LangCell: Language-Cell Pre-training for Cell Identity Understanding

0

Sign in to get full access
Overview
- This paper proposes a novel pre-training approach called LangCell, which aims to improve the understanding of cell identity in biological applications.
- LangCell leverages language models to learn from the textual descriptions of cells, along with their visual representations, to build a more comprehensive understanding of cell identity.
- The authors demonstrate that LangCell outperforms existing approaches on various cell classification and understanding tasks, highlighting its potential for advancing research in computational biology.
Plain English Explanation
The researchers have developed a new way to help computers better understand the identity and characteristics of different types of cells. Cells are the basic building blocks of living organisms, and understanding their identity is crucial for various biological applications, such as disease diagnosis and drug development.
Traditionally, computers have relied on visual information, like microscope images, to try to identify and classify different cell types. However, this approach has limitations, as cells can look quite similar even if they have very different functions and properties.
The researchers realized that cells are also often described in text, such as in scientific papers and databases. By combining the visual information with the textual descriptions, the researchers believe they can create a more comprehensive understanding of cell identity.
Their new pre-training approach, called LangCell, uses language models - the same type of technology that powers chatbots and language assistants - to learn from both the visual and textual data. This allows the system to build a deeper, more nuanced understanding of the various cell types and their characteristics.
Through experiments, the researchers have shown that LangCell outperforms other existing methods for tasks like cell classification and identification. This suggests that their approach could be a valuable tool for advancing research in biology and medicine, potentially leading to breakthroughs in areas like disease diagnosis and drug discovery.
Technical Explanation
The key technical innovation in this paper is the LangCell pre-training approach, which combines language models with visual representations of cells to improve the understanding of cell identity.
The authors first collect a large dataset of cell images and their corresponding textual descriptions from scientific literature and databases. They then use this data to pre-train a language model, which learns to understand the relationships between the textual descriptions and the visual characteristics of different cell types.
This pre-trained LangCell model is then fine-tuned on downstream tasks, such as cell classification and cell type identification. The authors demonstrate that this approach outperforms existing methods that rely solely on visual information or simple text-based representations.
The authors attribute the success of LangCell to its ability to capture the rich and nuanced relationships between the textual and visual representations of cells. By learning from both modalities, the model can build a more comprehensive understanding of cell identity, which translates to improved performance on a variety of biological tasks.
Critical Analysis
The authors have presented a compelling approach to leveraging language models for improving cell identity understanding. The key strengths of this work include:
- The innovative integration of language models and visual data, which allows the system to capture the complex relationships between textual descriptions and cell characteristics.
- The demonstrated performance improvements over existing methods on various cell-related tasks, suggesting the practical utility of the LangCell approach.
- The potential for LangCell to enable breakthroughs in areas like disease diagnosis and drug discovery, where a deep understanding of cell identity is crucial.
However, the authors also acknowledge some limitations and areas for future research:
- The reliance on the availability and quality of the textual data, which may vary across different biological domains and applications.
- The potential challenges in adapting the LangCell approach to handle highly specialized or domain-specific cell types and terminologies.
- The need to further investigate the interpretability and explainability of the LangCell model's decision-making process, to better understand the underlying mechanisms driving its performance.
Overall, the LangCell pre-training approach represents a significant step forward in leveraging language models for advancing cell identity understanding. As the authors suggest, continued research in this direction could lead to transformative developments in computational biology and related fields.
Conclusion
This paper presents a novel pre-training approach called LangCell, which combines language models and visual representations to improve the understanding of cell identity. By learning from both textual descriptions and cell images, the LangCell model can build a more comprehensive understanding of different cell types and their characteristics.
The authors demonstrate that LangCell outperforms existing methods on various cell-related tasks, highlighting its potential to enable breakthroughs in areas like disease diagnosis and drug discovery. While the approach has some limitations, the authors have laid the groundwork for further research and development in this exciting area of computational biology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LangCell: Language-Cell Pre-training for Cell Identity Understanding
Suyuan Zhao, Jiahuan Zhang, Yushuai Wu, Yizhen Luo, Zaiqing Nie
Cell identity encompasses various semantic aspects of a cell, including cell type, pathway information, disease information, and more, which are essential for biologists to gain insights into its biological characteristics. Understanding cell identity from the transcriptomic data, such as annotating cell types, has become an important task in bioinformatics. As these semantic aspects are determined by human experts, it is impossible for AI models to effectively carry out cell identity understanding tasks without the supervision signals provided by single-cell and label pairs. The single-cell pre-trained language models (PLMs) currently used for this task are trained only on a single modality, transcriptomics data, lack an understanding of cell identity knowledge. As a result, they have to be fine-tuned for downstream tasks and struggle when lacking labeled data with the desired semantic labels. To address this issue, we propose an innovative solution by constructing a unified representation of single-cell data and natural language during the pre-training phase, allowing the model to directly incorporate insights related to cell identity. More specifically, we introduce $textbf{LangCell}$, the first $textbf{Lang}$uage-$textbf{Cell}$ pre-training framework. LangCell utilizes texts enriched with cell identity information to gain a profound comprehension of cross-modal knowledge. Results from experiments conducted on different benchmarks show that LangCell is the only single-cell PLM that can work effectively in zero-shot cell identity understanding scenarios, and also significantly outperforms existing models in few-shot and fine-tuning cell identity understanding scenarios.
Read more6/12/2024
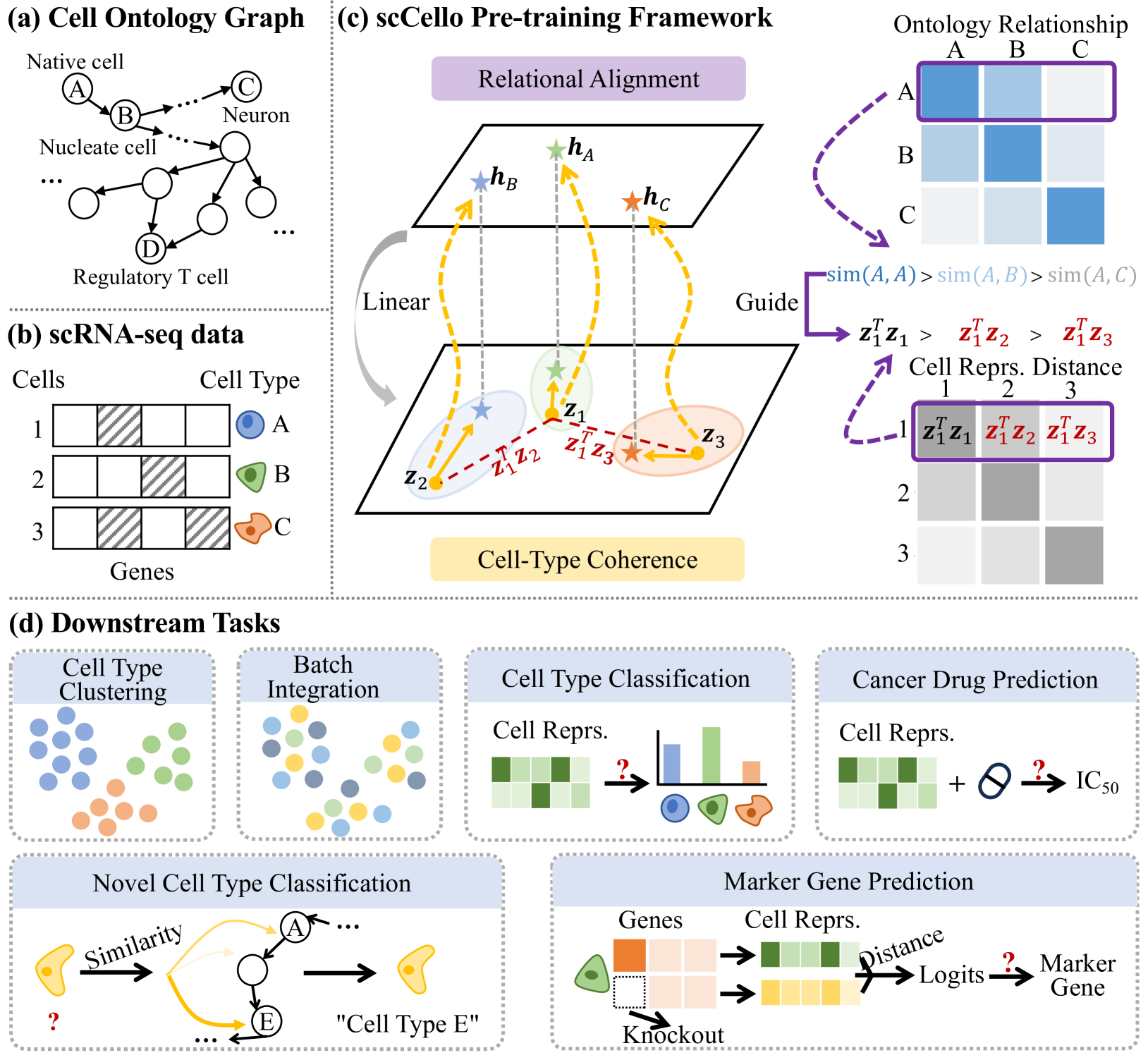
0
Cell-ontology guided transcriptome foundation model
Xinyu Yuan, Zhihao Zhan, Zuobai Zhang, Manqi Zhou, Jianan Zhao, Boyu Han, Yue Li, Jian Tang
Transcriptome foundation models TFMs hold great promises of deciphering the transcriptomic language that dictate diverse cell functions by self-supervised learning on large-scale single-cell gene expression data, and ultimately unraveling the complex mechanisms of human diseases. However, current TFMs treat cells as independent samples and ignore the taxonomic relationships between cell types, which are available in cell ontology graphs. We argue that effectively leveraging this ontology information during the TFM pre-training can improve learning biologically meaningful gene co-expression patterns while preserving TFM as a general purpose foundation model for downstream zero-shot and fine-tuning tasks. To this end, we present textbf{s}ingle textbf{c}ell, textbf{Cell}-textbf{o}ntology guided TFM scCello. We introduce cell-type coherence loss and ontology alignment loss, which are minimized along with the masked gene expression prediction loss during the pre-training. The novel loss component guide scCello to learn the cell-type-specific representation and the structural relation between cell types from the cell ontology graph, respectively. We pre-trained scCello on 22 million cells from CellxGene database leveraging their cell-type labels mapped to the cell ontology graph from Open Biological and Biomedical Ontology Foundry. Our TFM demonstrates competitive generalization and transferability performance over the existing TFMs on biologically important tasks including identifying novel cell types of unseen cells, prediction of cell-type-specific marker genes, and cancer drug responses.
Read more8/23/2024

0
Transformer-based Single-Cell Language Model: A Survey
Wei Lan, Guohang He, Mingyang Liu, Qingfeng Chen, Junyue Cao, Wei Peng
The transformers have achieved significant accomplishments in the natural language processing as its outstanding parallel processing capabilities and highly flexible attention mechanism. In addition, increasing studies based on transformers have been proposed to model single-cell data. In this review, we attempt to systematically summarize the single-cell language models and applications based on transformers. First, we provide a detailed introduction about the structure and principles of transformers. Then, we review the single-cell language models and large language models for single-cell data analysis. Moreover, we explore the datasets and applications of single-cell language models in downstream tasks such as batch correction, cell clustering, cell type annotation, gene regulatory network inference and perturbation response. Further, we discuss the challenges of single-cell language models and provide promising research directions. We hope this review will serve as an up-to-date reference for researchers interested in the direction of single-cell language models.
Read more7/19/2024

0
Harnessing the Intrinsic Knowledge of Pretrained Language Models for Challenging Text Classification Settings
Lingyu Gao
Text classification is crucial for applications such as sentiment analysis and toxic text filtering, but it still faces challenges due to the complexity and ambiguity of natural language. Recent advancements in deep learning, particularly transformer architectures and large-scale pretraining, have achieved inspiring success in NLP fields. Building on these advancements, this thesis explores three challenging settings in text classification by leveraging the intrinsic knowledge of pretrained language models (PLMs). Firstly, to address the challenge of selecting misleading yet incorrect distractors for cloze questions, we develop models that utilize features based on contextualized word representations from PLMs, achieving performance that rivals or surpasses human accuracy. Secondly, to enhance model generalization to unseen labels, we create small finetuning datasets with domain-independent task label descriptions, improving model performance and robustness. Lastly, we tackle the sensitivity of large language models to in-context learning prompts by selecting effective demonstrations, focusing on misclassified examples and resolving model ambiguity regarding test example labels.
Read more8/29/2024