Mammo-CLIP: A Vision Language Foundation Model to Enhance Data Efficiency and Robustness in Mammography
2405.12255
0
0
👀
Abstract
The lack of large and diverse training data on Computer-Aided Diagnosis (CAD) in breast cancer detection has been one of the concerns that impedes the adoption of the system. Recently, pre-training with large-scale image text datasets via Vision-Language models (VLM) (eg CLIP) partially addresses the issue of robustness and data efficiency in computer vision (CV). This paper proposes Mammo-CLIP, the first VLM pre-trained on a substantial amount of screening mammogram-report pairs, addressing the challenges of dataset diversity and size. Our experiments on two public datasets demonstrate strong performance in classifying and localizing various mammographic attributes crucial for breast cancer detection, showcasing data efficiency and robustness similar to CLIP in CV. We also propose Mammo-FActOR, a novel feature attribution method, to provide spatial interpretation of representation with sentence-level granularity within mammography reports. Code is available publicly: url{https://github.com/batmanlab/Mammo-CLIP}.
Create account to get full access
Overview
- Addresses the lack of large and diverse training data for Computer-Aided Diagnosis (CAD) in breast cancer detection
- Proposes Mammo-CLIP, a Vision-Language Model (VLM) pre-trained on mammogram-report pairs to improve robustness and data efficiency
- Introduces Mammo-FActOR, a feature attribution method to provide spatial interpretation of representations within mammography reports
Plain English Explanation
The paper focuses on a common challenge in the field of computer-aided breast cancer detection - the lack of large and diverse datasets for training these systems. This can make the models less accurate and reliable. To address this, the researchers developed a new approach called Mammo-CLIP, which is a type of Vision-Language Model (VLM) that is pre-trained on a large collection of mammogram images paired with their associated medical reports.
This pre-training helps the model learn general visual and language patterns that can then be applied to the task of breast cancer detection, even with limited training data. The researchers show that Mammo-CLIP performs well on classifying and localizing various mammographic features crucial for cancer detection, just like how the popular CLIP model has been successful in other computer vision tasks.
Additionally, the paper introduces a new interpretation tool called Mammo-FActOR, which can provide detailed explanations for the model's decisions by linking specific parts of the mammogram image to the relevant text in the medical report. This can help clinicians better understand how the model is making its predictions.
Technical Explanation
The paper proposes Mammo-CLIP, a Vision-Language Model (VLM) pre-trained on a large dataset of screening mammogram images paired with their corresponding medical reports. This addresses the challenge of limited and unrepresentative training data that has hindered the adoption of Computer-Aided Diagnosis (CAD) systems for breast cancer detection.
The researchers leveraged the CLIP model, a successful VLM pre-trained on a large corpus of image-text pairs, as a starting point. They then further pre-trained this model on a substantial amount of mammogram-report pairs, a dataset they call Mammo-CLIP.
Through experiments on two public breast cancer datasets, the authors demonstrate that Mammo-CLIP exhibits strong performance in classifying and localizing various mammographic attributes crucial for breast cancer detection. This showcases the data efficiency and robustness of the approach, similar to what has been observed with CLIP in other computer vision tasks.
Additionally, the paper introduces Mammo-FActOR, a novel feature attribution method that can provide spatial interpretation of the model's representations with sentence-level granularity within the mammography reports. This allows for better understanding of the model's decision-making process.
Critical Analysis
The paper addresses an important challenge in the adoption of Computer-Aided Diagnosis (CAD) systems for breast cancer detection - the lack of large and diverse training datasets. By leveraging Vision-Language Models (VLMs) and pre-training on mammogram-report pairs, the researchers have demonstrated a promising approach to improve the robustness and data efficiency of these systems.
One potential limitation is the reliance on the availability of high-quality pairs of mammogram images and corresponding medical reports. The quality and consistency of these report annotations may vary, which could impact the model's performance. Additionally, the study was conducted on public datasets, and further evaluation on more diverse, real-world clinical data would be valuable to assess the generalizability of the approach.
The introduction of Mammo-FActOR, the feature attribution method, is an interesting contribution that can help provide interpretability and transparency for the model's decision-making. However, its practical utility in a clinical setting would need to be further validated through user studies and feedback from medical professionals.
Overall, the paper presents a compelling approach to address a critical challenge in the field of computer-aided breast cancer detection. The MediCLIP and RemoteCLIP models have also explored similar ideas of adapting CLIP for medical imaging applications, and it would be interesting to see how Mammo-CLIP compares in terms of performance and generalizability.
Conclusion
The Mammo-CLIP paper addresses a key challenge in the adoption of Computer-Aided Diagnosis (CAD) systems for breast cancer detection - the lack of large and diverse training datasets. By leveraging Vision-Language Models (VLMs) and pre-training on mammogram-report pairs, the researchers have demonstrated a promising approach to improve the robustness and data efficiency of these systems.
The introduction of Mammo-FActOR, a novel feature attribution method, also provides a way to improve the interpretability of the model's decision-making process. While further evaluation on more diverse, real-world clinical data would be valuable, this work represents an important step towards more reliable and transparent computer-aided breast cancer detection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CLIP in Medical Imaging: A Comprehensive Survey
Zihao Zhao, Yuxiao Liu, Han Wu, Yonghao Li, Sheng Wang, Lin Teng, Disheng Liu, Zhiming Cui, Qian Wang, Dinggang Shen
0
0
Contrastive Language-Image Pre-training (CLIP), a simple yet effective pre-training paradigm, successfully introduces text supervision to vision models. It has shown promising results across various tasks, attributable to its generalizability and interpretability. The use of CLIP has recently gained increasing interest in the medical imaging domain, serving both as a pre-training paradigm for aligning medical vision and language, and as a critical component in diverse clinical tasks. With the aim of facilitating a deeper understanding of this promising direction, this survey offers an in-depth exploration of the CLIP paradigm within the domain of medical imaging, regarding both refined CLIP pre-training and CLIP-driven applications. In this study, We (1) start with a brief introduction to the fundamentals of CLIP methodology. (2) Then, we investigate the adaptation of CLIP pre-training in the medical domain, focusing on how to optimize CLIP given characteristics of medical images and reports. (3) Furthermore, we explore the practical utilization of CLIP pre-trained models in various tasks, including classification, dense prediction, and cross-modal tasks. (4) Finally, we discuss existing limitations of CLIP in the context of medical imaging and propose forward-looking directions to address the demands of medical imaging domain. We expect that this comprehensive survey will provide researchers in the field of medical image analysis with a holistic understanding of the CLIP paradigm and its potential implications. The project page can be found on https://github.com/zhaozh10/Awesome-CLIP-in-Medical-Imaging.
5/22/2024
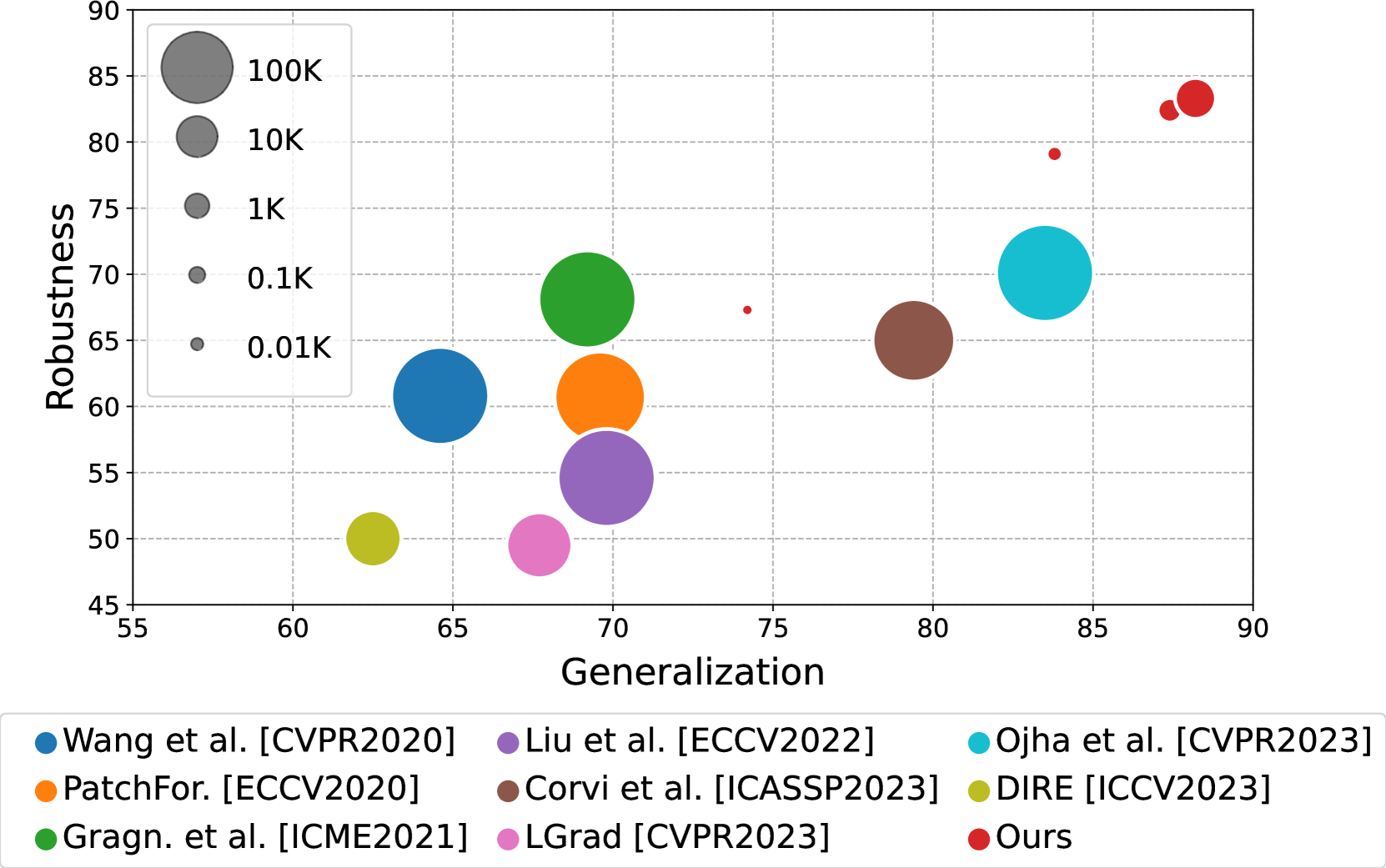
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
0
0
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
4/30/2024
Knowledge-grounded Adaptation Strategy for Vision-language Models: Building Unique Case-set for Screening Mammograms for Residents Training
Aisha Urooj Khan, John Garrett, Tyler Bradshaw, Lonie Salkowski, Jiwoong Jason Jeong, Amara Tariq, Imon Banerjee
0
0
A visual-language model (VLM) pre-trained on natural images and text pairs poses a significant barrier when applied to medical contexts due to domain shift. Yet, adapting or fine-tuning these VLMs for medical use presents considerable hurdles, including domain misalignment, limited access to extensive datasets, and high-class imbalances. Hence, there is a pressing need for strategies to effectively adapt these VLMs to the medical domain, as such adaptations would prove immensely valuable in healthcare applications. In this study, we propose a framework designed to adeptly tailor VLMs to the medical domain, employing selective sampling and hard-negative mining techniques for enhanced performance in retrieval tasks. We validate the efficacy of our proposed approach by implementing it across two distinct VLMs: the in-domain VLM (MedCLIP) and out-of-domain VLMs (ALBEF). We assess the performance of these models both in their original off-the-shelf state and after undergoing our proposed training strategies, using two extensive datasets containing mammograms and their corresponding reports. Our evaluation spans zero-shot, few-shot, and supervised scenarios. Through our approach, we observe a notable enhancement in Recall@K performance for the image-text retrieval task.
5/31/2024

Language Augmentation in CLIP for Improved Anatomy Detection on Multi-modal Medical Images
Mansi Kakkar, Dattesh Shanbhag, Chandan Aladahalli, Gurunath Reddy M
0
0
Vision-language models have emerged as a powerful tool for previously challenging multi-modal classification problem in the medical domain. This development has led to the exploration of automated image description generation for multi-modal clinical scans, particularly for radiology report generation. Existing research has focused on clinical descriptions for specific modalities or body regions, leaving a gap for a model providing entire-body multi-modal descriptions. In this paper, we address this gap by automating the generation of standardized body station(s) and list of organ(s) across the whole body in multi-modal MR and CT radiological images. Leveraging the versatility of the Contrastive Language-Image Pre-training (CLIP), we refine and augment the existing approach through multiple experiments, including baseline model fine-tuning, adding station(s) as a superset for better correlation between organs, along with image and language augmentations. Our proposed approach demonstrates 47.6% performance improvement over baseline PubMedCLIP.
6/3/2024