement learning. By summarizing a wide range of techniques, including transfer learning, imitation learning, meta-learning, and skill discovery, the authors offer a valuable resource for researchers and practitioners interested in advancing the field.
The review highlights the importance of enabling reinforcement learning agents to effectively leverage knowledge gained in one domain to perform well in new, unfamiliar environments. This is a key challenge in realizing the full potential of reinforcement learning, and the techniques discussed in this paper represent significant progress towards addressing this problem.
While the review focuses primarily on the technical aspects of the research, it also raises important questions about the broader implications and practical challenges of implementing these techniques in real-world settings. As the field continues to evolve, further research is needed to address these considerations and unlock the transformative potential of cross-domain reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
Robust Knowledge Transfer in Tiered Reinforcement Learning
Jiawei Huang, Niao He
0
0
In this paper, we study the Tiered Reinforcement Learning setting, a parallel transfer learning framework, where the goal is to transfer knowledge from the low-tier (source) task to the high-tier (target) task to reduce the exploration risk of the latter while solving the two tasks in parallel. Unlike previous work, we do not assume the low-tier and high-tier tasks share the same dynamics or reward functions, and focus on robust knowledge transfer without prior knowledge on the task similarity. We identify a natural and necessary condition called the ``Optimal Value Dominance'' for our objective. Under this condition, we propose novel online learning algorithms such that, for the high-tier task, it can achieve constant regret on partial states depending on the task similarity and retain near-optimal regret when the two tasks are dissimilar, while for the low-tier task, it can keep near-optimal without making sacrifice. Moreover, we further study the setting with multiple low-tier tasks, and propose a novel transfer source selection mechanism, which can ensemble the information from all low-tier tasks and allow provable benefits on a much larger state-action space.
6/14/2024
🔄
Transfer Learning in Robotics: An Upcoming Breakthrough? A Review of Promises and Challenges
No'emie Jaquier, Michael C. Welle, Andrej Gams, Kunpeng Yao, Bernardo Fichera, Aude Billard, Alev{s} Ude, Tamim Asfour, Danica Kragic
0
0
Transfer learning is a conceptually-enticing paradigm in pursuit of truly intelligent embodied agents. The core concept -- reusing prior knowledge to learn in and from novel situations -- is successfully leveraged by humans to handle novel situations. In recent years, transfer learning has received renewed interest from the community from different perspectives, including imitation learning, domain adaptation, and transfer of experience from simulation to the real world, among others. In this paper, we unify the concept of transfer learning in robotics and provide the first taxonomy of its kind considering the key concepts of robot, task, and environment. Through a review of the promises and challenges in the field, we identify the need of transferring at different abstraction levels, the need of quantifying the transfer gap and the quality of transfer, as well as the dangers of negative transfer. Via this position paper, we hope to channel the effort of the community towards the most significant roadblocks to realize the full potential of transfer learning in robotics.
5/3/2024
Leveraging Multi-AI Agents for Cross-Domain Knowledge Discovery
Shiva Aryal, Tuyen Do, Bisesh Heyojoo, Sandeep Chataut, Bichar Dip Shrestha Gurung, Venkataramana Gadhamshetty, Etienne Gnimpieba
0
0
In the rapidly evolving field of artificial intelligence, the ability to harness and integrate knowledge across various domains stands as a paramount challenge and opportunity. This study introduces a novel approach to cross-domain knowledge discovery through the deployment of multi-AI agents, each specialized in distinct knowledge domains. These AI agents, designed to function as domain-specific experts, collaborate in a unified framework to synthesize and provide comprehensive insights that transcend the limitations of single-domain expertise. By facilitating seamless interaction among these agents, our platform aims to leverage the unique strengths and perspectives of each, thereby enhancing the process of knowledge discovery and decision-making. We present a comparative analysis of the different multi-agent workflow scenarios evaluating their performance in terms of efficiency, accuracy, and the breadth of knowledge integration. Through a series of experiments involving complex, interdisciplinary queries, our findings demonstrate the superior capability of domain specific multi-AI agent system in identifying and bridging knowledge gaps. This research not only underscores the significance of collaborative AI in driving innovation but also sets the stage for future advancements in AI-driven, cross-disciplinary research and application. Our methods were evaluated on a small pilot data and it showed a trend we expected, if we increase the amount of data we custom train the agents, the trend is expected to be more smooth.
4/15/2024
📊
Contrastive Representation for Data Filtering in Cross-Domain Offline Reinforcement Learning
Xiaoyu Wen, Chenjia Bai, Kang Xu, Xudong Yu, Yang Zhang, Xuelong Li, Zhen Wang
0
0
Cross-domain offline reinforcement learning leverages source domain data with diverse transition dynamics to alleviate the data requirement for the target domain. However, simply merging the data of two domains leads to performance degradation due to the dynamics mismatch. Existing methods address this problem by measuring the dynamics gap via domain classifiers while relying on the assumptions of the transferability of paired domains. In this paper, we propose a novel representation-based approach to measure the domain gap, where the representation is learned through a contrastive objective by sampling transitions from different domains. We show that such an objective recovers the mutual-information gap of transition functions in two domains without suffering from the unbounded issue of the dynamics gap in handling significantly different domains. Based on the representations, we introduce a data filtering algorithm that selectively shares transitions from the source domain according to the contrastive score functions. Empirical results on various tasks demonstrate that our method achieves superior performance, using only 10% of the target data to achieve 89.2% of the performance on 100% target dataset with state-of-the-art methods.
5/13/2024