Language Augmentation in CLIP for Improved Anatomy Detection on Multi-modal Medical Images
2405.20735
0
0

Abstract
Vision-language models have emerged as a powerful tool for previously challenging multi-modal classification problem in the medical domain. This development has led to the exploration of automated image description generation for multi-modal clinical scans, particularly for radiology report generation. Existing research has focused on clinical descriptions for specific modalities or body regions, leaving a gap for a model providing entire-body multi-modal descriptions. In this paper, we address this gap by automating the generation of standardized body station(s) and list of organ(s) across the whole body in multi-modal MR and CT radiological images. Leveraging the versatility of the Contrastive Language-Image Pre-training (CLIP), we refine and augment the existing approach through multiple experiments, including baseline model fine-tuning, adding station(s) as a superset for better correlation between organs, along with image and language augmentations. Our proposed approach demonstrates 47.6% performance improvement over baseline PubMedCLIP.
Create account to get full access
Overview
- This paper explores using language augmentation techniques to improve the performance of the Contrastive Language-Image Pre-training (CLIP) model on medical image analysis tasks, specifically anatomy detection.
- The researchers investigate how incorporating additional language data and prompting strategies can enhance CLIP's ability to locate and identify anatomical structures in multi-modal medical images.
- The proposed approach aims to address the challenge of limited training data in the medical domain by leveraging the rich language information available on the internet to better ground CLIP's visual understanding.
Plain English Explanation
The paper is focused on improving a machine learning model called CLIP, which is trained to understand the relationship between images and the language used to describe them. The researchers wanted to see if they could make CLIP better at detecting and identifying different anatomical structures in medical images, like X-rays or MRI scans.
One of the challenges in medical image analysis is that there is often not enough labeled training data available, since annotating these types of images can be time-consuming and expensive. To address this, the researchers explored using additional language data from the internet to help CLIP learn more about anatomy and how it is described.
By incorporating more language information and using different prompting strategies when training CLIP, the researchers found that they could improve the model's performance on tasks like locating specific organs or body parts in medical images. This suggests that leveraging language data could be a valuable approach for enhancing the capabilities of AI systems in the medical imaging domain, where training data can be scarce.
Technical Explanation
The paper presents a approach to augment the language capabilities of CLIP for improved anatomy detection on multi-modal medical images. CLIP is a popular vision-language model that has shown strong zero-shot transfer capabilities, but the authors hypothesize that its performance on specialized medical imaging tasks can be further enhanced through targeted language augmentation.
The key components of the proposed method include:
- Expanding the textual corpus used to train CLIP with additional medical-specific language data, such as anatomy descriptions, medical ontologies, and scientific literature.
- Designing prompting strategies to better ground CLIP's visual understanding of anatomical structures, leveraging techniques like prompt engineering and compositional prompts.
- Fine-tuning the augmented CLIP model on medical image datasets to evaluate its performance on anatomy detection tasks.
The authors conduct experiments on several multi-modal medical image benchmarks and demonstrate that their language-augmented CLIP approach can outperform the standard CLIP model, as well as other state-of-the-art anatomy detection methods. The results highlight the potential of leveraging rich language data to enhance the capabilities of vision-language models in specialized domains like healthcare.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear motivation and robust experimental evaluation. The authors have done a commendable job of leveraging existing language resources to improve CLIP's performance on medical imaging tasks, which is an important problem given the data scarcity in this domain.
However, the paper does acknowledge several limitations and avenues for future work. For instance, the language augmentation is primarily focused on textual data, and the authors note that incorporating other modalities like medical reports or clinical notes could further boost performance. Additionally, the proposed approach has been evaluated on a limited set of datasets and medical imaging tasks, so its generalizability to a broader range of applications remains to be seen.
Future research could also investigate more advanced prompting strategies, such as visually-grounded prompts or task-specific prompt tuning, to better capture the nuances of medical language and visual concepts. Exploring the transferability of the language-augmented CLIP model to other healthcare-related tasks, such as disease diagnosis or treatment planning, would also be a valuable line of inquiry.
Conclusion
The presented research demonstrates the potential of leveraging language augmentation to enhance the performance of vision-language models like CLIP on medical imaging tasks. By incorporating additional textual data and employing targeted prompting strategies, the authors were able to improve CLIP's ability to detect and identify anatomical structures in multi-modal medical images.
This work highlights the value of integrating rich language information to address the data scarcity challenges in the medical domain, and the findings suggest that further advancements in this direction could lead to more robust and capable AI systems for healthcare applications. As the field of vision-language models continues to evolve, the lessons learned from this study can inform future efforts to bridge the gap between medical imaging and natural language understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CT-GLIP: 3D Grounded Language-Image Pretraining with CT Scans and Radiology Reports for Full-Body Scenarios
Jingyang Lin, Yingda Xia, Jianpeng Zhang, Ke Yan, Le Lu, Jiebo Luo, Ling Zhang
0
0
Medical Vision-Language Pretraining (Med-VLP) establishes a connection between visual content from medical images and the relevant textual descriptions. Existing Med-VLP methods primarily focus on 2D images depicting a single body part, notably chest X-rays. In this paper, we extend the scope of Med-VLP to encompass 3D images, specifically targeting full-body scenarios, by using a multimodal dataset of CT images and reports. Compared with the 2D counterpart, 3D VLP is required to effectively capture essential semantics from significantly sparser representation in 3D imaging. In this paper, we introduce CT-GLIP (Grounded Language-Image Pretraining with CT scans), a novel method that constructs organ-level image-text pairs to enhance multimodal contrastive learning, aligning grounded visual features with precise diagnostic text. Additionally, we developed an abnormality dictionary to augment contrastive learning with diverse contrastive pairs. Our method, trained on a multimodal CT dataset comprising 44,011 organ-level vision-text pairs from 17,702 patients across 104 organs, demonstrates it can identify organs and abnormalities in a zero-shot manner using natural languages. The performance of CT-GLIP is validated on a separate test set of 1,130 patients, focusing on the 16 most frequent abnormalities across 7 organs. The experimental results show our model's superior performance over the standard CLIP framework across zero-shot and fine-tuning scenarios, using both CNN and ViT architectures.
4/30/2024

CLIP in Medical Imaging: A Comprehensive Survey
Zihao Zhao, Yuxiao Liu, Han Wu, Yonghao Li, Sheng Wang, Lin Teng, Disheng Liu, Zhiming Cui, Qian Wang, Dinggang Shen
0
0
Contrastive Language-Image Pre-training (CLIP), a simple yet effective pre-training paradigm, successfully introduces text supervision to vision models. It has shown promising results across various tasks, attributable to its generalizability and interpretability. The use of CLIP has recently gained increasing interest in the medical imaging domain, serving both as a pre-training paradigm for aligning medical vision and language, and as a critical component in diverse clinical tasks. With the aim of facilitating a deeper understanding of this promising direction, this survey offers an in-depth exploration of the CLIP paradigm within the domain of medical imaging, regarding both refined CLIP pre-training and CLIP-driven applications. In this study, We (1) start with a brief introduction to the fundamentals of CLIP methodology. (2) Then, we investigate the adaptation of CLIP pre-training in the medical domain, focusing on how to optimize CLIP given characteristics of medical images and reports. (3) Furthermore, we explore the practical utilization of CLIP pre-trained models in various tasks, including classification, dense prediction, and cross-modal tasks. (4) Finally, we discuss existing limitations of CLIP in the context of medical imaging and propose forward-looking directions to address the demands of medical imaging domain. We expect that this comprehensive survey will provide researchers in the field of medical image analysis with a holistic understanding of the CLIP paradigm and its potential implications. The project page can be found on https://github.com/zhaozh10/Awesome-CLIP-in-Medical-Imaging.
5/22/2024
👀
Mammo-CLIP: A Vision Language Foundation Model to Enhance Data Efficiency and Robustness in Mammography
Shantanu Ghosh, Clare B. Poynton, Shyam Visweswaran, Kayhan Batmanghelich
0
0
The lack of large and diverse training data on Computer-Aided Diagnosis (CAD) in breast cancer detection has been one of the concerns that impedes the adoption of the system. Recently, pre-training with large-scale image text datasets via Vision-Language models (VLM) (eg CLIP) partially addresses the issue of robustness and data efficiency in computer vision (CV). This paper proposes Mammo-CLIP, the first VLM pre-trained on a substantial amount of screening mammogram-report pairs, addressing the challenges of dataset diversity and size. Our experiments on two public datasets demonstrate strong performance in classifying and localizing various mammographic attributes crucial for breast cancer detection, showcasing data efficiency and robustness similar to CLIP in CV. We also propose Mammo-FActOR, a novel feature attribution method, to provide spatial interpretation of representation with sentence-level granularity within mammography reports. Code is available publicly: url{https://github.com/batmanlab/Mammo-CLIP}.
5/24/2024
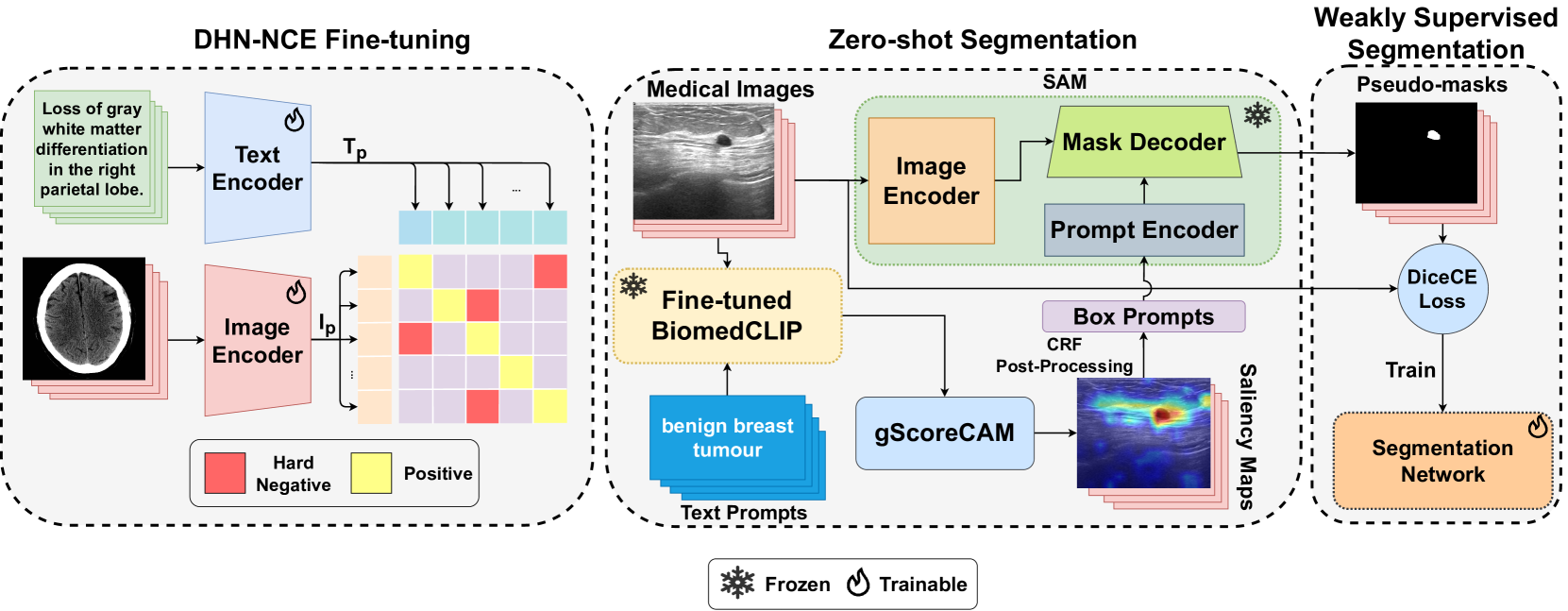
MedCLIP-SAM: Bridging Text and Image Towards Universal Medical Image Segmentation
Taha Koleilat, Hojat Asgariandehkordi, Hassan Rivaz, Yiming Xiao
0
0
Medical image segmentation of anatomical structures and pathology is crucial in modern clinical diagnosis, disease study, and treatment planning. To date, great progress has been made in deep learning-based segmentation techniques, but most methods still lack data efficiency, generalizability, and interactability. Consequently, the development of new, precise segmentation methods that demand fewer labeled datasets is of utmost importance in medical image analysis. Recently, the emergence of foundation models, such as CLIP and Segment-Anything-Model (SAM), with comprehensive cross-domain representation opened the door for interactive and universal image segmentation. However, exploration of these models for data-efficient medical image segmentation is still limited, but is highly necessary. In this paper, we propose a novel framework, called MedCLIP-SAM that combines CLIP and SAM models to generate segmentation of clinical scans using text prompts in both zero-shot and weakly supervised settings. To achieve this, we employed a new Decoupled Hard Negative Noise Contrastive Estimation (DHN-NCE) loss to fine-tune the BiomedCLIP model and the recent gScoreCAM to generate prompts to obtain segmentation masks from SAM in a zero-shot setting. Additionally, we explored the use of zero-shot segmentation labels in a weakly supervised paradigm to improve the segmentation quality further. By extensively testing three diverse segmentation tasks and medical image modalities (breast tumor ultrasound, brain tumor MRI, and lung X-ray), our proposed framework has demonstrated excellent accuracy. Code is available at https://github.com/HealthX-Lab/MedCLIP-SAM.
6/21/2024