Language-Driven Interactive Shadow Detection

0

Sign in to get full access
Overview
- This paper proposes a method for interactive shadow detection in video, where users can provide language-based descriptions to guide the detection process.
- The approach combines computer vision and natural language processing techniques to enable intuitive, language-driven control over shadow segmentation.
- The authors introduce a new dataset of video segments with language annotations for shadow regions, which they use to train and evaluate their model.
Plain English Explanation
The researchers have developed a system that allows users to detect shadows in videos using language-based instructions. Rather than relying solely on automated computer vision algorithms, this approach gives users the ability to guide the shadow detection process by describing the shadows they want to find.
By combining language processing and computer vision techniques, the researchers have created a model that can understand natural language descriptions of shadows and use that information to accurately segment the corresponding shadow regions in the video. This language-driven interactive shadow detection approach is more intuitive and flexible than fully automatic shadow detection methods, as it allows users to customize the results to their specific needs.
To train and test their system, the researchers created a new dataset of video clips with language annotations describing the shadow regions. This dataset provides the necessary data to teach the model how to interpret language input and translate it into accurate shadow segmentation in the corresponding videos.
Technical Explanation
The core of the researchers' approach is a deep learning model that can take in both visual and language inputs to detect shadows in video frames. The visual input is the video itself, while the language input is a natural language description of the shadows the user wants to find.
The model consists of several key components:
- A vision encoder that processes the video frames and extracts visual features
- A language encoder that understands the meaning of the user's shadow description
- A shadow segmentation module that combines the visual and language features to produce a segmentation mask highlighting the relevant shadow regions
- An adaptive attention mechanism that dynamically focuses the model's attention on the most informative parts of the video and language inputs
The researchers train and evaluate their model using the new dataset of video clips with language-annotated shadow regions. Their experiments demonstrate that the language-driven interactive approach outperforms fully automatic shadow detection methods, as the user's language input allows the model to better understand and localize the desired shadows.
Critical Analysis
One limitation of the proposed approach is that it relies on the availability of a dataset with high-quality language annotations for shadow regions in videos. Collecting and annotating such a dataset is a labor-intensive process, which could limit the scalability of the method.
Additionally, the model's performance may be influenced by the specificity and clarity of the user's language input. Vague or ambiguous shadow descriptions could lead to less accurate segmentation results. Further research may be needed to improve the model's robustness to variations in language input.
While the authors demonstrate the effectiveness of their language-driven interactive approach, they do not explore potential negative societal impacts, such as how the technology could be misused or lead to unintended consequences. A more thorough discussion of ethical considerations would be valuable.
Conclusion
This paper presents a novel approach to shadow detection in videos that allows users to guide the process using natural language descriptions. By combining computer vision and natural language processing techniques, the researchers have developed a system that is more intuitive and customizable than fully automatic shadow detection methods.
The introduced dataset and language-driven interactive model represent an important step forward in making computer vision more accessible and user-friendly. This technology could have applications in various domains, such as video editing, surveillance, and scene understanding. However, future research should also consider the potential societal implications of such language-based computer vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Language-Driven Interactive Shadow Detection
Hongqiu Wang, Wei Wang, Haipeng Zhou, Huihui Xu, Shaozhi Wu, Lei Zhu
Traditional shadow detectors often identify all shadow regions of static images or video sequences. This work presents the Referring Video Shadow Detection (RVSD), which is an innovative task that rejuvenates the classic paradigm by facilitating the segmentation of particular shadows in videos based on descriptive natural language prompts. This novel RVSD not only achieves segmentation of arbitrary shadow areas of interest based on descriptions (flexibility) but also allows users to interact with visual content more directly and naturally by using natural language prompts (interactivity), paving the way for abundant applications ranging from advanced video editing to virtual reality experiences. To pioneer the RVSD research, we curated a well-annotated RVSD dataset, which encompasses 86 videos and a rich set of 15,011 paired textual descriptions with corresponding shadows. To the best of our knowledge, this dataset is the first one for addressing RVSD. Based on this dataset, we propose a Referring Shadow-Track Memory Network (RSM-Net) for addressing the RVSD task. In our RSM-Net, we devise a Twin-Track Synergistic Memory (TSM) to store intra-clip memory features and hierarchical inter-clip memory features, and then pass these memory features into a memory read module to refine features of the current video frame for referring shadow detection. We also develop a Mixed-Prior Shadow Attention (MSA) to utilize physical priors to obtain a coarse shadow map for learning more visual features by weighting it with the input video frame. Experimental results show that our RSM-Net achieves state-of-the-art performance for RVSD with a notable Overall IOU increase of 4.4%. Our code and dataset are available at https://github.com/whq-xxh/RVSD.
Read more8/19/2024
🔎
0
Video Instance Shadow Detection
Zhenghao Xing, Tianyu Wang, Xiaowei Hu, Haoran Wu, Chi-Wing Fu, Pheng-Ann Heng
Instance shadow detection, crucial for applications such as photo editing and light direction estimation, has undergone significant advancements in predicting shadow instances, object instances, and their associations. The extension of this task to videos presents challenges in annotating diverse video data and addressing complexities arising from occlusion and temporary disappearances within associations. In response to these challenges, we introduce ViShadow, a semi-supervised video instance shadow detection framework that leverages both labeled image data and unlabeled video data for training. ViShadow features a two-stage training pipeline: the first stage, utilizing labeled image data, identifies shadow and object instances through contrastive learning for cross-frame pairing. The second stage employs unlabeled videos, incorporating an associated cycle consistency loss to enhance tracking ability. A retrieval mechanism is introduced to manage temporary disappearances, ensuring tracking continuity. The SOBA-VID dataset, comprising unlabeled training videos and labeled testing videos, along with the SOAP-VID metric, is introduced for the quantitative evaluation of VISD solutions. The effectiveness of ViShadow is further demonstrated through various video-level applications such as video inpainting, instance cloning, shadow editing, and text-instructed shadow-object manipulation.
Read more5/7/2024

0
Timeline and Boundary Guided Diffusion Network for Video Shadow Detection
Haipeng Zhou, Honqiu Wang, Tian Ye, Zhaohu Xing, Jun Ma, Ping Li, Qiong Wang, Lei Zhu
Video Shadow Detection (VSD) aims to detect the shadow masks with frame sequence. Existing works suffer from inefficient temporal learning. Moreover, few works address the VSD problem by considering the characteristic (i.e., boundary) of shadow. Motivated by this, we propose a Timeline and Boundary Guided Diffusion (TBGDiff) network for VSD where we take account of the past-future temporal guidance and boundary information jointly. In detail, we design a Dual Scale Aggregation (DSA) module for better temporal understanding by rethinking the affinity of the long-term and short-term frames for the clipped video. Next, we introduce Shadow Boundary Aware Attention (SBAA) to utilize the edge contexts for capturing the characteristics of shadows. Moreover, we are the first to introduce the Diffusion model for VSD in which we explore a Space-Time Encoded Embedding (STEE) to inject the temporal guidance for Diffusion to conduct shadow detection. Benefiting from these designs, our model can not only capture the temporal information but also the shadow property. Extensive experiments show that the performance of our approach overtakes the state-of-the-art methods, verifying the effectiveness of our components. We release the codes, weights, and results at url{https://github.com/haipengzhou856/TBGDiff}.
Read more8/22/2024
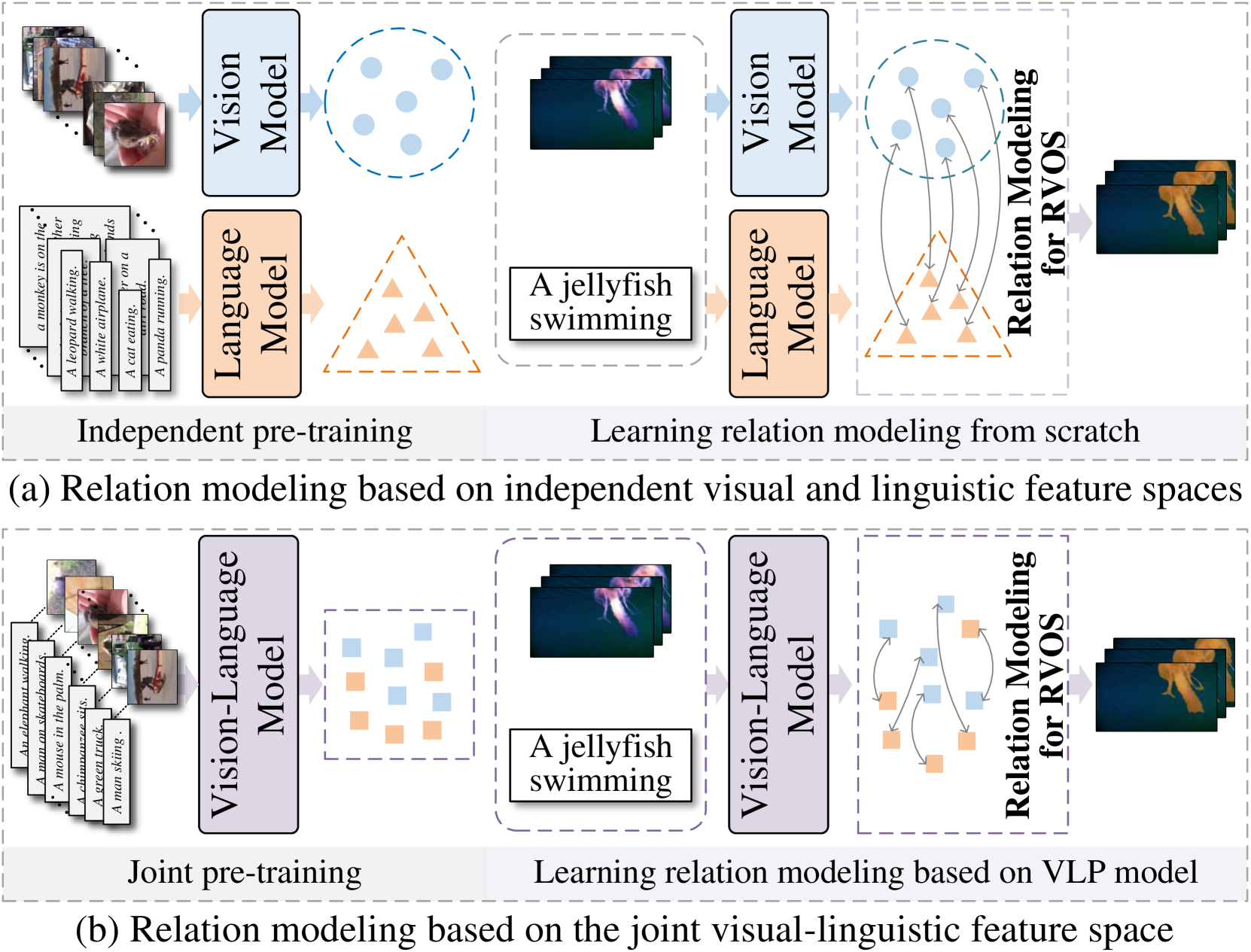
0
Driving Referring Video Object Segmentation with Vision-Language Pre-trained Models
Zikun Zhou, Wentao Xiong, Li Zhou, Xin Li, Zhenyu He, Yaowei Wang
The crux of Referring Video Object Segmentation (RVOS) lies in modeling dense text-video relations to associate abstract linguistic concepts with dynamic visual contents at pixel-level. Current RVOS methods typically use vision and language models pre-trained independently as backbones. As images and texts are mapped to uncoupled feature spaces, they face the arduous task of learning Vision-Language~(VL) relation modeling from scratch. Witnessing the success of Vision-Language Pre-trained (VLP) models, we propose to learn relation modeling for RVOS based on their aligned VL feature space. Nevertheless, transferring VLP models to RVOS is a deceptively challenging task due to the substantial gap between the pre-training task (image/region-level prediction) and the RVOS task (pixel-level prediction in videos). In this work, we introduce a framework named VLP-RVOS to address this transfer challenge. We first propose a temporal-aware prompt-tuning method, which not only adapts pre-trained representations for pixel-level prediction but also empowers the vision encoder to model temporal clues. We further propose to perform multi-stage VL relation modeling while and after feature extraction for comprehensive VL understanding. Besides, we customize a cube-frame attention mechanism for spatial-temporal reasoning. Extensive experiments demonstrate that our method outperforms state-of-the-art algorithms and exhibits strong generalization abilities.
Read more5/20/2024