Label Delay in Online Continual Learning
2312.00923
0
0
🧪
Abstract
Online continual learning, the process of training models on streaming data, has gained increasing attention in recent years. However, a critical aspect often overlooked is the label delay, where new data may not be labeled due to slow and costly annotation processes. We introduce a new continual learning framework with explicit modeling of the label delay between data and label streams over time steps. In each step, the framework reveals both unlabeled data from the current time step $t$ and labels delayed with $d$ steps, from the time step $t-d$. In our extensive experiments amounting to 1060 GPU days, we show that merely augmenting the computational resources is insufficient to tackle this challenge. Our findings underline a notable performance decline when solely relying on labeled data when the label delay becomes significant. More surprisingly, when using state-of-the-art SSL and TTA techniques to utilize the newer, unlabeled data, they fail to surpass the performance of a naive method that simply trains on the delayed supervised stream. To this end, we introduce a simple, efficient baseline that rehearses from the labeled memory samples that are most similar to the new unlabeled samples. This method bridges the accuracy gap caused by label delay without significantly increasing computational complexity. We show experimentally that our method is the least affected by the label delay factor and in some cases successfully recovers the accuracy of the non-delayed counterpart. We conduct various ablations and sensitivity experiments, demonstrating the effectiveness of our approach.
Create account to get full access
Overview
- The paper introduces a new continual learning framework that explicitly models the label delay between data and label streams over time.
- The framework reveals both unlabeled data from the current time step and labels delayed by a certain number of steps from the past.
- The authors' extensive experiments spanning 1060 GPU days show that simply increasing computational resources is insufficient to address the challenge of label delay.
- The authors find that state-of-the-art semi-supervised learning (SSL) and test-time augmentation (TTA) techniques fail to surpass the performance of a naive method that trains on the delayed supervised stream.
- The authors propose a simple, efficient baseline that rehearses from the labeled memory samples most similar to the new unlabeled samples, effectively bridging the accuracy gap caused by label delay.
Plain English Explanation
In the field of machine learning, continual learning is the process of training models on data that arrives over time, often in a stream. This is an important problem, as it allows models to continuously learn and adapt to new information.
However, one critical aspect that is often overlooked is the label delay. This means that the labels (the "correct answers") for new data may not be available immediately, due to slow and costly annotation processes. The paper introduces a new continual learning framework that explicitly addresses this label delay challenge.
The framework reveals both the unlabeled data from the current time step and the labels that are delayed by a certain number of steps from the past. The key idea is to use this combination of recent unlabeled data and delayed labeled data to train the model effectively, even when there is a significant delay in obtaining the labels.
The authors' extensive experiments show that simply increasing computational resources is not enough to solve this problem. They also find that advanced techniques like semi-supervised learning and test-time augmentation, which aim to utilize the unlabeled data, still fail to match the performance of a simple method that just trains on the delayed supervised stream.
To address this, the authors propose a simple and efficient baseline that "rehearses" from the labeled memory samples that are most similar to the new unlabeled samples. This helps the model bridge the accuracy gap caused by the label delay, without significantly increasing the computational complexity.
The authors demonstrate the effectiveness of their approach through various experiments and ablation studies, showing that it is the least affected by the label delay factor and can even recover the accuracy of the non-delayed counterpart in some cases.
Technical Explanation
The paper introduces a new continual learning framework that explicitly models the label delay between data and label streams over time steps. In each time step, the framework reveals both unlabeled data from the current time step $t$ and labels delayed with $d$ steps, from the time step $t-d$.
The authors' extensive experiments, amounting to 1060 GPU days, show that merely augmenting the computational resources is insufficient to tackle the challenge of label delay. Their findings underline a notable performance decline when solely relying on labeled data as the label delay becomes significant.
More surprisingly, the authors find that when using state-of-the-art semi-supervised learning (SSL) and test-time augmentation (TTA) techniques to utilize the newer, unlabeled data, they fail to surpass the performance of a naive method that simply trains on the delayed supervised stream.
To address this, the authors introduce a simple, efficient baseline that rehearses from the labeled memory samples that are most similar to the new unlabeled samples. This method bridges the accuracy gap caused by label delay without significantly increasing computational complexity. The authors show experimentally that their method is the least affected by the label delay factor and in some cases successfully recovers the accuracy of the non-delayed counterpart.
Critical Analysis
The paper highlights a crucial and often overlooked aspect of continual learning: the label delay. The authors' extensive experiments and findings underscore the significant impact of label delay on model performance, even when using advanced techniques like SSL and TTA.
One potential limitation of the research is the lack of discussion on the generalizability of the proposed method. While the authors demonstrate the effectiveness of their approach on their experimental setup, it would be valuable to understand how it might perform on a wider range of continual learning benchmarks and real-world scenarios.
Additionally, the paper does not provide much insight into the underlying reasons why the state-of-the-art SSL and TTA techniques fail to surpass the performance of the naive method. A deeper analysis of the strengths and weaknesses of these approaches in the context of label delay could further strengthen the contribution of this work.
Future research could explore the interplay between label delay, data distribution shifts, and other continual learning challenges, as well as investigate more advanced rehearsal techniques that can effectively leverage the unlabeled data during the label delay period.
Continual learning with pre-trained models is another area that could benefit from the insights provided in this paper, as the availability of labeled data is a common challenge in this setting as well.
Conclusion
The paper introduces a novel continual learning framework that explicitly models the label delay between data and label streams. The authors' extensive experiments demonstrate the significant impact of label delay on model performance and highlight the limitations of simply increasing computational resources or using state-of-the-art SSL and TTA techniques to address this challenge.
The authors' proposed simple and efficient baseline, which rehearses from the labeled memory samples most similar to the new unlabeled samples, effectively bridges the accuracy gap caused by label delay. This work underscores the importance of considering label delay in continual learning and provides a promising direction for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Controlling Forgetting with Test-Time Data in Continual Learning
Vaibhav Singh, Rahaf Aljundi, Eugene Belilovsky
0
0
Foundational vision-language models have shown impressive performance on various downstream tasks. Yet, there is still a pressing need to update these models later as new tasks or domains become available. Ongoing Continual Learning (CL) research provides techniques to overcome catastrophic forgetting of previous information when new knowledge is acquired. To date, CL techniques focus only on the supervised training sessions. This results in significant forgetting yielding inferior performance to even the prior model zero shot performance. In this work, we argue that test-time data hold great information that can be leveraged in a self supervised manner to refresh the model's memory of previous learned tasks and hence greatly reduce forgetting at no extra labelling cost. We study how unsupervised data can be employed online to improve models' performance on prior tasks upon encountering representative samples. We propose a simple yet effective student-teacher model with gradient based sparse parameters updates and show significant performance improvements and reduction in forgetting, which could alleviate the role of an offline episodic memory/experience replay buffer.
6/21/2024
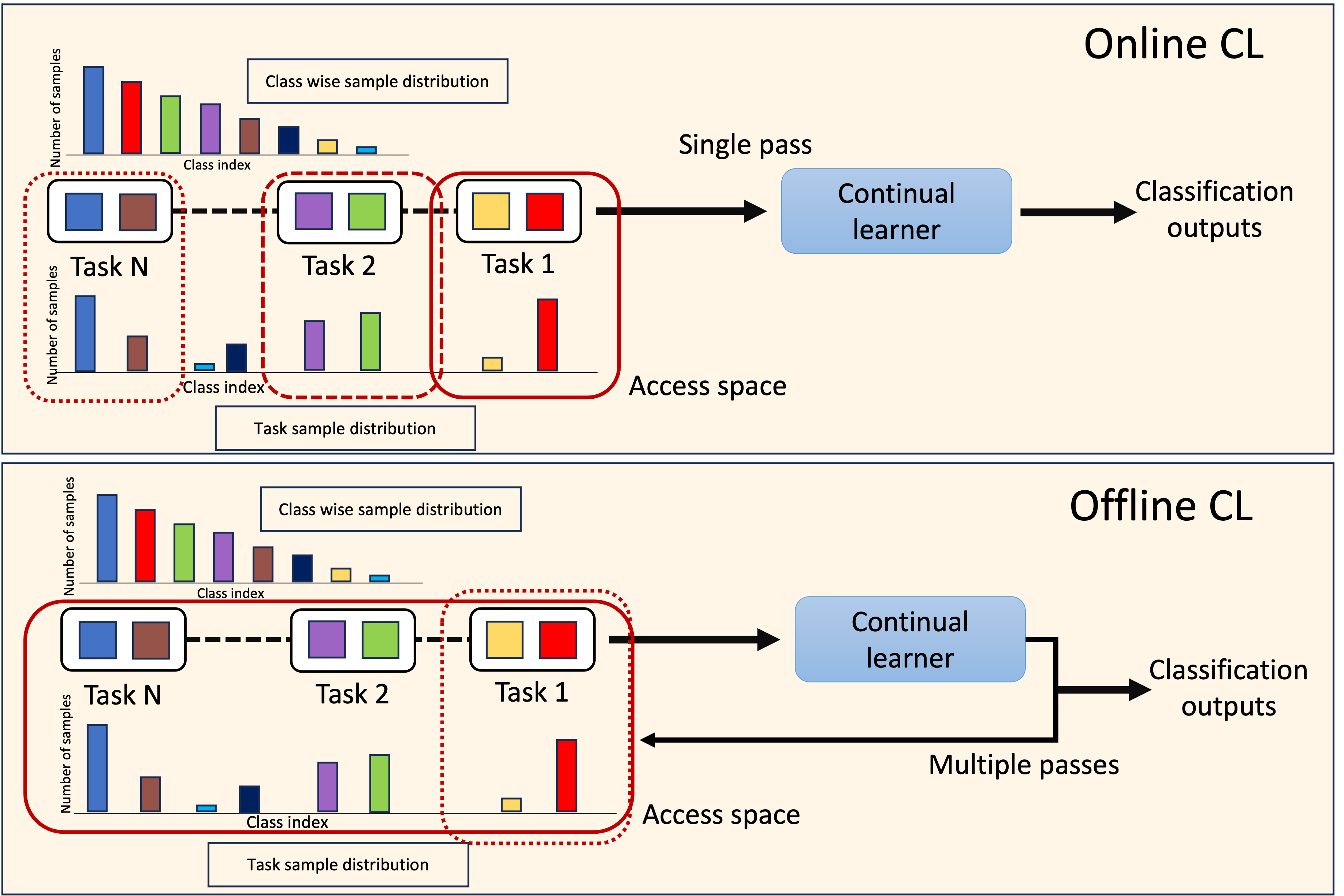
DELTA: Decoupling Long-Tailed Online Continual Learning
Siddeshwar Raghavan, Jiangpeng He, Fengqing Zhu
0
0
A significant challenge in achieving ubiquitous Artificial Intelligence is the limited ability of models to rapidly learn new information in real-world scenarios where data follows long-tailed distributions, all while avoiding forgetting previously acquired knowledge. In this work, we study the under-explored problem of Long-Tailed Online Continual Learning (LTOCL), which aims to learn new tasks from sequentially arriving class-imbalanced data streams. Each data is observed only once for training without knowing the task data distribution. We present DELTA, a decoupled learning approach designed to enhance learning representations and address the substantial imbalance in LTOCL. We enhance the learning process by adapting supervised contrastive learning to attract similar samples and repel dissimilar (out-of-class) samples. Further, by balancing gradients during training using an equalization loss, DELTA significantly enhances learning outcomes and successfully mitigates catastrophic forgetting. Through extensive evaluation, we demonstrate that DELTA improves the capacity for incremental learning, surpassing existing OCL methods. Our results suggest considerable promise for applying OCL in real-world applications.
4/9/2024

Online Cascade Learning for Efficient Inference over Streams
Lunyiu Nie, Zhimin Ding, Erdong Hu, Christopher Jermaine, Swarat Chaudhuri
0
0
Large Language Models (LLMs) have a natural role in answering complex queries about data streams, but the high computational cost of LLM inference makes them infeasible in many such tasks. We propose online cascade learning, the first approach to address this challenge. The objective here is to learn a cascade of models, starting with lower-capacity models (such as logistic regression) and ending with a powerful LLM, along with a deferral policy that determines the model to be used on a given input. We formulate the task of learning cascades online as an imitation-learning problem, where smaller models are updated over time imitating the collected LLM demonstrations, and give a no-regret algorithm for the problem. Experimental results across four benchmarks show that our method parallels LLMs in accuracy while cutting down inference costs by as much as 90% with strong robustness against input distribution shifts, underscoring its efficacy and adaptability in stream processing.
6/19/2024

Continual Learning on a Diet: Learning from Sparsely Labeled Streams Under Constrained Computation
Wenxuan Zhang, Youssef Mohamed, Bernard Ghanem, Philip H. S. Torr, Adel Bibi, Mohamed Elhoseiny
0
0
We propose and study a realistic Continual Learning (CL) setting where learning algorithms are granted a restricted computational budget per time step while training. We apply this setting to large-scale semi-supervised Continual Learning scenarios with sparse label rates. Previous proficient CL methods perform very poorly in this challenging setting. Overfitting to the sparse labeled data and insufficient computational budget are the two main culprits for such a poor performance. Our new setting encourages learning methods to effectively and efficiently utilize the unlabeled data during training. To that end, we propose a simple but highly effective baseline, DietCL, which utilizes both unlabeled and labeled data jointly. DietCL meticulously allocates computational budget for both types of data. We validate our baseline, at scale, on several datasets, e.g., CLOC, ImageNet10K, and CGLM, under constraint budget setups. DietCL outperforms, by a large margin, all existing supervised CL algorithms as well as more recent continual semi-supervised methods. Our extensive analysis and ablations demonstrate that DietCL is stable under a full spectrum of label sparsity, computational budget, and various other ablations.
6/11/2024