Knowledgeable Agents by Offline Reinforcement Learning from Large Language Model Rollouts
2404.09248
0
0
Abstract
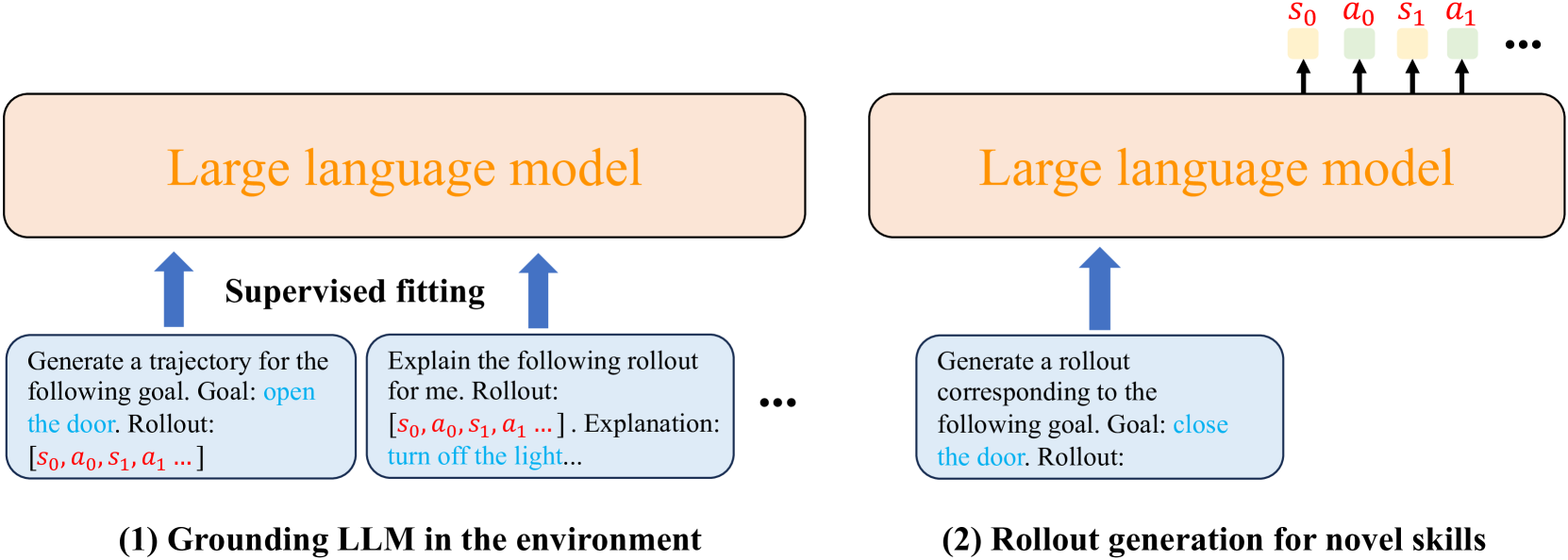
Reinforcement learning (RL) trains agents to accomplish complex tasks through environmental interaction data, but its capacity is also limited by the scope of the available data. To obtain a knowledgeable agent, a promising approach is to leverage the knowledge from large language models (LLMs). Despite previous studies combining LLMs with RL, seamless integration of the two components remains challenging due to their semantic gap. This paper introduces a novel method, Knowledgeable Agents from Language Model Rollouts (KALM), which extracts knowledge from LLMs in the form of imaginary rollouts that can be easily learned by the agent through offline reinforcement learning methods. The primary challenge of KALM lies in LLM grounding, as LLMs are inherently limited to textual data, whereas environmental data often comprise numerical vectors unseen to LLMs. To address this, KALM fine-tunes the LLM to perform various tasks based on environmental data, including bidirectional translation between natural language descriptions of skills and their corresponding rollout data. This grounding process enhances the LLM's comprehension of environmental dynamics, enabling it to generate diverse and meaningful imaginary rollouts that reflect novel skills. Initial empirical evaluations on the CLEVR-Robot environment demonstrate that KALM enables agents to complete complex rephrasings of task goals and extend their capabilities to novel tasks requiring unprecedented optimal behaviors. KALM achieves a success rate of 46% in executing tasks with unseen goals, substantially surpassing the 26% success rate achieved by baseline methods. Furthermore, KALM effectively enables the LLM to comprehend environmental dynamics, resulting in the generation of meaningful imaginary rollouts that reflect novel skills and demonstrate the seamless integration of large language models and reinforcement learning.
Create account to get full access
Overview
- This paper explores using offline reinforcement learning from large language model (LLM) rollouts to train knowledgeable agents.
- The authors demonstrate that this approach can produce agents that exhibit strong task performance and language understanding capabilities.
- The research has implications for developing more capable and knowledgeable AI agents that can assist humans in a variety of domains.
Plain English Explanation
The researchers in this paper looked at a new way to train AI agents, or digital assistants, to be more knowledgeable and capable. Instead of the typical approach of training agents directly on task data, they used a technique called "offline reinforcement learning" to train the agents using the output, or "rollouts", from a large language model (LLM).
Large language models are AI systems that have been trained on vast amounts of text data, allowing them to generate human-like language and demonstrate broad knowledge. The researchers hypothesized that by learning from these LLM rollouts, the agents could acquire similar language understanding and knowledge, while also being optimized for specific tasks through the reinforcement learning process.
The key idea is that the LLM rollouts provide a rich source of diverse, high-quality training data that can imbue the agents with deep knowledge and capabilities. By learning from this data in an offline setting, the agents can become highly knowledgeable without the need for direct interaction with the real world, which can be costly or dangerous in certain applications.
The paper demonstrates that this approach can indeed produce agents that excel at both task performance and language understanding. This could lead to the development of more capable and versatile AI assistants that can help humans with a wide range of tasks, drawing on a deep well of knowledge and language abilities.
Technical Explanation
The researchers in this paper propose a novel approach for training knowledgeable agents using offline reinforcement learning from large language model (LLM) rollouts.
The key idea is to leverage the broad knowledge and language understanding capabilities of LLMs, such as GPT-3, by using their generated rollouts as training data for reinforcement learning. This allows the agents to acquire similar knowledge and language abilities, while also being optimized for specific tasks through the reinforcement learning process.
The experimental setup involves first training an LLM on a large corpus of text data. The LLM is then used to generate a large number of rollouts, which are sequences of actions and observations that the model would take in hypothetical environments. These rollouts are then used as the training data for the reinforcement learning agent, which is optimized to maximize a task-specific reward signal.
The results show that this approach can produce agents that exhibit strong performance on a variety of tasks, while also demonstrating impressive language understanding capabilities. The agents are able to engage in coherent conversations, answer questions, and even complete open-ended tasks that require reasoning and knowledge beyond the specific training domain.
Critical Analysis
The paper presents a compelling approach for training highly capable and knowledgeable agents, but it also has some potential limitations and areas for further research.
One key concern is the reliance on the quality and biases of the underlying LLM. If the LLM has gaps in its knowledge or exhibits problematic biases, these issues may be inherited by the trained agents. The authors acknowledge this and suggest that further research is needed to understand the effects of LLM biases and how to mitigate them.
Additionally, the offline reinforcement learning process, while efficient, may not fully capture the nuances of real-world interaction and feedback that agents would experience in a live setting. It's possible that a hybrid approach, combining offline and online learning, could lead to even more capable and well-rounded agents.
Another area for further exploration is the scalability of the approach. The paper demonstrates results on relatively simple tasks, but it's unclear how well the method would scale to more complex, open-ended domains. Investigating the performance and knowledge transfer of these agents in broader, more ambiguous settings would be a valuable next step.
Overall, the paper presents a promising direction for developing highly capable and knowledgeable AI agents, but there are still important challenges and considerations to address in future research.
Conclusion
This paper explores a novel approach for training knowledgeable AI agents using offline reinforcement learning from large language model rollouts. The key insight is that by leveraging the broad knowledge and language understanding capabilities of LLMs, agents can acquire similar abilities while also being optimized for specific tasks.
The results demonstrate that this approach can produce agents with strong task performance and impressive language skills, suggesting that it could be a valuable tool for developing more capable and versatile AI assistants. However, the paper also highlights important considerations around the influence of LLM biases and the need to further explore the scalability and real-world applicability of the method.
As the field of AI continues to advance, techniques like the one presented in this paper will play a crucial role in creating AI systems that can truly assist and collaborate with humans across a wide range of domains. By combining the unique strengths of large language models and reinforcement learning, researchers are making important strides towards more knowledgeable and capable AI agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
0
0
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
4/30/2024
💬
Large Language Model as a Policy Teacher for Training Reinforcement Learning Agents
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, Bin Liu
0
0
Recent studies have uncovered the potential of Large Language Models (LLMs) in addressing complex sequential decision-making tasks through the provision of high-level instructions. However, LLM-based agents lack specialization in tackling specific target problems, particularly in real-time dynamic environments. Additionally, deploying an LLM-based agent in practical scenarios can be both costly and time-consuming. On the other hand, reinforcement learning (RL) approaches train agents that specialize in the target task but often suffer from low sampling efficiency and high exploration costs. In this paper, we introduce a novel framework that addresses these challenges by training a smaller, specialized student RL agent using instructions from an LLM-based teacher agent. By incorporating the guidance from the teacher agent, the student agent can distill the prior knowledge of the LLM into its own model. Consequently, the student agent can be trained with significantly less data. Moreover, through further training with environment feedback, the student agent surpasses the capabilities of its teacher for completing the target task. We conducted experiments on challenging MiniGrid and Habitat environments, specifically designed for embodied AI research, to evaluate the effectiveness of our framework. The results clearly demonstrate that our approach achieves superior performance compared to strong baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
4/23/2024
Mental Modeling of Reinforcement Learning Agents by Language Models
Wenhao Lu, Xufeng Zhao, Josua Spisak, Jae Hee Lee, Stefan Wermter
0
0
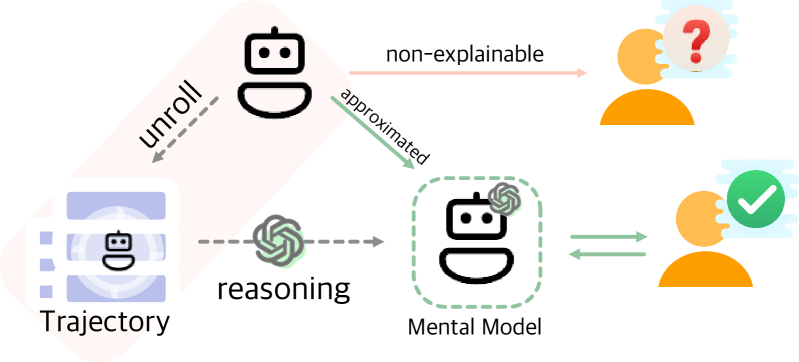
Can emergent language models faithfully model the intelligence of decision-making agents? Though modern language models exhibit already some reasoning ability, and theoretically can potentially express any probable distribution over tokens, it remains underexplored how the world knowledge these pretrained models have memorized can be utilized to comprehend an agent's behaviour in the physical world. This study empirically examines, for the first time, how well large language models (LLMs) can build a mental model of agents, termed agent mental modelling, by reasoning about an agent's behaviour and its effect on states from agent interaction history. This research may unveil the potential of leveraging LLMs for elucidating RL agent behaviour, addressing a key challenge in eXplainable reinforcement learning (XRL). To this end, we propose specific evaluation metrics and test them on selected RL task datasets of varying complexity, reporting findings on agent mental model establishment. Our results disclose that LLMs are not yet capable of fully mental modelling agents through inference alone without further innovations. This work thus provides new insights into the capabilities and limitations of modern LLMs.
6/27/2024
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
0
0
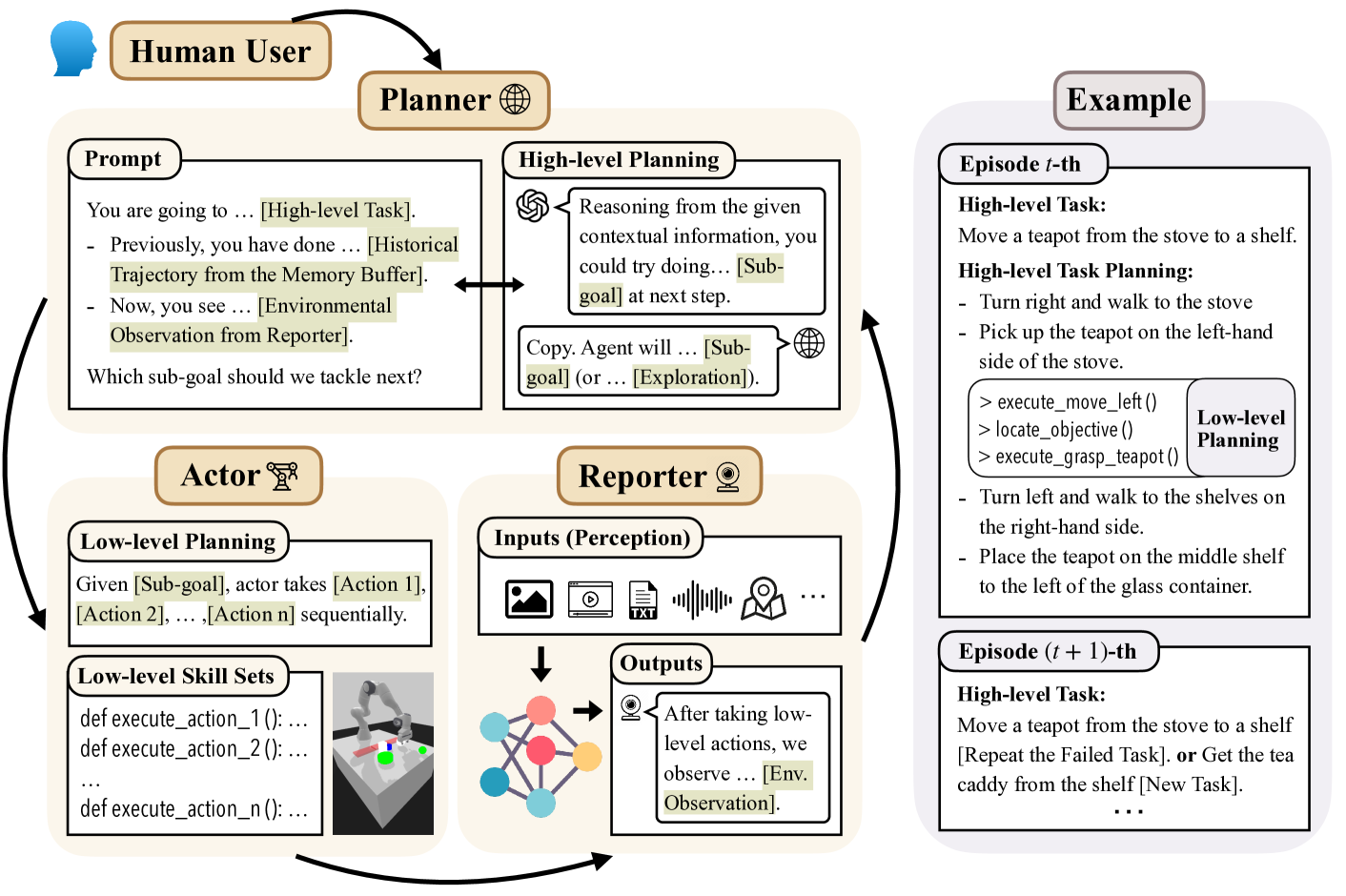
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
5/31/2024