Kvasir-VQA: A Text-Image Pair GI Tract Dataset

0
Sign in to get full access
Overview
- Presents a new text-image pair dataset called Kvasir-VQA for visual question answering (VQA) on the gastrointestinal (GI) tract.
- Focuses on medical image analysis and AI in healthcare.
- Aims to support research in VQA, image captioning, and other AI tasks for GI diagnostics.
Plain English Explanation
The paper introduces a new dataset called Kvasir-VQA that contains pairs of medical images and text-based questions about those images. The goal is to help develop AI systems that can analyze medical images and answer questions about them.
The dataset is focused on the gastrointestinal (GI) tract, which includes the digestive organs like the stomach and intestines. Analyzing GI tract images is an important task for diagnosing and monitoring medical conditions.
By providing a large set of GI tract images paired with questions about them, the Kvasir-VQA dataset aims to support research in visual question answering (VQA) and other AI techniques for medical image analysis. The hope is that this will lead to AI systems that can assist doctors in interpreting medical images more efficiently.
Technical Explanation
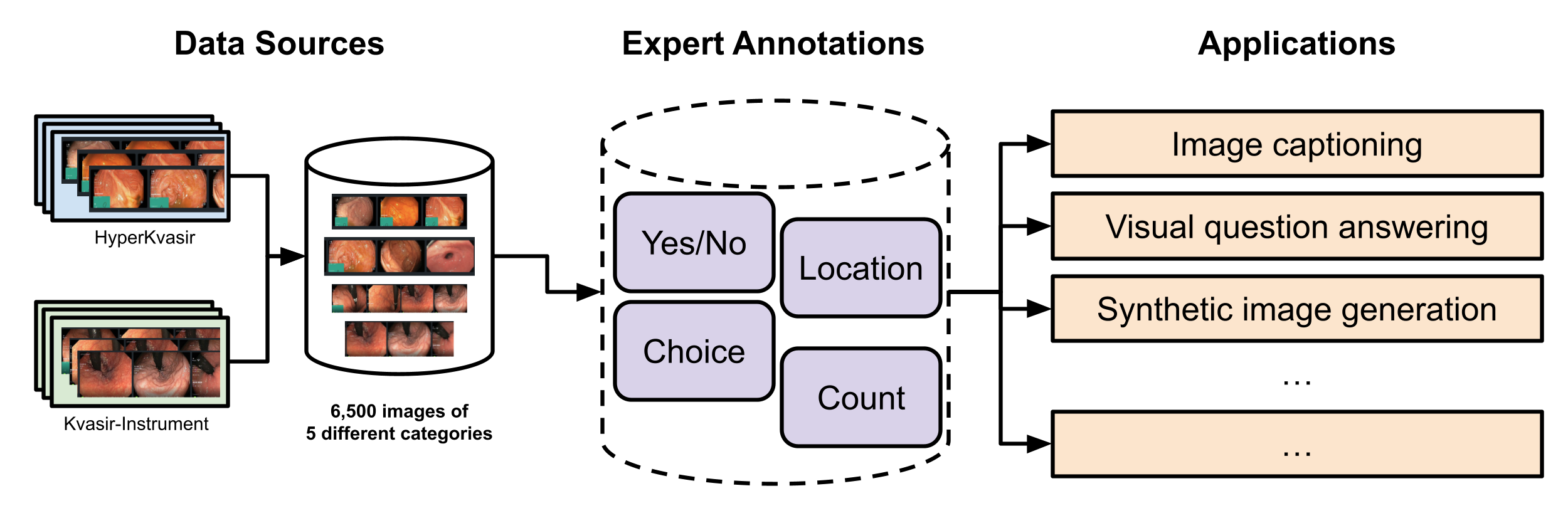
The paper describes the process of creating the Kvasir-VQA dataset. It contains over 35,000 medical images of the GI tract along with over 175,000 text-based questions about those images. The images were collected from various public medical databases, and the questions were generated by medical experts.
The dataset is designed to support multiple AI tasks beyond just VQA, such as image captioning and scene graph generation. It provides a standardized benchmark for evaluating the performance of AI systems on GI tract image analysis.
The paper also describes several baseline VQA models trained on the Kvasir-VQA dataset, including transformer-based and knowledge-enhanced approaches. These experiments demonstrate the challenges in achieving high accuracy on this medical VQA task compared to generic VQA datasets.
Critical Analysis
The paper acknowledges some limitations of the Kvasir-VQA dataset, such as the potential for biases in the image and question curation process. It also notes that the dataset only covers a subset of GI tract conditions and could be expanded further.
Additionally, the paper does not provide a detailed analysis of the types of questions or visual reasoning skills required to answer them. More insight into the dataset's difficulty and the AI capabilities needed would be helpful for contextualizing the baseline model performance.
Overall, the Kvasir-VQA dataset represents an important contribution to medical image analysis research, but additional work is needed to fully validate its usefulness and ensure it is representative of real-world clinical scenarios.
Conclusion
The Kvasir-VQA dataset introduces a new benchmark for AI-powered analysis of medical images, with a focus on the gastrointestinal tract. By providing a large set of image-question pairs, the dataset aims to advance research in visual question answering, image captioning, and other AI techniques for supporting clinicians in GI diagnostics.
While the dataset has some limitations, it represents an important step towards bridging the gap between AI and medical image interpretation. Continued development and testing of Kvasir-VQA could lead to the creation of AI assistants that enhance the efficiency and accuracy of GI tract disease detection and monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Kvasir-VQA: A Text-Image Pair GI Tract Dataset
Sushant Gautam, Andrea Stor{aa}s, Cise Midoglu, Steven A. Hicks, Vajira Thambawita, P{aa}l Halvorsen, Michael A. Riegler
We introduce Kvasir-VQA, an extended dataset derived from the HyperKvasir and Kvasir-Instrument datasets, augmented with question-and-answer annotations to facilitate advanced machine learning tasks in Gastrointestinal (GI) diagnostics. This dataset comprises 6,500 annotated images spanning various GI tract conditions and surgical instruments, and it supports multiple question types including yes/no, choice, location, and numerical count. The dataset is intended for applications such as image captioning, Visual Question Answering (VQA), text-based generation of synthetic medical images, object detection, and classification. Our experiments demonstrate the dataset's effectiveness in training models for three selected tasks, showcasing significant applications in medical image analysis and diagnostics. We also present evaluation metrics for each task, highlighting the usability and versatility of our dataset. The dataset and supporting artifacts are available at https://datasets.simula.no/kvasir-vqa.
Read more9/4/2024

0
ViTextVQA: A Large-Scale Visual Question Answering Dataset for Evaluating Vietnamese Text Comprehension in Images
Quan Van Nguyen, Dan Quang Tran, Huy Quang Pham, Thang Kien-Bao Nguyen, Nghia Hieu Nguyen, Kiet Van Nguyen, Ngan Luu-Thuy Nguyen
Visual Question Answering (VQA) is a complicated task that requires the capability of simultaneously processing natural language and images. Initially, this task was researched, focusing on methods to help machines understand objects and scene contexts in images. However, some text appearing in the image that carries explicit information about the full content of the image is not mentioned. Along with the continuous development of the AI era, there have been many studies on the reading comprehension ability of VQA models in the world. As a developing country, conditions are still limited, and this task is still open in Vietnam. Therefore, we introduce the first large-scale dataset in Vietnamese specializing in the ability to understand text appearing in images, we call it ViTextVQA (textbf{Vi}etnamese textbf{Text}-based textbf{V}isual textbf{Q}uestion textbf{A}nswering dataset) which contains textbf{over 16,000} images and textbf{over 50,000} questions with answers. Through meticulous experiments with various state-of-the-art models, we uncover the significance of the order in which tokens in OCR text are processed and selected to formulate answers. This finding helped us significantly improve the performance of the baseline models on the ViTextVQA dataset. Our dataset is available at this href{https://github.com/minhquan6203/ViTextVQA-Dataset}{link} for research purposes.
Read more4/17/2024
🖼️
0
Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
Xinyue Hu, Lin Gu, Qiyuan An, Mengliang Zhang, Liangchen Liu, Kazuma Kobayashi, Tatsuya Harada, Ronald M. Summers, Yingying Zhu
To contribute to automating the medical vision-language model, we propose a novel Chest-Xray Difference Visual Question Answering (VQA) task. Given a pair of main and reference images, this task attempts to answer several questions on both diseases and, more importantly, the differences between them. This is consistent with the radiologist's diagnosis practice that compares the current image with the reference before concluding the report. We collect a new dataset, namely MIMIC-Diff-VQA, including 700,703 QA pairs from 164,324 pairs of main and reference images. Compared to existing medical VQA datasets, our questions are tailored to the Assessment-Diagnosis-Intervention-Evaluation treatment procedure used by clinical professionals. Meanwhile, we also propose a novel expert knowledge-aware graph representation learning model to address this task. The proposed baseline model leverages expert knowledge such as anatomical structure prior, semantic, and spatial knowledge to construct a multi-relationship graph, representing the image differences between two images for the image difference VQA task. The dataset and code can be found at https://github.com/Holipori/MIMIC-Diff-VQA. We believe this work would further push forward the medical vision language model.
Read more8/29/2024

0
Advancing Surgical VQA with Scene Graph Knowledge
Kun Yuan, Manasi Kattel, Joel L. Lavanchy, Nassir Navab, Vinkle Srivastav, Nicolas Padoy
Modern operating room is becoming increasingly complex, requiring innovative intra-operative support systems. While the focus of surgical data science has largely been on video analysis, integrating surgical computer vision with language capabilities is emerging as a necessity. Our work aims to advance Visual Question Answering (VQA) in the surgical context with scene graph knowledge, addressing two main challenges in the current surgical VQA systems: removing question-condition bias in the surgical VQA dataset and incorporating scene-aware reasoning in the surgical VQA model design. First, we propose a Surgical Scene Graph-based dataset, SSG-QA, generated by employing segmentation and detection models on publicly available datasets. We build surgical scene graphs using spatial and action information of instruments and anatomies. These graphs are fed into a question engine, generating diverse QA pairs. Our SSG-QA dataset provides a more complex, diverse, geometrically grounded, unbiased, and surgical action-oriented dataset compared to existing surgical VQA datasets. We then propose SSG-QA-Net, a novel surgical VQA model incorporating a lightweight Scene-embedded Interaction Module (SIM), which integrates geometric scene knowledge in the VQA model design by employing cross-attention between the textual and the scene features. Our comprehensive analysis of the SSG-QA dataset shows that SSG-QA-Net outperforms existing methods across different question types and complexities. We highlight that the primary limitation in the current surgical VQA systems is the lack of scene knowledge to answer complex queries. We present a novel surgical VQA dataset and model and show that results can be significantly improved by incorporating geometric scene features in the VQA model design. The source code and the dataset will be made publicly available at: https://github.com/CAMMA-public/SSG-QA
Read more6/26/2024