LaMP: When Large Language Models Meet Personalization

0
💬
Sign in to get full access
Overview
- This paper introduces the LaMP (Large Language Model Personalization) benchmark, a new evaluation framework for testing how well large language models can produce personalized outputs.
- LaMP includes a diverse set of language tasks, such as text classification and generation, that are tailored to different user profiles.
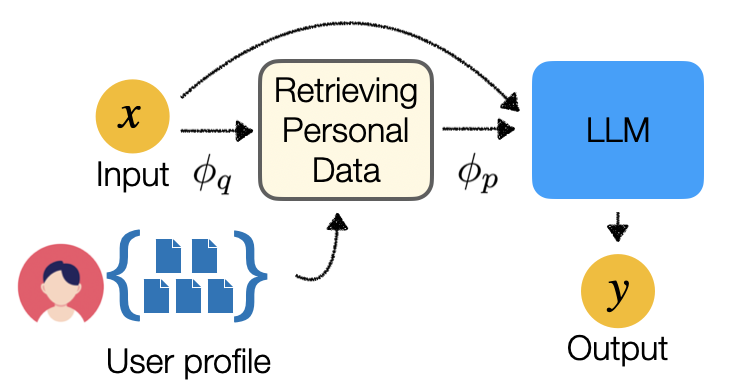
- The paper also proposes two retrieval-based approaches to augment language models with personal information from user profiles, improving their ability to generate personalized text.
Plain English Explanation
The paper focuses on the importance of personalization in large language models - AI systems that can understand and generate human-like text. Personalization in Large Language Models is crucial because it allows these models to tailor their outputs to individual users, making the interactions more relevant and useful.
The researchers created the LaMP benchmark to evaluate how well language models can handle personalized tasks. LaMP includes a variety of tests, like classifying text and generating responses, that are customized for different user profiles. This helps measure a model's ability to understand and respond in a personalized way.
The paper also introduces two approaches to improve personalization. These methods retrieve relevant personal information from user profiles and use it to shape the language model's outputs. For example, if the model knows a user's interests, it can generate text that is more tailored to that person. Personal Large Language Models for Mobile Devices and LLM-Rec: Personalized Recommendation via Prompting Large Language Models are examples of how this personalization can be applied.
The researchers found that these retrieval-based approaches can significantly boost a language model's performance on the personalized tasks in the LaMP benchmark. This highlights the value of personalization in making language models more effective and useful for individual users.
Technical Explanation
The paper introduces the LaMP (Large Language Model Personalization) benchmark, a comprehensive evaluation framework for assessing the personalization capabilities of large language models. LaMP consists of seven personalized tasks, including three text classification tasks (sentiment analysis, question answering, and topic classification) and four text generation tasks (summarization, dialogue, story completion, and recipe generation).
Each task in LaMP is tailored to different user profiles, allowing the benchmark to measure how well language models can adapt their outputs to individual preferences and characteristics. The researchers also propose two retrieval-based approaches to augment language models with personal information from user profiles:
-
Doing Personal LAPs: LLM-Augmented Dialogue Construction - This method retrieves relevant personal information (e.g., interests, hobbies, background) from user profiles and uses it to guide the language model's dialogue generation.
-
LLM-Rec: Personalized Recommendation via Prompting Large Language Models - This approach retrieves personalized items (e.g., books, movies, products) from user profiles and incorporates them into the language model's prompts to generate more tailored recommendations.
The researchers evaluated these retrieval augmentation methods on zero-shot and fine-tuned language models, demonstrating their effectiveness in improving performance on the personalized tasks in the LaMP benchmark. The results highlight the importance of personalization in natural language processing and the potential for leveraging personal information to enhance the capabilities of large language models.
Critical Analysis
The paper presents a well-designed and comprehensive benchmark for evaluating personalization in large language models. The inclusion of diverse language tasks and multiple user profiles in the LaMP benchmark provides a robust framework for assessing a model's ability to generate personalized outputs.
One potential limitation of the paper is that the proposed retrieval-based approaches rely on the availability of structured user profiles, which may not always be the case in real-world scenarios. The researchers could have explored methods for inferring personal information from more unstructured sources, such as a user's online behavior or communication history.
Additionally, the paper does not discuss the potential privacy and ethical concerns related to the use of personal data in language models. As these models become more widely adopted, it will be crucial to address issues around data privacy, consent, and the responsible use of personal information.
Further research could investigate the long-term effects of personalization on language model behavior, such as the potential for biases or echo chambers to emerge. It would also be valuable to explore how personalization approaches could be combined with other techniques, such as optimization methods for personalizing large language models or personal large language models for mobile devices, to create even more effective and personalized language models.
Conclusion
This paper highlights the importance of personalization in large language models and introduces the LaMP benchmark, a novel evaluation framework for assessing a model's ability to generate personalized outputs. The researchers also propose two retrieval-based approaches to augment language models with personal information, demonstrating the effectiveness of this approach on a range of personalized language tasks.
The findings underscore the value of personalization in making language models more relevant and useful for individual users. As large language models become more ubiquitous, the ability to tailor their outputs to individual preferences and characteristics will be crucial for creating more natural and engaging interactions. The LaMP benchmark and the proposed personalization techniques provide a valuable foundation for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
LaMP: When Large Language Models Meet Personalization
Alireza Salemi, Sheshera Mysore, Michael Bendersky, Hamed Zamani
This paper highlights the importance of personalization in large language models and introduces the LaMP benchmark -- a novel benchmark for training and evaluating language models for producing personalized outputs. LaMP offers a comprehensive evaluation framework with diverse language tasks and multiple entries for each user profile. It consists of seven personalized tasks, spanning three text classification and four text generation tasks. We additionally propose two retrieval augmentation approaches that retrieve personal items from each user profile for personalizing language model outputs. To this aim, we study various retrieval models, including term matching, semantic matching, and time-aware methods. Extensive experiments on LaMP for zero-shot and fine-tuned language models demonstrate the efficacy of the proposed retrieval augmentation approach and highlight the impact of personalization in various natural language tasks.
Read more6/6/2024

0
LongLaMP: A Benchmark for Personalized Long-form Text Generation
Ishita Kumar, Snigdha Viswanathan, Sushrita Yerra, Alireza Salemi, Ryan A. Rossi, Franck Dernoncourt, Hanieh Deilamsalehy, Xiang Chen, Ruiyi Zhang, Shubham Agarwal, Nedim Lipka, Hamed Zamani
Long-text generation is seemingly ubiquitous in real-world applications of large language models such as generating an email or writing a review. Despite the fundamental importance and prevalence of long-text generation in many practical applications, existing work on personalized generation has focused on the generation of very short text. To overcome these limitations, we study the problem of personalized long-text generation, that is, generating long-text that is personalized for a specific user while being practically useful for the vast majority of real-world applications that naturally require the generation of longer text. In this work, we demonstrate the importance of user-specific personalization for long-text generation tasks and develop the Long-text Language Model Personalization (LongLaMP) Benchmark. LongLaMP provides a comprehensive and diverse evaluation framework for personalized long-text generation. Extensive experiments on LongLaMP for zero-shot and fine-tuned language tasks demonstrate the effectiveness of the proposed benchmark and its utility for developing and evaluating techniques for personalized long-text generation across a wide variety of long-text generation tasks. The results highlight the importance of personalization across a wide variety of long-text generation tasks. Finally, we release the benchmark for others to use for this important problem.
Read more7/17/2024
0
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Alireza Salemi, Surya Kallumadi, Hamed Zamani
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
Read more4/10/2024

0
LLaMP: Large Language Model Made Powerful for High-fidelity Materials Knowledge Retrieval and Distillation
Yuan Chiang, Elvis Hsieh, Chia-Hong Chou, Janosh Riebesell
Reducing hallucination of Large Language Models (LLMs) is imperative for use in the sciences, where reliability and reproducibility are crucial. However, LLMs inherently lack long-term memory, making it a nontrivial, ad hoc, and inevitably biased task to fine-tune them on domain-specific literature and data. Here we introduce LLaMP, a multimodal retrieval-augmented generation (RAG) framework of hierarchical reasoning-and-acting (ReAct) agents that can dynamically and recursively interact with computational and experimental data on Materials Project (MP) and run atomistic simulations via high-throughput workflow interface. Without fine-tuning, LLaMP demonstrates strong tool usage ability to comprehend and integrate various modalities of materials science concepts, fetch relevant data stores on the fly, process higher-order data (such as crystal structure and elastic tensor), and streamline complex tasks in computational materials and chemistry. We propose a simple metric combining uncertainty and confidence estimates to evaluate the self-consistency of responses by LLaMP and vanilla LLMs. Our benchmark shows that LLaMP effectively mitigates the intrinsic bias in LLMs, counteracting the errors on bulk moduli, electronic bandgaps, and formation energies that seem to derive from mixed data sources. We also demonstrate LLaMP's capability to edit crystal structures and run annealing molecular dynamics simulations using pre-trained machine-learning force fields. The framework offers an intuitive and nearly hallucination-free approach to exploring and scaling materials informatics, and establishes a pathway for knowledge distillation and fine-tuning other language models. Code and live demo are available at https://github.com/chiang-yuan/llamp
Read more6/4/2024