Harnessing the Intrinsic Knowledge of Pretrained Language Models for Challenging Text Classification Settings

0

Sign in to get full access
Overview
- The paper explores using pretrained language models (PLMs) to improve text classification in challenging settings.
- It proposes a feature engineering approach that leverages the intrinsic knowledge captured by PLMs to select informative distractors for text classification.
- The method is evaluated on several benchmark datasets, showing performance improvements over standard classification approaches.
Plain English Explanation
Language models are AI systems that can understand and generate human-like text. These models are "pretrained" on massive amounts of text data, allowing them to capture general knowledge about language and the world.
The researchers in this paper hypothesized that the knowledge encoded in these pretrained language models could be harnessed to improve text classification - the task of automatically categorizing pieces of text into predefined classes or labels.
Text classification can be challenging in certain settings, such as when the classes are very similar or when there is limited training data available. To address these challenges, the researchers developed a new approach that uses the knowledge in pretrained language models to select "informative distractors" - words or phrases that help distinguish between the different classes.
The key idea is to leverage the language model's understanding of word meanings and relationships to identify distractors that are closely related to the target classes, but not identical to them. By incorporating these distractors as additional features, the classification model can learn to better differentiate between the classes.
The researchers tested their approach on several standard text classification benchmarks and found that it outperformed traditional classification methods. This suggests that tapping into the rich knowledge captured by pretrained language models can be a powerful way to tackle complex text classification problems.
Technical Explanation
The paper proposes a feature engineering approach that leverages the intrinsic knowledge of pretrained language models (PLMs) to improve text classification performance in challenging settings.
The core idea is to use the PLM's understanding of semantic relationships to select "informative distractors" - words or phrases that are closely related to the target classes, but not identical to them. These distractors are then used as additional features to train the classification model, helping it learn more discriminative representations.
Specifically, the method involves the following steps:
- [object Object]: For each target class, the PLM is used to identify a set of distractors - words or phrases that are semantically similar to the class but not members of the class itself.
- [object Object]: The selected distractors are incorporated as additional features in the classification model, alongside the original text.
- [object Object]: The classification model is trained on the augmented feature set and evaluated on benchmark datasets.
The researchers conducted experiments on several challenging text classification tasks, such as sentiment analysis and topic classification. Their results showed that the proposed approach consistently outperformed standard classification methods, demonstrating the benefits of leveraging the intrinsic knowledge captured by pretrained language models.
Critical Analysis
The paper presents a novel and promising approach for addressing challenging text classification problems by incorporating knowledge from pretrained language models. However, there are a few potential limitations and areas for further research:
-
[object Object]: The performance of the proposed method may be sensitive to the characteristics of the target dataset, such as the degree of class overlap and the availability of training data. Further exploration is needed to understand the method's robustness across a wider range of classification tasks and datasets.
-
[object Object]: While the method leverages the intrinsic knowledge of PLMs, the specific mechanisms by which the distractors improve classification performance are not fully explained. Investigating the interpretability of the approach could provide valuable insights and inform further improvements.
-
[object Object]: The process of selecting informative distractors may incur additional computational overhead, which could be a concern for practical deployment. Exploring ways to streamline this process or make it more efficient would be an important direction for future research.
Overall, the paper presents a compelling approach that demonstrates the potential of harnessing the rich knowledge captured by pretrained language models to tackle challenging text classification problems. Further research and refinement of the method could lead to significant advancements in this important area of natural language processing.
Conclusion
This paper introduces a novel feature engineering approach that leverages the intrinsic knowledge of pretrained language models to improve text classification performance in challenging settings. By selecting informative distractors based on the language model's understanding of semantic relationships, the method is able to augment the classification model with additional discriminative features.
The experimental results show that this approach consistently outperforms standard classification methods across a range of benchmark datasets, highlighting the benefits of tapping into the rich knowledge encoded in pretrained language models. While there are some potential limitations that warrant further investigation, this research represents an important step towards developing more robust and effective text classification systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Harnessing the Intrinsic Knowledge of Pretrained Language Models for Challenging Text Classification Settings
Lingyu Gao
Text classification is crucial for applications such as sentiment analysis and toxic text filtering, but it still faces challenges due to the complexity and ambiguity of natural language. Recent advancements in deep learning, particularly transformer architectures and large-scale pretraining, have achieved inspiring success in NLP fields. Building on these advancements, this thesis explores three challenging settings in text classification by leveraging the intrinsic knowledge of pretrained language models (PLMs). Firstly, to address the challenge of selecting misleading yet incorrect distractors for cloze questions, we develop models that utilize features based on contextualized word representations from PLMs, achieving performance that rivals or surpasses human accuracy. Secondly, to enhance model generalization to unseen labels, we create small finetuning datasets with domain-independent task label descriptions, improving model performance and robustness. Lastly, we tackle the sensitivity of large language models to in-context learning prompts by selecting effective demonstrations, focusing on misclassified examples and resolving model ambiguity regarding test example labels.
Read more8/29/2024
0
Language Models for Text Classification: Is In-Context Learning Enough?
Aleksandra Edwards, Jose Camacho-Collados
Recent foundational language models have shown state-of-the-art performance in many NLP tasks in zero- and few-shot settings. An advantage of these models over more standard approaches based on fine-tuning is the ability to understand instructions written in natural language (prompts), which helps them generalise better to different tasks and domains without the need for specific training data. This makes them suitable for addressing text classification problems for domains with limited amounts of annotated instances. However, existing research is limited in scale and lacks understanding of how text generation models combined with prompting techniques compare to more established methods for text classification such as fine-tuning masked language models. In this paper, we address this research gap by performing a large-scale evaluation study for 16 text classification datasets covering binary, multiclass, and multilabel problems. In particular, we compare zero- and few-shot approaches of large language models to fine-tuning smaller language models. We also analyse the results by prompt, classification type, domain, and number of labels. In general, the results show how fine-tuning smaller and more efficient language models can still outperform few-shot approaches of larger language models, which have room for improvement when it comes to text classification.
Read more4/16/2024
📶
0
Beyond Turing: A Comparative Analysis of Approaches for Detecting Machine-Generated Text
Muhammad Farid Adilazuarda
Significant progress has been made on text generation by pre-trained language models (PLMs), yet distinguishing between human and machine-generated text poses an escalating challenge. This paper offers an in-depth evaluation of three distinct methods used to address this task: traditional shallow learning, Language Model (LM) fine-tuning, and Multilingual Model fine-tuning. These approaches are rigorously tested on a wide range of machine-generated texts, providing a benchmark of their competence in distinguishing between human-authored and machine-authored linguistic constructs. The results reveal considerable differences in performance across methods, thus emphasizing the continued need for advancement in this crucial area of NLP. This study offers valuable insights and paves the way for future research aimed at creating robust and highly discriminative models.
Read more5/16/2024
0
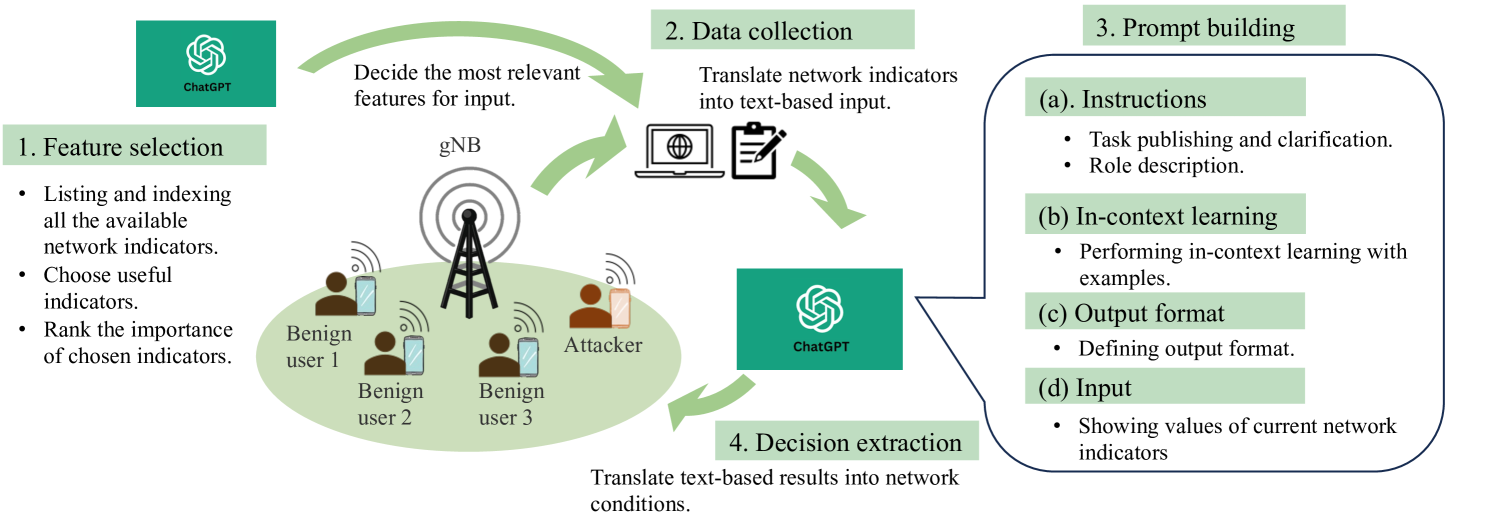
Large Language Models in Wireless Application Design: In-Context Learning-enhanced Automatic Network Intrusion Detection
Han Zhang, Akram Bin Sediq, Ali Afana, Melike Erol-Kantarci
Large language models (LLMs), especially generative pre-trained transformers (GPTs), have recently demonstrated outstanding ability in information comprehension and problem-solving. This has motivated many studies in applying LLMs to wireless communication networks. In this paper, we propose a pre-trained LLM-empowered framework to perform fully automatic network intrusion detection. Three in-context learning methods are designed and compared to enhance the performance of LLMs. With experiments on a real network intrusion detection dataset, in-context learning proves to be highly beneficial in improving the task processing performance in a way that no further training or fine-tuning of LLMs is required. We show that for GPT-4, testing accuracy and F1-Score can be improved by 90%. Moreover, pre-trained LLMs demonstrate big potential in performing wireless communication-related tasks. Specifically, the proposed framework can reach an accuracy and F1-Score of over 95% on different types of attacks with GPT-4 using only 10 in-context learning examples.
Read more5/21/2024