PLMM: Personal Large Language Models on Mobile Devices

0
💬
Sign in to get full access
Overview
- This paper proposes "personal large models" - language models that are customized to individual users' personal information like education and hobbies.
- The models are classified into three levels: personal, expert, and traditional.
- Personal models are adaptive to users' private data, encrypt their inputs, and run on personal devices.
- Expert models focus on specific domains like finance or art, while traditional models handle general knowledge and upgrade the expert models.
- The personal models directly interact with users and must be small, fast, and high-quality.
- These models could be applied to a variety of language and vision tasks.
Plain English Explanation
The researchers were inspired by Federated Learning, a technique that trains AI models using data distributed across many devices. They wanted to create large language models that are customized to individual users rather than being one-size-fits-all.
These "personal large models" would have three levels. The personal level models would adapt to each user's unique information like their education and hobbies. They would encrypt the user's input to protect their privacy, and they would need to be small enough to run on personal computers or phones. The expert level models would focus on specific domains like finance or art, merging that specialized knowledge. And the traditional level models would handle general knowledge and upgrade the expert models over time.
The key idea is that the personal models would directly interact with users, using their private data to provide a highly customized experience. The models would need to be fast and high-quality to give users a good experience. The researchers believe these types of personalized models could be useful for all kinds of language and vision tasks.
Technical Explanation
The paper proposes a framework for "personal large models" that are customized to individual users' personal information, in contrast to traditional large language models that aim for universal knowledge.
The models are classified into three levels:
-
Personal level: These models are adaptive to users' private data like education and hobbies. They encrypt user inputs to protect privacy and must be small enough to run on personal devices. They directly interact with users and need to be fast and high-quality.
-
Expert level: These models focus on merging specialized knowledge in domains like finance, IT, or art.
-
Traditional level: These models handle general knowledge discovery and upgrading the expert models over time.
The personal models sit at the interface with users, utilizing their encrypted private data to provide a highly customized experience. This personalization is inspired by Federated Learning techniques.
The researchers envision these personal large models being useful for a variety of language and vision tasks, education applications, recommender systems, and more. The key challenges are ensuring the personal models are small, fast, high-quality, and able to protect user privacy.
Critical Analysis
The paper presents an interesting framework for personalized large language models, but there are some potential limitations and areas for further research:
-
The authors do not provide details on how the personal models would actually adapt to individual users' data in practice. More specifics on the adaptation and personalization mechanisms would be helpful.
-
Privacy protection is a key concern, but the paper does not explore potential vulnerabilities or attack vectors for the encrypted user data. Rigorous security analysis would be important.
-
Scaling the expert-level models to many specialized domains could be challenging, and the paper does not address how to efficiently manage and update this knowledge base.
-
The computational and memory requirements of running multiple personalized models on end-user devices may be prohibitive, requiring further research into model compression and efficient deployment.
Overall, the proposed framework is an intriguing direction for advancing personalized AI, but significant technical challenges remain to be solved before such personal large models could be widely deployed.
Conclusion
This paper introduces the concept of "personal large models" - large language models that are customized and adapted to individual users' personal information and preferences. By classifying the models into personal, expert, and traditional levels, the researchers aim to create highly personalized AI assistants that can protect user privacy, leverage specialized knowledge, and provide a fast, high-quality user experience.
While the ideas presented are promising, there are still many open questions and challenges to address around the technical implementation, security, and scalability of such personalized large models. Further research is needed to bring this vision of adaptive, privacy-preserving AI into reality. Nevertheless, this work represents an interesting step towards more tailored and user-centric language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
PLMM: Personal Large Language Models on Mobile Devices
Yuanhao Gong
Inspired by Federated Learning, in this paper, we propose personal large models that are distilled from traditional large language models but more adaptive to local users' personal information such as education background and hobbies. We classify the large language models into three levels: the personal level, expert level and traditional level. The personal level models are adaptive to users' personal information. They encrypt the users' input and protect their privacy. The expert level models focus on merging specific knowledge such as finance, IT and art. The traditional models focus on the universal knowledge discovery and upgrading the expert models. In such classifications, the personal models directly interact with the user. For the whole system, the personal models have users' (encrypted) personal information. Moreover, such models must be small enough to be performed on personal computers or mobile devices. Finally, they also have to response in real-time for better user experience and produce high quality results. The proposed personal large models can be applied in a wide range of applications such as language and vision tasks.
Read more5/7/2024

0
Large Language Models: A New Approach for Privacy Policy Analysis at Scale
David Rodriguez, Ian Yang, Jose M. Del Alamo, Norman Sadeh
The number and dynamic nature of web and mobile applications presents significant challenges for assessing their compliance with data protection laws. In this context, symbolic and statistical Natural Language Processing (NLP) techniques have been employed for the automated analysis of these systems' privacy policies. However, these techniques typically require labor-intensive and potentially error-prone manually annotated datasets for training and validation. This research proposes the application of Large Language Models (LLMs) as an alternative for effectively and efficiently extracting privacy practices from privacy policies at scale. Particularly, we leverage well-known LLMs such as ChatGPT and Llama 2, and offer guidance on the optimal design of prompts, parameters, and models, incorporating advanced strategies such as few-shot learning. We further illustrate its capability to detect detailed and varied privacy practices accurately. Using several renowned datasets in the domain as a benchmark, our evaluation validates its exceptional performance, achieving an F1 score exceeding 93%. Besides, it does so with reduced costs, faster processing times, and fewer technical knowledge requirements. Consequently, we advocate for LLM-based solutions as a sound alternative to traditional NLP techniques for the automated analysis of privacy policies at scale.
Read more6/3/2024
💬
0
Leveraging Large Language Models for enhanced personalised user experience in Smart Homes
Jordan Rey-Jouanchicot (IRIT-ELIPSE, LAAS), Andr'e Bottaro (LAAS-S4M), Eric Campo (LAAS-S4M), Jean-L'eon Bouraoui (IRIT-ELIPSE), Nadine Vigouroux (IRIT-ELIPSE), Fr'ed'eric Vella (IRIT-ELIPSE)
Smart home automation systems aim to improve the comfort and convenience of users in their living environment. However, adapting automation to user needs remains a challenge. Indeed, many systems still rely on hand-crafted routines for each smart object.This paper presents an original smart home architecture leveraging Large Language Models (LLMs) and user preferences to push the boundaries of personalisation and intuitiveness in the home environment.This article explores a human-centred approach that uses the general knowledge provided by LLMs to learn and facilitate interactions with the environment.The advantages of the proposed model are demonstrated on a set of scenarios, as well as a comparative analysis with various LLM implementations. Some metrics are assessed to determine the system's ability to maintain comfort, safety, and user preferences. The paper details the approach to real-world implementation and evaluation.The proposed approach of using preferences shows up to 52.3% increase in average grade, and with an average processing time reduced by 35.6% on Starling 7B Alpha LLM. In addition, performance is 26.4% better than the results of the larger models without preferences, with processing time almost 20 times faster.
Read more7/18/2024
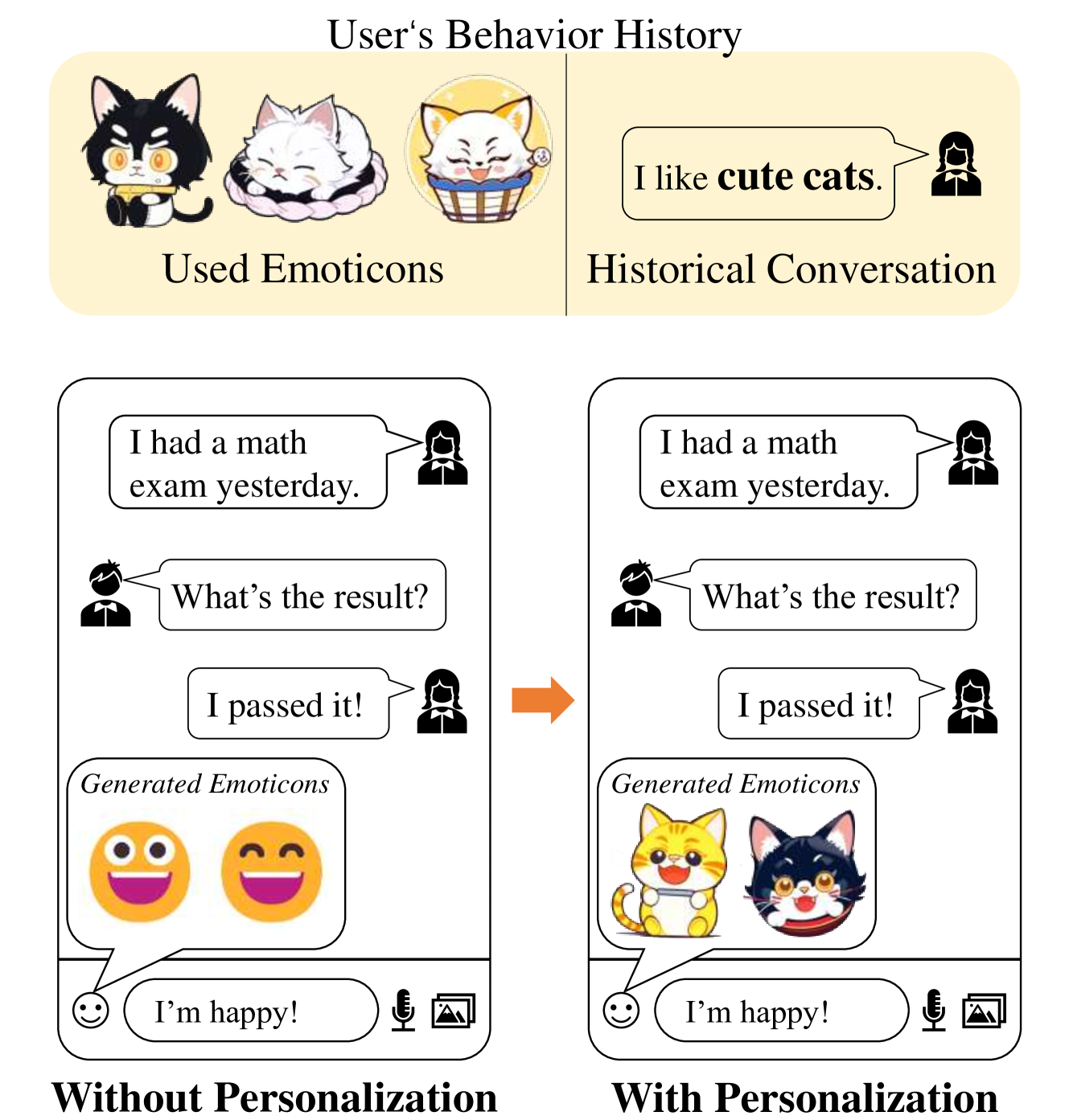
0
PMG : Personalized Multimodal Generation with Large Language Models
Xiaoteng Shen, Rui Zhang, Xiaoyan Zhao, Jieming Zhu, Xi Xiao
The emergence of large language models (LLMs) has revolutionized the capabilities of text comprehension and generation. Multi-modal generation attracts great attention from both the industry and academia, but there is little work on personalized generation, which has important applications such as recommender systems. This paper proposes the first method for personalized multimodal generation using LLMs, showcases its applications and validates its performance via an extensive experimental study on two datasets. The proposed method, Personalized Multimodal Generation (PMG for short) first converts user behaviors (e.g., clicks in recommender systems or conversations with a virtual assistant) into natural language to facilitate LLM understanding and extract user preference descriptions. Such user preferences are then fed into a generator, such as a multimodal LLM or diffusion model, to produce personalized content. To capture user preferences comprehensively and accurately, we propose to let the LLM output a combination of explicit keywords and implicit embeddings to represent user preferences. Then the combination of keywords and embeddings are used as prompts to condition the generator. We optimize a weighted sum of the accuracy and preference scores so that the generated content has a good balance between them. Compared to a baseline method without personalization, PMG has a significant improvement on personalization for up to 8% in terms of LPIPS while retaining the accuracy of generation.
Read more4/16/2024