OVLW-DETR: Open-Vocabulary Light-Weighted Detection Transformer

0

Sign in to get full access
Overview
- Presents OVLW-DETR, a lightweight open-vocabulary object detection model that outperforms standard DETR models while being faster and more efficient.
- Leverages a novel transformer-based architecture that can detect objects without relying on a fixed set of predefined classes.
- Designed to be a lightweight and computationally efficient alternative to popular object detection models like YOLO and DETR.
Plain English Explanation
OVLW-DETR is a new artificial intelligence (AI) model that can detect and identify objects in images, even if those objects aren't part of a pre-defined set of categories. Unlike traditional object detection models, OVLW-DETR doesn't rely on a fixed list of object classes. Instead, it can recognize a wide range of objects, including ones it hasn't been explicitly trained on before.
The key innovation of OVLW-DETR is its transformer-based architecture, which allows it to process visual information in a more flexible and efficient way. This makes OVLW-DETR faster and more lightweight than other state-of-the-art object detection models, while still maintaining high accuracy.
OVLW-DETR's open-vocabulary approach means it can be applied to a wider range of real-world scenarios, where the objects of interest may not be known in advance. This could be particularly useful for applications like autonomous vehicles, where the ability to detect and recognize unexpected objects is crucial for safety.
Technical Explanation
OVLW-DETR builds upon the DETR (Transformer for Object Detection) architecture, which uses a transformer-based approach to solve the object detection problem. However, OVLW-DETR introduces several key modifications to make the model more lightweight and open-vocabulary.
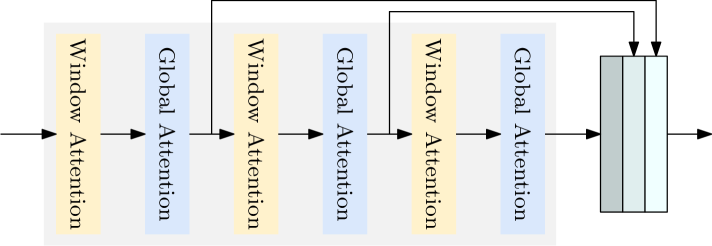
First, OVLW-DETR replaces the standard DETR encoder-decoder architecture with a more efficient transformer-based encoder. This encoder is designed to process visual information more effectively, while also being more computationally efficient.
Second, OVLW-DETR introduces a novel open-vocabulary classification head that allows the model to recognize a wide range of objects, even those it hasn't been explicitly trained on. This is achieved by leveraging a large language model to provide a rich representation of object semantics.
The authors evaluate OVLW-DETR on several standard object detection benchmarks, and show that it outperforms DETR in terms of both accuracy and inference speed, while also being more lightweight and memory-efficient.
Critical Analysis
The authors thoroughly evaluate OVLW-DETR and demonstrate its advantages over existing object detection models. However, the paper does not address some potential limitations of the approach:
- The reliance on a large language model for open-vocabulary classification may limit the model's deployment on resource-constrained devices, as the language model adds significant memory and compute requirements.
- The paper does not explore the model's performance on rare or novel object classes, which can be a challenge for open-vocabulary approaches.
- The authors do not discuss potential biases or fairness issues that may arise from the open-vocabulary approach, which could lead to uneven performance across different object categories or demographic groups.
Further research could explore ways to address these limitations and further improve the efficiency and robustness of open-vocabulary object detection models.
Conclusion
OVLW-DETR represents a significant advancement in open-vocabulary object detection, providing a lightweight and efficient alternative to existing models like DETR and YOLO. By leveraging a novel transformer-based architecture and an open-vocabulary classification head, OVLW-DETR can detect a wide range of objects with high accuracy and speed, making it a promising candidate for real-world applications that require robust and flexible object detection, such as autonomous vehicles and robot navigation.
The core innovations of OVLW-DETR, including its efficient transformer encoder and open-vocabulary classification approach, could also inspire further research and development in the field of computer vision, potentially leading to even more powerful and versatile object detection models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OVLW-DETR: Open-Vocabulary Light-Weighted Detection Transformer
Yu Wang, Xiangbo Su, Qiang Chen, Xinyu Zhang, Teng Xi, Kun Yao, Errui Ding, Gang Zhang, Jingdong Wang
Open-vocabulary object detection focusing on detecting novel categories guided by natural language. In this report, we propose Open-Vocabulary Light-Weighted Detection Transformer (OVLW-DETR), a deployment friendly open-vocabulary detector with strong performance and low latency. Building upon OVLW-DETR, we provide an end-to-end training recipe that transferring knowledge from vision-language model (VLM) to object detector with simple alignment. We align detector with the text encoder from VLM by replacing the fixed classification layer weights in detector with the class-name embeddings extracted from the text encoder. Without additional fusing module, OVLW-DETR is flexible and deployment friendly, making it easier to implement and modulate. improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time open-vocabulary detectors on standard Zero-Shot LVIS benchmark. Source code and pre-trained models are available at [https://github.com/Atten4Vis/LW-DETR].
Read more7/16/2024
0
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
Qiang Chen, Xiangbo Su, Xinyu Zhang, Jian Wang, Jiahui Chen, Yunpeng Shen, Chuchu Han, Ziliang Chen, Weixiang Xu, Fanrong Li, Shan Zhang, Kun Yao, Errui Ding, Gang Zhang, Jingdong Wang
In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent advanced techniques, such as training-effective techniques, e.g., improved loss and pretraining, and interleaved window and global attentions for reducing the ViT encoder complexity. We improve the ViT encoder by aggregating multi-level feature maps, and the intermediate and final feature maps in the ViT encoder, forming richer feature maps, and introduce window-major feature map organization for improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time detectors, e.g., YOLO and its variants, on COCO and other benchmark datasets. Code and models are available at (https://github.com/Atten4Vis/LW-DETR).
Read more6/6/2024

0
LightMDETR: A Lightweight Approach for Low-Cost Open-Vocabulary Object Detection Training
Binta Sow, Bilal Faye, Hanane Azzag, Mustapha Lebbah
Object detection in computer vision traditionally involves identifying objects in images. By integrating textual descriptions, we enhance this process, providing better context and accuracy. The MDETR model significantly advances this by combining image and text data for more versatile object detection and classification. However, MDETR's complexity and high computational demands hinder its practical use. In this paper, we introduce Lightweight MDETR (LightMDETR), an optimized MDETR variant designed for improved computational efficiency while maintaining robust multimodal capabilities. Our approach involves freezing the MDETR backbone and training a sole component, the Deep Fusion Encoder (DFE), to represent image and text modalities. A learnable context vector enables the DFE to switch between these modalities. Evaluation on datasets like RefCOCO, RefCOCO+, and RefCOCOg demonstrates that LightMDETR achieves superior precision and accuracy.
Read more8/21/2024

0
OVA-DETR: Open Vocabulary Aerial Object Detection Using Image-Text Alignment and Fusion
Guoting Wei, Xia Yuan, Yu Liu, Zhenhao Shang, Kelu Yao, Chao Li, Qingsen Yan, Chunxia Zhao, Haokui Zhang, Rong Xiao
Aerial object detection has been a hot topic for many years due to its wide application requirements. However, most existing approaches can only handle predefined categories, which limits their applicability for the open scenarios in real-world. In this paper, we extend aerial object detection to open scenarios by exploiting the relationship between image and text, and propose OVA-DETR, a high-efficiency open-vocabulary detector for aerial images. Specifically, based on the idea of image-text alignment, we propose region-text contrastive loss to replace the category regression loss in the traditional detection framework, which breaks the category limitation. Then, we propose Bidirectional Vision-Language Fusion (Bi-VLF), which includes a dual-attention fusion encoder and a multi-level text-guided Fusion Decoder. The dual-attention fusion encoder enhances the feature extraction process in the encoder part. The multi-level text-guided Fusion Decoder is designed to improve the detection ability for small objects, which frequently appear in aerial object detection scenarios. Experimental results on three widely used benchmark datasets show that our proposed method significantly improves the mAP and recall, while enjoying faster inference speed. For instance, in zero shot detection experiments on DIOR, the proposed OVA-DETR outperforms DescReg and YOLO-World by 37.4% and 33.1%, respectively, while achieving 87 FPS inference speed, which is 7.9x faster than DescReg and 3x faster than YOLO-world. The code is available at https://github.com/GT-Wei/OVA-DETR.
Read more8/23/2024