LaMI-DETR: Open-Vocabulary Detection with Language Model Instruction

0
Sign in to get full access
Overview
- The paper presents LaMI-DETR, a novel object detection model that leverages language model instruction to enable open-vocabulary detection.
- LaMI-DETR extends the DETR (Detr transformer) architecture to go beyond fixed object categories and detect any object described in natural language.
- The model demonstrates strong performance on challenging open-vocabulary detection benchmarks, outperforming previous state-of-the-art approaches.
Plain English Explanation
LaMI-DETR is a new object detection model that can identify any object, not just a fixed set of pre-defined categories. Unlike traditional object detectors that are limited to a predefined vocabulary, LaMI-DETR can detect objects described in natural language, such as "a blue truck" or "a person riding a bicycle."
This is achieved by combining DETR, a powerful object detection transformer, with language model instruction. The language model allows the system to understand and reason about the natural language descriptions of objects, enabling it to detect a much broader range of items compared to standard object detectors.
The key innovation of LaMI-DETR is its ability to learn from language instructions, which gives it the flexibility to identify a wide variety of objects without being constrained to a fixed set of categories. This makes the model more versatile and applicable to real-world scenarios where the objects of interest may not be known in advance.
The researchers demonstrate that LaMI-DETR outperforms previous state-of-the-art open-vocabulary detection approaches on challenging benchmark tasks. This suggests that the integration of language model instruction with the DETR architecture is a promising direction for building more capable and adaptable object detection systems.
Technical Explanation
The paper introduces LaMI-DETR, which builds on the DETR (Detr transformer) [https://aimodels.fyi/papers/arxiv/ovlw-detr-open-vocabulary-light-weighted-detection] object detection architecture by incorporating language model instruction. This allows the model to perform open-vocabulary detection, going beyond the fixed object categories typically used in object detection tasks.
The core idea is to leverage a pre-trained language model to understand and reason about natural language descriptions of objects, enabling the detection of a much broader range of items compared to standard object detectors. The language model is integrated with the DETR transformer-based detection backbone, allowing the model to learn from language instructions during training and apply this knowledge to detect novel objects at inference time.
The researchers evaluate LaMI-DETR on several challenging open-vocabulary detection benchmarks, including [https://aimodels.fyi/papers/arxiv/open-vocabulary-multi-label-video-classification], [https://aimodels.fyi/papers/arxiv/ov-dquo-open-vocabulary-detr-denoising-text], and [https://aimodels.fyi/papers/arxiv/unlocking-textual-visual-wisdom-open-vocabulary-3d]. The results demonstrate that LaMI-DETR outperforms previous state-of-the-art approaches, highlighting the effectiveness of the language model instruction approach for open-vocabulary object detection.
Critical Analysis
The paper presents a promising direction for open-vocabulary object detection, but it is important to note some potential limitations and areas for further research:
-
The performance of LaMI-DETR is still constrained by the capabilities of the underlying language model, which may struggle with rare or complex object descriptions. Exploring ways to improve the language understanding capabilities, such as using larger or more specialized language models, could further enhance the system's performance.
-
The paper focuses on object detection in static images, but extending the approach to video or 3D data [https://aimodels.fyi/papers/arxiv/unlocking-textual-visual-wisdom-open-vocabulary-3d] could broaden the practical applications of the model.
-
While LaMI-DETR demonstrates strong results on benchmarks, it would be valuable to assess the model's performance in real-world scenarios with diverse and potentially noisy data, as well as its robustness to adversarial attacks or distributional shift.
-
The scalability and computational efficiency of the LaMI-DETR architecture could be further investigated, especially as the size and complexity of language models continue to grow [https://aimodels.fyi/papers/arxiv/exploring-potential-large-foundation-models-open-vocabulary].
Overall, the LaMI-DETR approach represents an exciting step forward in open-vocabulary object detection, and the research community should continue to explore ways to build more versatile and adaptable vision-language systems.
Conclusion
The LaMI-DETR model presented in this paper is a significant advancement in open-vocabulary object detection, addressing the limitations of traditional object detectors that are confined to a fixed set of categories. By integrating language model instruction with the DETR architecture, the researchers have enabled a more flexible and adaptable detection system that can identify a wide range of objects described in natural language.
The strong performance of LaMI-DETR on challenging benchmarks suggests that this approach holds promise for real-world applications where the objects of interest may not be known in advance. As the field of vision-language understanding continues to evolve, the integration of powerful language models with advanced object detection frameworks, as demonstrated by LaMI-DETR, could lead to even more capable and versatile visual recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LaMI-DETR: Open-Vocabulary Detection with Language Model Instruction
Penghui Du, Yu Wang, Yifan Sun, Luting Wang, Yue Liao, Gang Zhang, Errui Ding, Yan Wang, Jingdong Wang, Si Liu
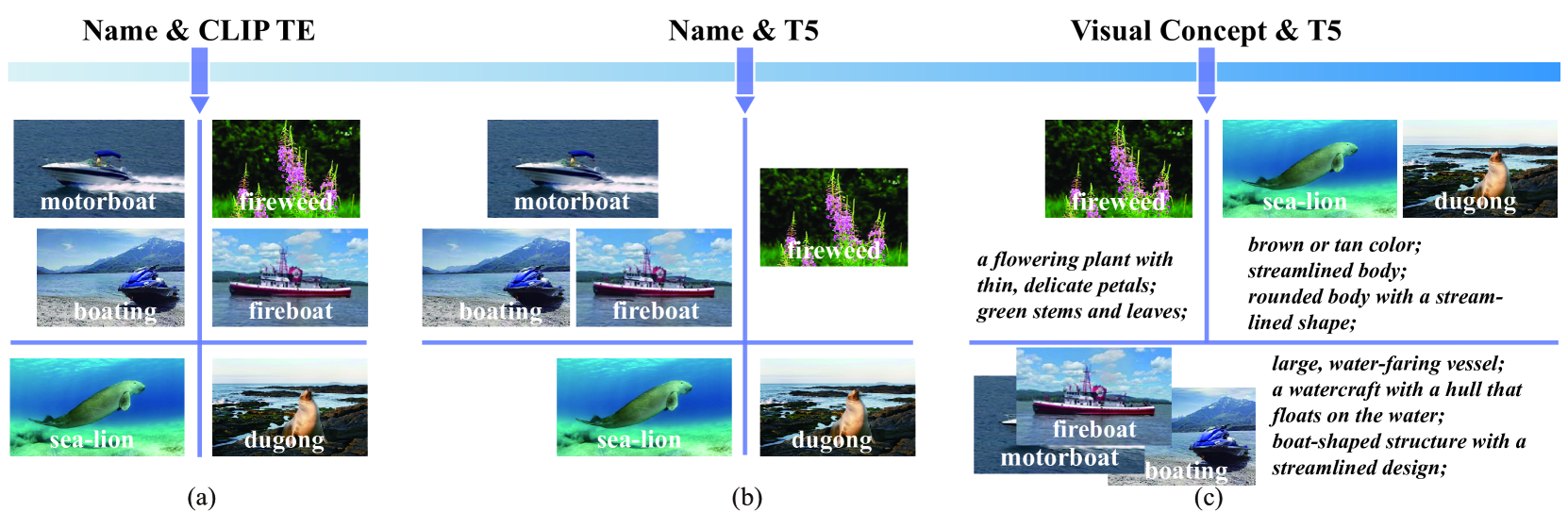
Existing methods enhance open-vocabulary object detection by leveraging the robust open-vocabulary recognition capabilities of Vision-Language Models (VLMs), such as CLIP.However, two main challenges emerge:(1) A deficiency in concept representation, where the category names in CLIP's text space lack textual and visual knowledge.(2) An overfitting tendency towards base categories, with the open vocabulary knowledge biased towards base categories during the transfer from VLMs to detectors.To address these challenges, we propose the Language Model Instruction (LaMI) strategy, which leverages the relationships between visual concepts and applies them within a simple yet effective DETR-like detector, termed LaMI-DETR.LaMI utilizes GPT to construct visual concepts and employs T5 to investigate visual similarities across categories.These inter-category relationships refine concept representation and avoid overfitting to base categories.Comprehensive experiments validate our approach's superior performance over existing methods in the same rigorous setting without reliance on external training resources.LaMI-DETR achieves a rare box AP of 43.4 on OV-LVIS, surpassing the previous best by 7.8 rare box AP.
Read more7/19/2024

0
OVLW-DETR: Open-Vocabulary Light-Weighted Detection Transformer
Yu Wang, Xiangbo Su, Qiang Chen, Xinyu Zhang, Teng Xi, Kun Yao, Errui Ding, Gang Zhang, Jingdong Wang
Open-vocabulary object detection focusing on detecting novel categories guided by natural language. In this report, we propose Open-Vocabulary Light-Weighted Detection Transformer (OVLW-DETR), a deployment friendly open-vocabulary detector with strong performance and low latency. Building upon OVLW-DETR, we provide an end-to-end training recipe that transferring knowledge from vision-language model (VLM) to object detector with simple alignment. We align detector with the text encoder from VLM by replacing the fixed classification layer weights in detector with the class-name embeddings extracted from the text encoder. Without additional fusing module, OVLW-DETR is flexible and deployment friendly, making it easier to implement and modulate. improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time open-vocabulary detectors on standard Zero-Shot LVIS benchmark. Source code and pre-trained models are available at [https://github.com/Atten4Vis/LW-DETR].
Read more7/16/2024

0
TaskCLIP: Extend Large Vision-Language Model for Task Oriented Object Detection
Hanning Chen, Wenjun Huang, Yang Ni, Sanggeon Yun, Yezi Liu, Fei Wen, Alvaro Velasquez, Hugo Latapie, Mohsen Imani
Task-oriented object detection aims to find objects suitable for accomplishing specific tasks. As a challenging task, it requires simultaneous visual data processing and reasoning under ambiguous semantics. Recent solutions are mainly all-in-one models. However, the object detection backbones are pre-trained without text supervision. Thus, to incorporate task requirements, their intricate models undergo extensive learning on a highly imbalanced and scarce dataset, resulting in capped performance, laborious training, and poor generalizability. In contrast, we propose TaskCLIP, a more natural two-stage design composed of general object detection and task-guided object selection. Particularly for the latter, we resort to the recently successful large Vision-Language Models (VLMs) as our backbone, which provides rich semantic knowledge and a uniform embedding space for images and texts. Nevertheless, the naive application of VLMs leads to sub-optimal quality, due to the misalignment between embeddings of object images and their visual attributes, which are mainly adjective phrases. To this end, we design a transformer-based aligner after the pre-trained VLMs to re-calibrate both embeddings. Finally, we employ a trainable score function to post-process the VLM matching results for object selection. Experimental results demonstrate that our TaskCLIP outperforms the state-of-the-art DETR-based model TOIST by 3.5% and only requires a single NVIDIA RTX 4090 for both training and inference.
Read more9/9/2024

0
OVA-DETR: Open Vocabulary Aerial Object Detection Using Image-Text Alignment and Fusion
Guoting Wei, Xia Yuan, Yu Liu, Zhenhao Shang, Kelu Yao, Chao Li, Qingsen Yan, Chunxia Zhao, Haokui Zhang, Rong Xiao
Aerial object detection has been a hot topic for many years due to its wide application requirements. However, most existing approaches can only handle predefined categories, which limits their applicability for the open scenarios in real-world. In this paper, we extend aerial object detection to open scenarios by exploiting the relationship between image and text, and propose OVA-DETR, a high-efficiency open-vocabulary detector for aerial images. Specifically, based on the idea of image-text alignment, we propose region-text contrastive loss to replace the category regression loss in the traditional detection framework, which breaks the category limitation. Then, we propose Bidirectional Vision-Language Fusion (Bi-VLF), which includes a dual-attention fusion encoder and a multi-level text-guided Fusion Decoder. The dual-attention fusion encoder enhances the feature extraction process in the encoder part. The multi-level text-guided Fusion Decoder is designed to improve the detection ability for small objects, which frequently appear in aerial object detection scenarios. Experimental results on three widely used benchmark datasets show that our proposed method significantly improves the mAP and recall, while enjoying faster inference speed. For instance, in zero shot detection experiments on DIOR, the proposed OVA-DETR outperforms DescReg and YOLO-World by 37.4% and 33.1%, respectively, while achieving 87 FPS inference speed, which is 7.9x faster than DescReg and 3x faster than YOLO-world. The code is available at https://github.com/GT-Wei/OVA-DETR.
Read more8/23/2024